
Chapter 4. Implementing an Internal DSL
Now that I’ve gone through some general issues in implementing DSLs, it’s time to go into the specifics of implementing particular flavors of DSLs. I’ve decided to start with internal DSLs as they are often the most approachable form of DSLs to write. Unlike external DSLs, you don’t need to learn about grammars and language parsing, and unlike language workbenches, you don’t need any special tools. With internal DSLs you work in your regular language environment. As a result, it’s no surprise that there’s been a lot of interest in internal DSLs in the last couple of years.
When you use internal DSLs, you are very much constrained by your host language. Since any expression you use must be a legal expression in your host language, a lot of thought in internal DSL usage is bound up in language features. A good bit of the recent impetus behind internal DSLs comes from the Ruby community, whose language has many features which encourage DSLs. However, many Ruby techniques can be used in other languages too, if usually not as elegantly. And the doyen on internal DSL thinking is Lisp, one of the world’s oldest computer languages with a limited but very appropriate set of features for the job.
Another term you might hear for an internal DSL is fluent interface. This was a term coined by Eric Evans and myself to describe more language-like APIs. It’s a synonym for an internal DSL looked at from the API direction. It gets to the heart of the difference between an API and a DSL—the language nature. As I’ve already indicated, there is a gray area between the two. You can have reasonable but ill-defined arguments about whether a particular language construction is language-like or not. The advantage of such arguments is that they encourage reflection on the techniques you are using and on how readable your DSL is; the disadvantage is that they can turn into continual rehashes of personal preferences.
4.1 Fluent and Command-Query APIs
For many people, the central pattern of a fluent interface is that of Method Chaining. A normal API might have code like this:

With Method Chaining, we can express the same thing with:

Method Chaining uses a sequence of method calls where each call acts on the result of the previous calls. The methods are composed by calling one on top of the other. In regular OO code, these are usually derided as “train wrecks”: The methods separated by dots look like train cars, and they are wrecks because they often are a sign of code that is brittle to changes in the interfaces of the classes in the middle of the chain. Thinking fluently, however, Method Chaining allows you to easily compose multiple method calls without relying on a lot of variables, which gives you code that seems to flow, feeling more like its own language.
But Method Chaining isn’t the only way to get this sense of flow. Here is the same thing using a sequence of method call statements, which I call a Function Sequence:
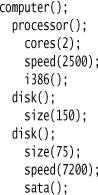
As you can see, if you try to lay out and organize a Function Sequence in an appropriate way, it can read as clearly as Method Chaining. (I use “function” rather than “method” in the name, as you can use this in a non-OO context with function calls while Method Chaining needs object-oriented methods.) The point here is that fluency isn’t as much about the style of syntax you use as it is about the way you name and factor the methods themselves.
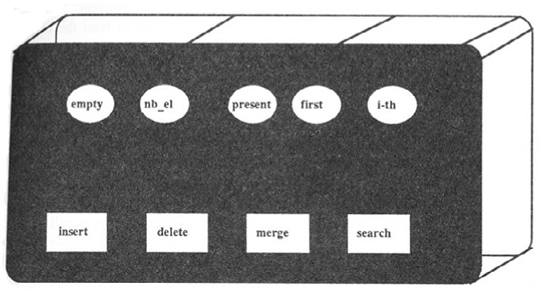
In the early days of objects, one of the biggest influences on me and many others was Bertrand Meyer’s book Object-Oriented Software Construction. One of the analogies he used to talk about objects was to treat them as machines. In this view, an object was a black box, its interface being a series of displays to view the observable state of the object and buttons that you could press to change the object. This effectively offers a menu of different things you can do with the object. This style of interface is the dominant way we think about interacting with software components; it is so dominant that we don’t even think of giving it a name, hence my coining of the term “command-query interface” to describe it.
Figure 4.1 The original figure from OOSC that Bertrand Meyer used to illustrate the machine metaphor. The ovals represent query buttons that have indicator lights to reveal the state of the machine when you press them, but do not alter the machine’s state. The rectangles are command buttons that do alter state, causing the machine to start “screeching and clicking,” but lacking any indicator lights to tell you what the noise is all about.
The essence of fluent interfaces is that they approach thinking about using components differently. Instead of a box of objects, each sporting lots of buttons, we think linguistically of composing sentences using clauses that weave these objects together. It’s this mental shift that is the core difference between an internal DSL and just calling an API.
As I’ve mentioned earlier, it’s a very fuzzy difference. Treating APIs as languages is also an old and well-regarded analogy that goes back before objects were the norm. There’s plenty of cases that could be argued as command-query or fluent. But I do think that, despite its fuzziness, it’s a helpful distinction.
One of the consequences of the differences between the two styles of interface is that the rules about what makes a good interface are different. Meyer’s original machine metaphor is very apt here. The figure appeared in a section of OOSC that introduced the principle of command-query separation.
Command-query separation says that the various methods on an object should be divided into commands and queries. A query is a method that returns a value, but does not change the observable state of the system. A command may change the observable state, but should not return a value. This principle is valuable because it helps us identify query methods. Since queries don’t have side effects, you can call them multiple times and change the order of using them—without changing the results of calling them. You have to be much more careful with commands because they do have side effects.
Command-query separation is an extremely valuable principle in programming, and I strongly encourage teams to use it. One of the consequences of using Method Chaining in internal DSLs is that it usually breaks this principle—each method alters state but returns an object to continue the chain. I have used many decibels disparaging people who don’t follow command-query separation, and will do so again. But fluent interfaces follow a different set of rules, so I’m happy to allow it there.
Another important difference between a command-query and fluent interface is in the naming of the methods. When you’re coming up with names for a command-query interface, you want the names to make sense in a stand-alone context. Often, if people are looking for a method to do something, they’ll run their eyes down the list of methods on a web document page or in an IDE menu. As a result, the names need to convey clearly what they do in that kind of context—they are the labels on the buttons.
With fluent interfaces, naming is quite different. Here, you concentrate less on each individual element in the language, but more on the overall sentences that you can form. As a result, you can often have methods whose names make no sense in an open context, but read properly in the context of a DSL sentence. With DSL naming, it’s the sentence that comes first; the elements are named to fit in with that context. DSL names are written with the context of the specific DSL in mind, while command-query names are written to work without any context (or in any context, which is the same thing).
4.2 The Need for a Parsing Layer
The fact that a fluent interface is a different kind of interface to a command-query one can lead to complications. If you mix both styles of interface on the same class, it’s confusing. I therefore advocate keeping the language-handling elements of a DSL separate from regular command-query objects by building a layer of Expression Builders over regular objects. Expression Builders are objects whose sole task is to build up a model of normal objects using a fluent interface—effectively translating fluent sentences into a sequence of command-query API calls.
The different nature of the interfaces is one reason for Expression Builders, but the primary reason is a classic “separation of concerns” argument. As soon as you introduce some kind of language, even an internal one, you have to write code that understands that language. This code will often need to keep track of data that is only relevant while the language is being processed—parsing data. Understanding the way in which the internal DSL works is a reasonable amount of work, and it’s not needed once you’ve populated the underlying model. You don’t need to understand the DSL or how it works to understand how the underlying model operates, so it’s worth keeping the language-processing code in a separate layer.
This structure follows the general layout of DSL processing. The underlying model of command-query interface objects is the Semantic Model. The layer of Expression Builders is (part of the) parser.
I’ve puzzled a bit over using the term “parser” for this layer of Expression Builders. Usually we use “parser” in the context of parsing text. In this case, the host language parser manipulates the text. But there are many parallels between what we do with Expression Builders and what a parser does. The key difference is that while a traditional parser arranges a stream of tokens into a syntax tree, the input for the Expression Builders is a stream of function calls. The parallels to other parsers are that we still find it useful to think of arranging these function-call parse nodes into a tree, we use similar parsing data structures (such as Symbol Table), and we still populate a Semantic Model.
Separating the Semantic Model from Expression Builders introduces the usual advantages of a Semantic Model. You can test the Expression Builders and the Semantic Model independently. You can have multiple parsers, mixing internal and external DSLs or supporting multiple internal DSLs with multiple Expression Builders. You can evolve the Expression Builders and the Semantic Model independently. This is important since DSLs, like any other software, are hardly ever fixed. You need to be able to evolve the software, and often it’s useful to change the underlying framework without changing the DSL scripts or vice versa.
There is an argument for not using Expression Builders, but only when the Semantic Model objects use fluent interfaces themselves, rather than a command-query interface. There are some cases where it makes sense for a model to use a fluent interface, if that’s the main way people will interact with it. In most situations, however, I prefer a command-query interface on a model. The command-query interface is more flexible in how it can be used in different contexts. A fluent interface often needs temporary parsing data. In particular, I object to mixing a fluent and a command-query interface on the same objects—that’s just too confusing.
As a result, I’ll be assuming Expression Builders for the rest of this book. Although I acknowledge that you may not have to use Expression Builders all the time, I do think you should use them most of the time, so I’ll write with that majority case in mind.
4.3 Using Functions
Since the beginning of computing, programmers sought to package up common code into reusable chunks. The most successful packaging construct we’ve come up with is the function (also called subroutine, procedure, and method in OO-land). Command-query APIs are usually expressed in functions, but DSL structures are also often built primarily on functions. The difference between a command-query interface and a DSL centers around how functions are combined.
There are a number of patterns for combining functions to make a DSL. At the beginning of this chapter I showed two. Let’s recap, as I’ve forgotten what I wrote back there. First, Method Chaining:

Then, Function Sequence:
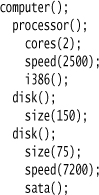
These are different patterns for combining functions, which naturally leads to the question of which one you should use. The answer involves various factors. The first factor is the scope of the functions. If you use Method Chaining, the functions in the DSL are methods that need to only be defined on the objects that take part in the chain, usually on an Expression Builder. On the other hand, if you use bare functions in a sequence, you have to ensure the functions resolve properly. The most obvious way to do this is to use global functions, but using globals introduces two problems: complicating the global namespace and introducing global variables for parsing data.
Good programmers these days are nervous about any global stuff, as it makes it harder to localize changes. Global functions will be visible in every part of a program, but ideally you want the functions to only be available within the DSL processing bit. There are various language features that can remove the need to make everything global. A namespace capability allows you to make functions look global only when you import a particular namespace (Java has static imports).
The global parsing data is the more serious problem. Whichever way you do a Function Sequence, you’ll need to manipulate Context Variables in order to know where you are in parsing the expression. Consider the calls to diskSize. The builder needs to know which disk’s size is being specified, so it does that by keeping track of the current disk in a variable—which it updates during the call to disk. Since all the functions are global, this state will end up being global too. There are things you can do to contain the globality—such as keeping all the data in a singleton—but you can’t get away from global data if you use global functions.
Method Chaining avoids much of this because, although you still need some kind of bare function to begin the chain, once you’ve started, all parsing data can be held on the Expression Builder object that the chaining methods are defined on.
You can avoid all this globalness with Function Sequence by using Object Scoping. In most cases this involves placing the DSL script in a subclass of an Expression Builder so that bare function calls are resolved against methods in the Expression Builder superclass. This handles both globalness problems. All the functions in the DSL are defined only in the builder class, and thus localized. Furthermore, since these are instance methods, they connect directly to data on the builder instance to store the parsing data. That’s a compelling set of advantages for the cost of placing the DSL script in a builder subclass, so that’s my default option.
A further advantage of using Object Scoping is that it may support extensibility. If the DSL framework makes it easy to use a subclass of the scoping class, the user of DSL can add their own DSL methods to the language.
Both Function Sequence and Method Chaining require you to use Context Variables in order to keep track of the parse. Nested Function is a third function combination technique that can often avoid Context Variables. Using Nested Function, the computer configuration example looks like this:

Nested Function combines functions by making function calls arguments in higher-level function calls. The result is a nesting of function invocations. Nested Functions have some powerful advantages with any kind of hierarchic structure, which is very common in parsing. One immediate advantage is that, in our example, the hierarchic structure of the configuration is echoed by the language constructs themselves—the disk function is nested inside the computer function just as the resulting framework objects are nested. The nesting of the functions thus reflects the logical syntax tree of the DSL. With Function Sequence and Method Chaining, I can only hint at that syntax tree through strange indentation conventions; Nested Function allows me to reflect that tree within the language (although I still format the code rather differently to how I’d format regular code).
Another consequence is the change in evaluation order. With a Nested Function, the arguments to a function are evaluated before the function itself. This often allows you to build up framework objects without using a Context Variable. In this case, the processor function is evaluated and can return a complete processor object before the computer function is evaluated. The computer function can then directly create a computer object with fully formed parameters.
A Nested Function thus works very well when building higher-level structures. However, it isn’t perfect. The punctuation of parentheses and commas is more explicit, but it can also feel like noise compared to the indentation conventions alone. (This is where Lisp scores highly, its syntax works extremely well with Nested Functions.) A Nested Function also implies using bare functions, so it runs into the same problems of globalness as Function Sequence—albeit with the same Object Scoping cure.
The evaluation order can also lead to confusion if you are thinking in terms of a sequence of commands rather than building up a hierarchic structure. A simple sequence of Nested Functions ends up being evaluated backwards to the order they are written, as in third(second(first))). My colleague Neal Ford likes to point out that if you want to write the song “Old MacDonald Had a Farm” with Nested Functions, you’d have to write the memorable chorus phrase as o(i(e(i(e())))). Both Function Sequence and Method Chaining allow you to write the calls in the order they’ll be evaluated.
Nested Function also usually loses out in that the arguments are identified by position rather than name. Consider the case of specifying a disk’s size and speed. If all I need for these are two integers, then all I really need is disk(75, 7200), but that doesn’t remind me which is which. I can solve that by having Nested Functions that just return the integer value and write disk(size(75), speed(7200)). That’s more readable, but doesn’t prevent me from writing disk(speed(7200), size(75)) and getting a disk that would probably surprise me. To avoid this problem, you end up returning some richer intermediate data—replacing the simple integer with a token object—but that’s an annoying complication. Languages with keyword arguments avoid this problem but, sadly, this useful syntactic feature is very rare. In many ways, Method Chaining is a mechanism that helps you supply keyword arguments to a language that lacks them. (Soon I’ll discuss Literal Map which is another way to overcome the lack of named parameters.)
Most programmers see the heavy use of Nested Function as unusual, but this really reflects how we use these function combination patterns in normal (non-DSL) programming. Most of the time, programmers use Function Sequence with small dashes of Nested Function and (in an OO language) Method Chaining. However, if you’re a Lisp programmer, Nested Function is something you use often in regular programming. Although I’m describing these patterns in the context of DSL writing, they are actually general patterns we use to combine expressions. It’s just that what makes a good combination differs when we think of an internal DSL.
I’ve written about these patterns so far as if they were mutually exclusive, but in fact you’ll usually use a combination of these (and further patterns that I’ll describe later) in any particular DSL. Each pattern has its strengths and weaknesses, and different points in a DSL have different needs. Here’s one possible hybrid:

This DSL script uses all three patterns that I’ve talked about so far. It uses Function Sequence to define each computer in turn, each computer function uses Nested Function for its arguments, each processor and disk is built up using Method Chaining.
The advantage of this hybrid is that each section of the example plays to the strengths of each pattern. A Function Sequence works well for defining each element of a list. It keeps each computer definition well separated into statements. It’s also easy to implement, as each statement can just add a fully formed computer object to a result list.
The Nested Function for each computer eliminates the need for a Context Variable for the current computer, as the arguments are all evaluated before the computer function is called. If we assume that a computer consists of a processor and a variable number of disks, then the arguments lists of the function can capture that very well with its types. In general, Nested Function makes it safer to use global functions, as it’s easier to arrange things so the global function just returns an object and doesn’t alter any parsing state.
If each processor and disk have multiple optional arguments, then that works well with Method Chaining. I can call whatever values I wish to set to build up the element.
However, using a mix also introduces problems. In particular, it results in punctuational confusion: Some elements are separated with commas, others with periods, others with semicolons. As a programmer, I can figure it out—but it can also be difficult to remember which is which. A nonprogrammer, even one who is only reading the expression, is more likely to be confused. The punctuational differences are an artifact of the implementation, not the meaning of the DSL itself, so I’m exposing implementation issues to the user—always a suspicious idea.
So, in this case I wouldn’t use exactly this kind of hybrid. I’d be inclined instead to use Method Chaining instead of Nested Function for the computer function. But I’d still use Function Sequence for the multiple computers, as I think that’s a clearer separation for the user.
This tradeoff discussion is a microcosm of the decisions you’ll need to make when building your own DSL. I can provide some indication here of the pros and cons of different patterns—but you’ll have to decide on the blend that works for you.
4.4 Literal Collections
Writing a program, whether in a general-purpose language or a DSL, is about composing elements together. Programs usually compose statements into sequences, and compose by applying functions. Another way to compose elements is to use Literal List and Literal Map.
A Literal List captures a list of elements, either of different types or of the same type, with no fixed size. In fact, I’ve already slipped an example of Literal List past you. Look again at the Nested Function version of the computer configuration code:

If I collapse the lower-level function calls here, I get code that looks like this:
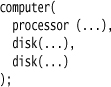
The contents of the call to computer is a list of elements. Indeed in a curly-brace language like Java or C#, a varargs function call like this is a common way to introduce a Literal List.
Other languages, however, give you different options. In Ruby, for example, I could represent this list using Ruby’s built-in syntax for literal lists.

There’s little difference here, except that I have square brackets instead of parentheses, but I can use this kind of list in more contexts than just within a function call.
C-like languages do have a literal array syntax {1,2,3} that could be used as a more flexible Literal List, but you’re usually quite limited as to where you can use it and what you can put in it. Other languages, like Ruby, allow you to use literal lists much more widely. You can use varargs functions to handle most of these cases, but not all of them.
Scripting languages also allow a second kind of literal collection: a Literal Map, also called hash or dictionary. With it, I can represent the computer configuration like this (again in Ruby):

The Literal Map is very handy for cases like setting the processor and disk properties here. In these cases, the disk has multiple subelements all of which are optional but may only be set once each. Method Chaining is good for naming the subelements, but you have to add your own code to ensure each disk mentions its speed only once. This is baked into the Literal Map and is familiar to people using the language.
A still better construct for this would be a function with named parameters. Smalltalk, for example, would handle this with something like diskWithSize: 75 speed: 7200 interface: #sata. However, even fewer language have named parameters than have a Literal Map syntax. But if you’re using such a language, then using named parameters is a good way of implementing a Literal Map.
This example also introduces another syntactic item that’s not present in curly languages: the symbol data type. A symbol is a data type that, on first sight, is just like a string, but is there primarily for lookups in maps, particularly Symbol Tables. Symbols are immutable and are usually implemented so the same value of the symbol is the same object, to help with performance. Their literal form doesn’t support spaces and they don’t support most string operations, as their role is symbol lookup rather than holding text. Elements above, like :cores, are symbols—Ruby indicates symbols with a leading colon. In languages without symbols, you can use strings instead, but in languages with a symbol data type you should use it for this kind of purpose.
This is a good point to talk a little about why Lisp makes such an appealing language for internal DSLs. Lisp has a very convenient Literal List syntax: (one two three). It also uses the same syntax for function calls: (max 5 14 2). As a result, a Lisp program is all nested lists. Bare words (one two three) are symbols, so the syntax is all about representing nested lists of symbols, which is an excellent basis for an internal DSL—provided you’re happy with your DSL having the same fundamental syntax. This simple syntax is both a great strength and a weakness of Lisp. It’s a strength because it is very logical, making perfect sense if you follow it. Its weakness is that you have to follow what is an unusual syntactic form—and if you don’t make that jump, it all seems like lots of irritating, silly parentheses.
4.5 Using Grammars to Choose Internal Elements
As you can see, there are many different choices for the elements of an internal DSL. One technique that you can use to choose which one to use is to consider the logical grammar of your DSL. The kinds of grammar rules that you create when using Syntax-Directed Translation can also make sense in thinking about an internal DSL. Certain kinds of expressions, with their BNF rules, suggest certain kinds of internal DSL structures.

If you have a clause of mandatory elements (parent ::= first second), then Nested Function works well. The arguments of a Nested Function can match the rule elements directly. If you have strong typing, then type-aware autocompletion can suggest the correct items for each spot.
A list with optional elements (parent ::= first maybeSecond? maybeThird?) is more awkward for Nested Function, as you can easily end up with a combinatorial explosion of possibilities. In this case, Method Chaining usually works better as the method call indicates which element you are using. The tricky element with Method Chaining is that you have to do some work to ensure you only have one use of each item in the rule.
A clause with multiple items of the same subelement (parent ::= child*) works well with a Literal List. If the expression defines statements at the top level of your language, then this is one of the few places I’d consider Function Sequence.
With multiple elements of different subelements (parent ::= (this | that | theOther)*), I’d move back to Method Chaining since, again, the method name is a good signal of which element you are looking at.
A set of subelements is a common case that doesn’t fit well with BNF. This is where you have multiple children, but each child can only appear at most once. You can also think of this as a mandatory list where the children can appear in any order. A Literal Map is a logical choice here; the issue you’ll normally run into is the inability to communicate and enforce the correct key names.
Grammar rules of the at-least-once form (parent ::= child+) don’t lend themselves well to the internal DSL constructs. The best bet is to use the general multiple element forms and check for at least one call during the parse.
4.6 Closures
Closures are a programming language capability that’s been around for a long time in some programming language circles (such as Lisp and Smalltalk) but that has only recently begun to raise its head in more mainstream languages. They go under various names (lambdas, blocks, anonymous functions). A short description of what they do is this: They allow you to take some inline code and package it up into an object that can be passed around and evaluated whenever it suits you. (If you’ve not come across them yet, you should read Closure.)
In internal DSLs, we use closures as Nested Closures within DSL scripts. A Nested Closure has three properties that make it handy for use in DSLs: inline nesting, deferred evaluation, and limited-scope variables.
When I talked earlier about Nested Function, I said that one of its great features is that it allows you to capture the hierarchic nature of the DSL in a way that is meaningful to the host programming language, instead of suggesting the hierarchy with indentation, as you have to do with Function Sequence and Method Chaining. A Nested Closure also has this property, with the additional advantage that you can put any inline code into the nesting—hence the term inline nesting. Most languages have restrictions on what you can put into function arguments, which limits what you can write in a Nested Function, but a Nested Closure allows you to break those limitations. This way you can nest more complicated structures, such as allowing a Function Sequence inside the Nested Closure in a way that wouldn’t be possible inside a Nested Function. There’s also an advantage in that many languages make it easier to syntactically nest multiple lines inside a Nested Closure than inside a Nested Function.
Deferred evaluation is perhaps the most important capability that Nested Closure adds. With Nested Function, the arguments to the function are evaluated before the enclosing function is called. Sometimes this is helpful, but sometimes (as in the Old MacDonald example) it’s confusing. With a Nested Closure, you have complete control about when the closures are evaluated. You can alter the order of evaluation, not evaluate some at all, or store all the closures for later evaluation. This becomes particularly handy when the Semantic Model is one that takes strong control of the way a program executes—a form of model that I call an Adaptive Model and will describe in much more detail in “Alternative Computational Models,” p. 113. In these cases, a DSL can include sections of host code within the DSL and put these code blocks into the Semantic Model. This allows you to intermix DSL and host code more freely.
The final property is that a Nested Closure allows you to introduce new variables whose scope is limited to that closure. By using limited-scope variables it can be easier to see what the methods in the language are acting on.
Now is a good time for an example to illustrate some of this. I’ll start by another example for the computer builder.
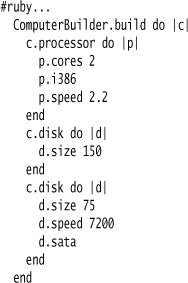
(I use Ruby here, as Java doesn’t have closures whereas C#’s closure syntax is a bit too noisy and thus doesn’t really show the value of a Nested Closure.)
Here we see a good example of inline nesting. The calls to processor and disk both contain code which is several statements of Ruby. This also illustrates limited-scope variables for the computer, processor, and disks. These variables add a bit of noise, but can make it easier for people to see what objects are being manipulated where. It also means that this code doesn’t need global functions or Object Scoping, for functions such as speed are defined on the limited-scope variables (which in this case are Expression Builders).
With a DSL like the computer configuration, there isn’t really much need for deferred evaluation. This property of closures kicks in more when you want to embed bits of host code in the structure of a model.
Consider an example of where you want to use a set of validation rules. Commonly, in an object-oriented environment we think of an object being valid or not, and have some code somewhere to check its validity. Validation may be more involved in that it’s often contextual—you validate an object in order to do something to it. If I’m looking at data about a person, I might have different validation rules to check if that person is eligible for one insurance policy rather than another. I might specify the rules in a DSL form like this:

In this example, the contents of the function call With is a closure that takes a person as an argument and contains some arbitrary C# code. This code can be stored in the Semantic Model and executed as the model runs—which provides a lot of flexibility in choosing your validations.
Nested Closure is a very useful DSL pattern, but it’s often frustratingly awkward to use. Many languages (such as Java) don’t support closures. You can get around a lack of closures with other techniques, such as function pointers in C or command objects in an OO language. Such techniques are valuable to support Adaptive Models in such languages. However, these mechanisms require a lot of unwieldy syntax that can add a debilitating amount of noise to a DSL.
Even languages that do support closures often do so with an awkward syntax. C#’s has got steadily better with ongoing versions, but is still not as clean as I’d like. I was used to Smalltalk’s very clean closure syntax. Ruby’s closure syntax is almost as clean as Smalltalk’s, which is why Nested Closures are so common in Ruby. Oddly enough, Lisp, despite it’s first-class support for closures, also has an awkward syntax for them—which it deals with by using macros.
4.7 Parse Tree Manipulation
Since I’ve invoked the name of Lisp and its macros, there’s a natural segue into Parse Tree Manipulation. The segue is there because of Lisp’s macros, which are widely used to make closures more syntactically palatable, but perhaps find their greatest power in being able to do some clever code writing tricks.
The basic idea behind Parse Tree Manipulation is to take an expression in the host programming language and, instead of evaluating it, get its result—to consider the parse tree as data. Consider this expression in C#: aPerson.Age > 18. If I take this expression with a binding for the variable aPerson and evaluate it, I’ll get a Boolean result. An alternative, available in some languages, is to process this expression to yield the parse tree for the expression (Figure 4.2).
When I have the parse tree like this, I can manipulate it at runtime to do all sorts of interesting things. One example is to walk the parse tree and generate a query in another query language, such as SQL. This is essentially what .NET’s Linq language does. Linq allows you to express many SQL queries in C#, which many programmers prefer.
Figure 4.2 A parse tree representation of aPerson.Age > 18
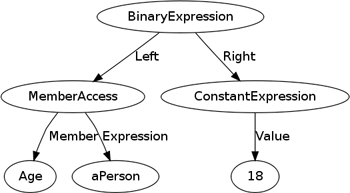
The strength of Parse Tree Manipulation is in allowing you to write expressions in the host language that can then be converted into different expressions that populate the Semantic Model in ways that are beyond just storing the closure itself.
In C#’s case above, this manipulation is done with an object model representation of the parse tree. In Lisp’s case, this manipulation is done by macro transformations on Lisp source code. Lisp is well suited to this because the structure of its source code is very close to that of a syntax tree. Parse Tree Manipulation is more widely used in Lisp for DSL work—so much so that Lispers often wail at the lack of macros in other languages. My view is that manipulating an object model of the parse tree in C# style is a more effective way of doing Parse Tree Manipulation than Lisp macros—although this may be due to my lack of practice with Lisp’s macro processing.
Whatever mechanism you use, the next question is how important Parse Tree Manipulation is as a technique for DSLs. One very prominent use is in Linq—a Microsoft technology that allows you to express query conditions in C# and turn them into different query languages for various target data structures. In this way, one C# query can be turned into SQL for relational databases and XPath for XML structures, or kept in C# for in-memory C# structures. It’s essentially a mechanism that allows application code to do runtime code translation, generating arbitrary code from C# expressions.
Parse Tree Manipulation is a powerful, but somewhat complex, technique that hasn’t been supported much by languages in the past, but these days has been getting a lot more attention due to its support in C# 3 and Ruby. Since it’s relatively new (at least outside the Lisp world), it’s hard to evaluate how truly useful it is. My current perception is that it’s a marginal technique—something that is rarely needed but very handy on the occasions when that need arises. Translating queries to multiple data targets the way Linq does is a perfect example of its usefulness; time will tell what other applications may emerge.
4.8 Annotation
When the C# language was launched, many programmers sneered that it was really just a warmed-over Java. They had a point, although there’s no need to sneer at a well-executed implementation of proven ideas. However, one example of a feature that wasn’t a copy of mainstream ideas was attributes, a language feature later copied by Java under the name of Annotations. (I will use the Java name since “attribute” is such an overloaded term in programming.)
An Annotation allows a programmer to attach metadata to programming constructs, such as classes and methods. These annotations can be read during compilation or at runtime.
For an example, let’s assume we wish to declare that certain fields can only have a limited valid range. We can do this with an annotation like this:

The obvious alternative to this would be to put range-checking code into the setter of the field. However, the annotation has a number of advantages. It reads more clearly as a bound for the field, it makes it easy to check the range either when setting the attribute or in a later object validation step, and it specifies the validation rule in such a way that could be read to configure a GUI widget.
Some languages provide a specific language feature for such number ranges (I remember Pascal did). You can think of Annotations as a way of extending the language to support new keywords and capabilities. Indeed, even existing keywords might have been done better with Annotations—from a green field I’d argue that access modifiers (private, public, etc.) would be better that way.
Since Annotations are so closely bound to the host language, they are suited for fragmentary DSLs and not stand-alone DSLs. In particular, they are good at providing a very integrated feel of adding domain-specific enhancements to the host language.
The similarities between Java’s annotations and .NET’s attributes are pretty clear, but there are other language constructs that look different while doing essentially the same thing. Here’s Ruby on Rails’ way of specifying an upper limit for the size of a string:
![]()
The syntax is different in that you indicate which field the validation applies to by providing the name of the field (:last_name) rather than placing the Annotations next to the field. The implementation is also different in that this is actually a class method that’s executed when the class is loaded into the running system, rather than a particular language feature. Despite these differences, it’s still about adding metadata to program elements, and it’s used in a way similar to Annotations. So I think it’s reasonable to consider it essentially the same concept.
4.9 Literal Extension
One of the things that have caused the recent spike in interest in DSLs is the use of DSL expressions in Ruby on Rails. A common example of its DSL expressions is a fragment like 5.days.ago. Most of that expression is Method Chaining, such as we’ve already seen. The new part is the fact that the chain begins on a literal integer. The tricky bit here is that integers are provided by the language or by standard libraries. In order to start a chain like this, you need to use Literal Extension. To do this, you need to be able to add methods to external library classes—which may or may not be a capability of the host language. Java, for example, does not support this. C# (through extension methods) and Ruby do.
One of the dangers of Literal Extension is that it adds methods globally, while they should only be used within the often limited context of DSL usage. This is a problem with Ruby, compounded by the fact that there’s no easy mechanism in the language to find where the extension was added. C# handles this by putting extension methods in a namespace that you need to explicitly import before you can use them.
Literal Extension is one of those things that you don’t need to use terribly often, but can be very handy when you do—it really gives the sense of customizing the language for your domain.
4.10 Reducing the Syntactic Noise
The point of internal DSLs is that they are just expressions in the host language, written in a form that makes them read well as a language. One of the consequences of this form is that they bring with them the syntactic structure of the host language. In some ways this is good, as it provides a syntax familiar to many programmers, but others find some of the syntax annoying.
One way to reduce the burden of this syntax is write chunks of DSL in a syntax that is very close the host language, but not exactly the same, and then use simple text substitution to convert it to the host language. This Textual Polishing can convert a phrase like 3 hours ago to 3.hours.ago or, more ambitiously, 3% if value at least $30000 to percent(3).when.minimum(30000).
While it’s a technique I’ve seen described a few times, I have to say I’m not a big fan of it. The substitutions get convoluted pretty quickly, and when they do it’s much easier to use a full external DSL.
Another approach is to use syntax coloring. Most text editors provide customizable text coloring schemes. When communicating with domain experts, you can use a special scheme that de-emphasizes any noisy syntax, for example by coloring it a light grey on white background. You can even go so far as to make it disappear by coloring it the same as the background.
4.11 Dynamic Reception
One of the properties of dynamic languages, such as Smalltalk or Ruby, is that they process method invocations at runtime. As a result, if you write aPerson.name and no name method is defined on the person, the code will compile happily and only raise an error at runtime (unlike C# or Java, where you will get a compilation error). While many people see this as a problem, dynamic language advocates can take advantage of this.
The usual mechanism used by these languages is to handle such an unexpected call by routing it to a special method. The default action of this special method (method_missing in Ruby, doesNotUnderstand in Smalltalk) is to raise an error, but programmers can override the method to do other things. I call this overriding Dynamic Reception since you are making a dynamic (runtime) choice on what is a legal method to receive. Dynamic Reception can lead to a number of useful idioms in programming, particularly when using proxies where you often want to wrap an object and do something with its method invocations without needing to know exactly which methods are being called.
In DSL work, a common use of Dynamic Reception is to move information from method arguments into the method name itself. A good example of this is Rails Active Record’s dynamic finders. If you have a person class with a firstname field, you may want to find people by their first names. Instead of defining a find method for every field, you could have a generic find method that takes the field name as argument: people.find_by("firstname", "martin"). This works, but feels a bit odd since you would expect "firstname" to be part of the method name rather than a parameter. Dynamic Reception allows you to write people.find_by_firstname("martin") without having to define the method in advance. You override the missing method handler to see if the invoked method begins with find_by, process the name to extract the field name, and turn it into an invocation of the fully parametrized method. You can do this all in one method, or in separate methods, such as people.find.by.firstname("martin").
The crux of Dynamic Reception is that it gives you the option to move information from parameters to method names, which in some cases can make expressions easier to read and understand. The danger is that it can only take so much—you don’t want to find yourself doing complicated structures in a sequence of method names. If you need anything more complicated than a single list of things, consider using something with more structure (such as Nested Function or Nested Closure) instead. Dynamic Reception also works best when you are doing the same basic processing with each call, such as building up a query based on property names. If you are handling dynamically received calls differently (i.e., you have different code to process firstname and lastname), then you should be writing explicit methods without relying on Dynamic Reception.
4.12 Providing Some Type Checking
Having looked at something that requires a dynamic language, it’s now time to flip over into the world of static languages and look at some ways to benefit from static type checking.
There is a long-running, and potentially endless, debate about whether it’s better to have static type checking in a language or not. I don’t really want to revisit that here. Many people consider type checking at compile time to be very valuable, while others claim that you don’t find many errors from such type checking that aren’t caught by good tests—which are always needed.
There’s a second argument in favor of using static typing. One of the great benefits of modern IDEs is that they provide some excellent support based on static typing. I can type the name of a variable, hit a control key combination, and get a list of methods that I can invoke on that variable based on the variable’s type. The IDE can do this because it knows the types of the symbols in the code.
Most similar symbols in a DSL, however, don’t have this support, because we need to represent them as strings or symbol data types and hold them in our own symbol table. Consider this fragment of Ruby from the gothic security example (p. 14):
![]()
Here :waitingForLight is a symbol data type. If we were to translate this code into Java, we’d see something like this:
![]()
Again, our symbols are just primitive strings. I have to wrap waitingForLight in a method so I can chain methods onto it. When I’m entering the target state, I have to type unlockedPanel rather than select from a list of states with the IDE’s autocompletion mechanism.
What I’d rather have is this:
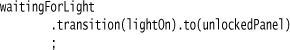
This not only reads better, avoiding the state method and noisy quotes; I also get proper type-aware autocompletion for my triggering events and target states. I can make full use of the IDE’s capabilities.
To do this, I need a way to declare symbol types (such as state, command, event) in my DSL processing mechanism, and then declare the symbols I use in a particular DSL script (such as lightOn or waitingForLight). One way of doing this is a Class Symbol Table. In this approach, the DSL processor defines each symbol type as a class. When I write a script, I put it in a class and declare fields for my symbols. So, to define a list of states, I begin by creating a States class for the symbol type. I define the states used in a script by a field declaration.
![]()
The result, like many DSL constructs, looks rather strange. I would never normally advocate a plural name for a class such as used here for States. But it does result in an editing experience that meshes much more closely with the general experience of Java programming.