
Chapter 22. Parser Combinator by Rebecca Parsons
Create a top-down parser by a composition of parser objects.
Even though our premise is that Parser Generators are not nearly as difficult to work with as they are perceived to be, there are legitimate reasons to avoid them if possible. The most obvious issue is the additional steps in the build process required to first generate the parser and then build it. While Parser Generators are still the right choice for more complex context-free grammars, particularly if the grammar is ambiguous or performance is crucial, directly implementing a parser in a general-purpose language is a viable option.
A Parser Combinator implements a grammar using a structure of parser objects. Recognizers for the symbols in the production rules are combined using Composites [GoF], which are referred to as combinators. Effectively, parser combinators represent a Semantic Model of a grammar.
22.1 How It Works
As with Recursive Descent Parser, we use a lexer, for example a Regex Table Lexer, to perform the lexical analysis of the input string. Our Parser Combinator then operates on the resulting token string.
The basic idea behind parser combinators is simple. The term “combinator” comes from functional languages. Combinators are designed to be composed to create more complex operations of the same type as their input. So, parser combinators are combined to make more complex parser combinators. In functional languages, these combinators are first-class functions, but we can do the same with objects in an object-oriented environment. We start with the base cases, which are the recognizers for the terminal symbols in our grammar. We then use the combinators that implement the various grammar operators (such as sequence, list, etc.) to implement the production rules in the grammar. Effectively, for each nonterminal in our grammar, we have a combinator for it, just like in Recursive Descent Parser we have a recursive function for each nonterminal.
Each combinator is responsible for recognizing some portion of the language, determining if there is a match, consuming the relevant tokens from the input buffer for the match, and performing the required actions. These operations are the same as those required by the recursive functions in Recursive Descent Parser. For the recognizer portion of the implementations of various grammar operators below, the same logic that we used in the recursive descent implementation applies. What’s really happening here is that we abstract out the fragments of logic associated with processing the grammar operators for top-down parsing and create the combinators to hold that logic. While a Recursive Descent Parser combines those fragments with function calls in inline code, a Parser Combinator combines these by linking together objects in an Adaptive Model.
Individual parser combinators accept as input the status of the match so far, the current token buffer, and possibly a set of accumulated action results. Parser combinators return a match status, a possibly altered token buffer, and a set of action results. To make the description easier, assume for the moment that the token buffer and the set of match results are kept as state in the background somewhere. We’ll change that later, but this assumption makes the combinator logic easier to follow. Also, we’ll concentrate first on describing the recognition logic, and then return to dealing with actions.
Let’s first consider a recognizer for a terminal symbol—our base case. The actual recognition of a terminal symbol is easy; we simply compare the token at the current position in the input token buffer to whatever terminal symbol, represented by a token, the recognizer is for. If the token matches, we advance the current position in the token buffer.
Now, let’s look at the basics behind the combinators for the various grammar operators. We’ll start with the alternative operator.
grammar file...
C : A | B
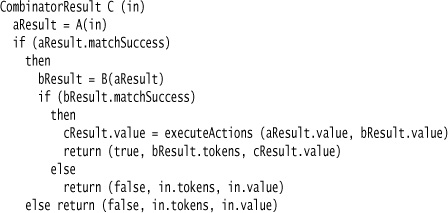
An alternative combinator for C tries one combinator first, say B; if the match status from that combinator is true, the return value for C is the same as that returned by B. We cycle through the alternatives, trying each one. If all alternatives fail, the return value is a failed match status and the input token buffer is unchanged. In pseudocode, this combinator looks like the following:

As you can see, this logic looks just like the recursive descent algorithm. The sequence operator is a bit more complicated.
grammar file...
C : A B
To implement this operator, we need to step through the components in the sequence. If any of these matches fail, we need to reset the token buffer to its input state. For the above grammar rule, the resulting combinator looks like the following:

This implementation and the others below rely on the characteristic behavior of the combinators. If the match succeeds, the tokens relating to that match are consumed in the token buffer. If the match fails, the combinator returns an unaltered token buffer.
The optional operator is straightforward.
grammar file...
C: A?
This operator either returns the original tokens or modifies them, based on the match of A. For the above grammar rule, the resulting combinator looks like the following:
CombinatorResult C ()
A()
return true
The list operator for one-or-more lists is our next operator to consider.
grammar file...
C: A+
This combinator first checks to make sure that at least one A is present. If it is, then we loop until the match fails and return the new token buffer. If the initial match fails, we return false along with the input tokens.

Of course, for an optional list, we would always return true and handle the token buffer appropriately, depending on the match. The code for that would look roughly like the following:
CombinatorResult C ()
while (A())
return true
The combinator implementations shown here are direct implementations of specific rules. The power of parser combinators comes from the fact that we can construct the composite combinators from the component combinators. Thus, the code for specifying the following sequence operation:
would really look more like this declaration:
C = new SequenceCombinator (A,B)
where the logic implementing the sequencing is shared across all such rules.
22.1.1 Dealing with the Actions
Now that we know how the recognition works, let’s move on to the actions. For the moment, we’ll again assume that we’ve got some state that we manipulate in the actions. The actions can take many forms. In Tree Construction, the actions would build up the abstract syntax tree while the parse proceeds. In Embedded Translation, the actions will populate our semantic model. The type of the match value will obviously vary based on what the actions are.
We start with our base case again, the terminal symbol combinator. If the match is successful, we populate the match value with the result of the match and invoke the actions on that match value. In the case of an identifier recognizer, for example, we might record it in a Symbol Table. For terminal symbols like identifiers and numbers, though, the action often simply records the specific token value for later use.
The sequence operation is more interesting when it comes to actions. Conceptually, once we have recognized all the components of the sequence, we need to call the action on the list of the match values from the individual components. We modify the recognizer to invoke the actions in this way.

We’re hiding a great deal in the executeActions method. The match values from the matches for A and B need to be saved so that we can use them in the actions.
Weaving in the actions for the other operators are similar. The alternative operator performs only the actions for the selected alternative. The list operator, like the sequence operator, must operate on all the match values. The optional operator only performs the actions on match, obviously.
The invocations for the actions are relatively straightforward. The challenge is getting the proper action methods associated with the combinator. In languages with closures or other ways of passing functions as parameters, we could simply have the details of the action method passed into the constructor as a function. In languages without closures, such as Java, we need to be a bit more clever. One approach is to extend the operator classes with classes specific to a particular production rule and override the action method to introduce the specific behavior.
As we alluded to above, the actions can be used to construct an abstract syntax tree. In that case, the match values passed to the action function would be the trees constructed for the different components, and the action would combine those parse trees as implied by the grammar rule in question. For example, a list operator will commonly have some node type in the syntax tree representing the list. The list operator action would then create a new subtree with that list node as the root, and make the subtrees from the component matches the children of this root.
22.1.2 Functional Style of Combinators
Now it’s time to relax the assumption about manipulating the action results and the token buffer in the background using state. Thought of in the functional style, a combinator is a function that maps an input combinator result value to an output combinator result value. The components of a combinator result value are the current state of the token buffer, the current status of the match, and the current state of the cumulative actions performed so far. Following this style, the sequence operator implementation with actions looks like this:
In this version, the saves are unnecessary since the input parameter’s value remains valid. This version also makes more explicit how the token buffer is handled and where the action values come from.
22.2 When to Use It
This approach occupies a nice middle ground between Recursive Descent Parser and using a Parser Generator. A significant benefit of using a Parser Generator is an explicit grammar specification for the language. The grammar in a Recursive Descent Parser is implied in the functions but is difficult to read as a grammar. With the Parser Combinator approach, the combinators can be defined declaratively, as shown in the example above. While it does not use BNF syntax, the grammar is clearly specified in terms of the component combinators and the operators. So with Parser Combinator, you get a reasonably explicit grammar without the build complications that tend to come with Parser Generator.
Libraries exist that implement the various grammar operators in different languages. Functional languages are an obvious choice to implement a Parser Combinator, given their support for functions as first-class objects which allows for passing an action function as a parameter to the combinator constructor. However, implementations in other languages are quite possible too.
As with Recursive Descent Parser, Parser Combinator results in a top-down parser, so the same restrictions apply. Many of the advantages of the Recursive Descent Parser also apply, in particular the ease of reasoning about when actions are performed. Even though a Parser Combinator is a very different implementation of a parser, the control algorithm of the parsing can be tracked using the same tools we use for debugging other programs. Indeed, the Parser Combinator approach coupled with an operator library or tested operator implementations allows the language implementer to focus on the actions rather than the parsing.
The biggest downside to a Parser Combinator is that you still have to build it yourself. In addition, you won’t get the more sophisticated parsing and error handling features that a mature Parser Generator gives you out of the box.
22.3 Parser Combinators and Miss Grant’s Controller (Java)
To implement the state machine parser in Java using Parser Combinator, we’ve got a couple of design choices to make. For this example, we’ll use the more functional approach utilizing a combinator result object and Embedded Translation to populate the state machine object as we proceed through the parse.
First, let’s revisit the full state machine grammar. The productions here are listed in reverse order to match the implementation strategy we’re using.
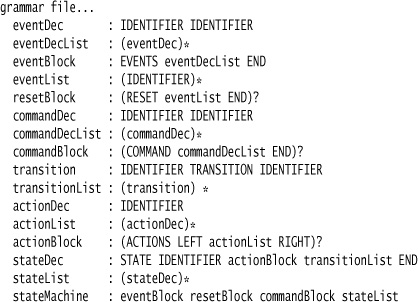
To construct a parser combinator for the full state machine, then, we need to construct parser combinators for each of the component terminals and nonterminals in the grammar. The full set of combinators in Java for this grammar is:


The terminal symbol combinators don’t have a direct analog in the grammar file since we used a lexical analyzer to find them. Past that point, though, the combinator declarations use previously defined combinators and those implementing various grammar operators to create the composite combinator. We’ll step through each of these individually.
To describe the parser combinator implementation, we’ll start with the simple cases and build up to the final state machine recognizer. We start with a basic Combinator class from which all the other combinators inherit.

All combinators have two functions. The recognizer maps an incoming CombinatorResult to a result value of the same type.
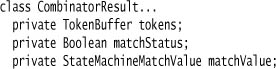
The three components of the result from a combinator are the status of the token buffer, the success or failure of the recognizer, and the object that represents the resulting action value in the token buffer. In our case, we use it simply to hold the token value string from a terminal match.
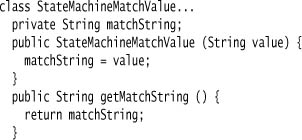
The second method on a combinator is the method that performs whatever actions relate to the match. The input to the action function is a number of match value objects, one object for each component combinator. For example, a sequence combinator that represents the rule:
grammar file...
C : A B
would have two match values passed to the action method.
Let’s start with the recognizer for the terminal symbols. As an example, we’ll use the identifier recognizer. The declaration for this recognizer is:

The terminal combinator class has a single instance variable identifying the token symbol to be matched.

The standard terminal recognition function is quite simple as well.

After verifying that the inbound match status is true, we check the current position in the token buffer to see if that value matches the value of our instance variable. If it does, we construct a successful CombinatorResult with the token buffer shifted and the token value from the matched token recorded in the result value. The action method is invoked on this match value, which in this case simply does nothing with it.
Now let’s take something a bit more interesting. The event block declaration grammar rule looks like this:
![]()
The declaration of the combinator for this rule uses the SequenceCombinator.

In this case, we again use the null action method, since the real work is actually done elsewhere. The constructor for an instance of SequenceCombinator accepts a list of combinators, one for each of the symbols in the production rule.

In this implementation, we’ve chosen to make separate classes for optional and required sequences, sharing the implementation, rather than introducing an optional operator and adding another level of production rules to the grammar. We extend this base class, AbstractSequenceCombinator, to make both the SequenceCombinator and OptionalSequenceCombinator classes. The common class has an instance variable representing the list of combinators of the sequence and a Boolean value that indicates whether this composite rule is optional or not.

The match function for the shared sequence combinator uses the Boolean value to determine what to do in the case of a a failed match.

We again use the guard clause to return immediately if the inbound match status is false. The match function uses a while loop to step through the different combinators defining the sequence, with the loop halting when the match status is false or when all combinators have been checked. If the overall match succeeds, this means that all combinators in the sequence matched successfully. In this case, we invoke the action method on the array of component match values. If the inbound value was successful, but something in the loop failed, we then need to consult the optional flag. In the case of an optional sequence, this match succeeds with the values and the input tokens returned to their state at the beginning of the match. Naturally, the action method isn’t invoked since no match occurred. Otherwise, a failed match is returned from this combinator, with the input values of the tokens and values restored.
An example of an optional sequence is the reset block:

for the grammar rule:

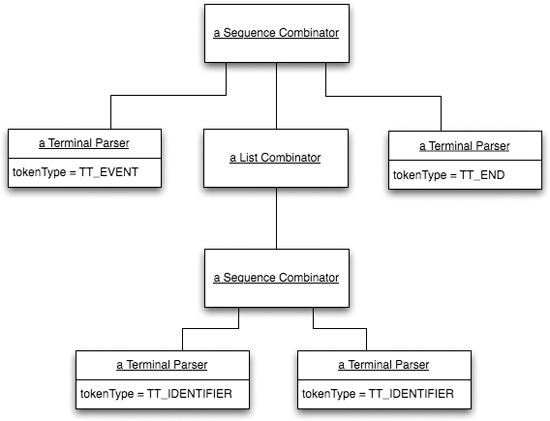
Before moving on to show how we customize actions, let’s finish off the grammar operators with the list operator. One production rule using the list operator is the event declaration list, with this grammar rule:
![]()
and the declaration in the parser appears as:
![]()
The list implementation shown here is for optional lists. We assume for this implementation that the list operator is applied to a single nonterminal. Clearly, this restriction is easy to relax. Given that, however, the constructor accepts only the single combinator, which then also represents the only instance variable in the class.

The match function is straightforward.

Since we don’t know in advance how many matches will succeed for the list, we use an array list to hold the match values. To make the Java type system happy, we must then transform it into an array of the same type to work with the variable arguments signature of the action method.
As we’ve mentioned, the actions for all the above combinators, with the exception of the identifier method, are null operations. The actions populating the various components of the state machine are actually associated with other nonterminals. In this implementation, we’ve used Java inner classes, extending the grammar operator base class, and overriding the action method in it. Let’s consider the event declaration production rule:
![]()
with the declaration in the parser appearing as:
![]()
The class definition is:

This class extends the SequenceCombinator class and overrides the action method. As with all the action methods, the input is simply the list of results from the matches, representing the identifier names for the event declaration. We use the same helper functions as before to load the event into the state machine, extracting the name strings from the relevant match values. The other production follow this same pattern of implementation.