
Chapter 8. Code Generation
So far in my discussion of implementing DSLs, I’ve talked about parsing some DSL text, usually with the aim of populating a Semantic Model, and putting interesting behavior in that model. In many cases, once we can populate the Semantic Model our work is done—we can just execute the Semantic Model to get the behavior we’re looking for.
While executing the Semantic Model directly is usually the easiest thing to do, there are plenty of times when you can’t do that. You may need your DSL-specified logic to execute in a very different environment, one where it’s difficult or impossible to build a Semantic Model or a parser. It’s in these situations that you can reach for code generation. By using code generation, you can take the behavior specified in the DSL and run it in almost any environment.
When you use code generation, you have two different environments to think about: what I shall call the DSL processor and the target environment. The DSL processor is where the parser, Semantic Model, and the code generator live. This needs to be a comfortable environment to develop these things. The target environment is your generated code and its surroundings. The point of using code generation is to separate the target environment from your DSL processor because you can’t reasonably build the DSL processor in the target environment.
Target environments come in various guises. One case is an embedded system where you don’t have the resources to run a DSL processor. Another is where the target environment needs to be a language that isn’t suitable for DSL processing. Ironically, the target environment may itself be a DSL. Since DSLs have limited expressiveness, they usually don’t provide abstraction facilities that you need for a more complex system. Even if you could extend the DSL to give you abstraction facilities, that would come at the price of complicating the DSL—perhaps enough to turn it into a general-purpose language. So, it can be better to do that abstraction in a different environment and generate code in your target DSL. A good example of this is specifying query conditions in a DSL and then generating SQL. We might do this to allow our queries to run efficiently in the database, but SQL isn’t the best way for us to represent our queries.
Limitations of the target environment aren’t the only reason to generate code. Another reason may be the lack of familiarity with the target environment. It may be easier to specify behavior in a more familiar language and then generate the less familiar one. Another reason for code generation is to better enforce static checking. We might characterize the interface of some system with a DSL, but the rest of the system wishes to talk to that interface using C#. In this case, you might generate a C# API so that you get compile-time checking and IDE support. When the interface definition changes, you can regenerate the C# and have the compiler help you identify some of the damage.
8.1 Choosing What to Generate
One of the first things to decide when generating code is, what kind of code are you going to generate? The way I look at things, there are two styles of code generation you can use: Model-Aware Generation and Model Ignorant Generation. The difference between the two lies in whether or not you have an explicit representation of the Semantic Model in the target environment.
As an example, let’s consider a State Machine. Two classic alternatives for implementing a state machine are nested conditionals and state tables. If we take a very simple state model, such as Figure 8.1, a nested conditional approach would look like this:
Figure 8.1 A very simple state machine


We have two conditional tests nested one inside the other. The outer conditional looks at the current state of the machine and the inner conditional switches on the event that’s just been received. This is Model Ignorant Generation because the logic of the state machine is embedded into the control flow of the language—there’s no explicit representation of the Semantic Model.
With Model-Aware Generation we put some representation of the semantic model into the generated code. This needn’t be exactly the same as that used in the DSL processor, but it will be some form of data representation. For this case, our state machine is a touch more complicated.
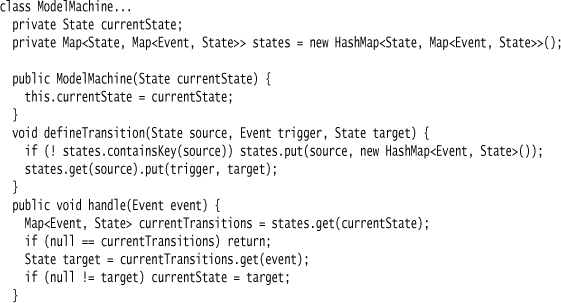
Here I’m storing the transitions as nested maps. The outer map is a map of states, whose key is the state name, and value is a second map. This inner map has the event name as the key and the target state as the value. This is a crude state model—I may not have explicit state, transition, and event classes—but the data structure captures the behavior of the state machine. As a result of being data-driven, this code is entirely generic and needs to be configured by some specific code to make it work.
modelMachine = new ModelMachine(OFF);
modelMachine.defineTransition(OFF, UP, ON);
modelMachine.defineTransition(ON, DOWN, OFF);
By putting a representation of the Semantic Model into the generated code, the generated code takes on the same split between generic framework code and specific configuration code that I talked about in the introduction. Model-Aware Generation preserves the generic/specific separation while the Model Ignorant Generation folds the two together by representing the Semantic Model in control flow.
The upshot of this is that if I use Model-Aware Generation, the only code I need to generate is the specific configuration code. I can build the basic state machine entirely in the target environment and test it there. With Model Ignorant Generation, I have to generate much more code. I can pull out some code into library functions which don’t need to be generated, but most of the critical behavior has to be generated.
As a result, it’s much easier to generate code using Model-Aware Generation. The generated code is usually very simple. You do have to build the generic section, but since you can run and test it independently of the code generation system, this usually makes it much easier to do.
My inclination, therefore, is to use Model-Aware Generation as much as possible. However, often it isn’t possible. Often, the whole reason for using code generation is that the target language can’t represent a model easily as data. Even if it can, there may be processing limitations. Embedded systems often use Model Ignorant Generation because the processing overhead of code generated with Model-Aware Generation would be too great.
There’s another factor to bear in mind if it’s possible to use Model-Aware Generation. If you need to change the specific behavior of the system, you can replace only the artifact corresponding to the configuration code. Imagine we’re generating C code; we can put the configuration code into a different library than the generic code—this would allow us to alter the specific behavior without replacing the whole system (although we’d need some runtime binding mechanism to pull this off).
We can go even further here and generate a representation that can be read entirely at runtime. We could generate a simple text table, for example:
off switchUp on
on switchDown off
This would allow us to change the specific behavior of the system at runtime, at the cost of the generic system having the code to load the data file at startup.
At this point, you’re probably thinking that I’ve just generated another DSL which I’m parsing in the target environment. You could think of it this way, but I don’t. To my mind, the little table above isn’t really a DSL because it isn’t designed to be for human manipulation. The textual format does make it human-readable, but that’s more of a useful feature for debugging. It’s primarily designed to make it really easy to parse, so we can quickly load it into the target system. When designing such a format, human readability comes a distant second to simplicity of parsing. With a DSL, human readability is a high priority.
8.2 How to Generate
Once you’ve thought about what kind of code to generate, the next decision is how to go about the generation process. When generating a textual output, there are two main styles you can follow: Transformer Generation and Templated Generation. With Transformer Generation, you write code that reads the Semantic Model and generates statements in the target source code. So for the states example, you might get hold of the events and generate the output code to declare each event, likewise with the commands, and again for each state. Since the states contain transitions, your generation for each state would involve navigating to the transitions and generating code for each of these too.
With Templated Generation, you begin by writing a sample output file. In this output file, wherever there is something specific to a particular state machine, you place special template markers that allow you to call out to the Semantic Model to generate the appropriate code. If you’ve done templated web pages with tools like ASP, JSP, and the like, you should be familiar with this mechanism. When you process the templates, it replaces the template references with generated code.
With Templated Generation, you are driven by the structure of your output. With Transformer Generation, you may be driven by either input, output, or both.
Both approaches to code generation work well, and to choose between them, you’re usually best off to experiment with each and see which one seems to work best for you. I find that Templated Generation works best when there’s a lot of static code in the output and only a few dynamic bits—particularly since I can look at the template file and get a good sense of what gets generated. As a consequence of this, I think you’re more likely to use Templated Generation if you are using Model Ignorant Generation. Otherwise—actually, most of the time—I like Transformer Generation.
I’ve discussed these as opposite approaches, but that doesn’t mean you can’t mix them. Indeed, usually you do. If you’re using Transformer Generation, you’ll probably use string format statements to write out a little chunk of code—and these are miniature cases of Templated Generation. Despite this, I think it’s useful to have a clear idea of what your overall strategy is and be conscious about switching over. As with most things involving programming, the moment you stop being thoughtful about what you are doing is the moment when you start making an unmaintainable mess.
One of the biggest problems in using Templated Generation is that the host code used to generate variable output may start to overwhelm the static template code. If you’re generating Java to generate C, you want the template to be mostly C and minimize any Java in the template. I find Embedment Helper a vital pattern here. All the complexity of figuring out how to generate the variable elements of the template should be hidden in a class that’s called by simple method calls in the template. That way you only have the bare minimum of Java in your C.
Not only does this keep your template clear, it usually also makes it easier to work with your generation code. The Embedment Helper can be a regular class, edited with tools that are aware they are editing Java. With sophisticated IDEs, this makes a big difference. If you embed a lot of Java in a C file, the IDEs usually can’t help you. You may not even get syntax highlighting. Each callout in a template should be a single method call; anything else should be inside the Embedment Helper.
A good example of where this is important is the grammar files for Syntax-Directed Translation. I’ve often come across grammar files that are full of long code actions, essentially blocks of Foreign Code. These blocks are woven into the generated parser, but their size buries the structure of the grammar; an Embedment Helper helps a great deal by keeping the code actions small.
8.3 Mixing Generated and Handwritten Code
Sometimes you can generate all the code that needs to execute in the target environment, but more often than not, you will mix generated and handwritten code.
The general rules to follow here are:
• Don’t modify generated code.
• Keep generated code clearly separate from handwritten code.
The point of using code generation from a DSL is that the DSL becomes the authoritative source for that behavior. Any generated code is just an artifact. If you go in and manually edit the result of the code generation, you’ll lose those changes when you regenerate. This causes extra work on generation, which is not just bad in its own right but also introduces a reluctance to change the DSL and generate when necessary, undermining the whole point of having a DSL. (It is sometimes useful to generate a scaffold to get you started on handwritten code, but that’s not the usual situation with DSLs.)
As a result, any generated code should never be touched by hand. (One exception is inserting trace statements for debugging.) Since we want them to never be touched, it makes sense to keep them apart from the handwritten code. My preference is to have files clearly separated into all-generated or all-handwritten. I don’t check generated code into a source code repository, since it can be regenerated at will during the build process. I prefer to keep generated code in a separate branch of the source code tree.
In a procedural system, where the code is organized into files of functions, this is pretty easy to achieve. However, object-oriented code, with classes that mix data structure and behavior, often complicates this separation. There are plenty of times where you have one logical class, but some parts of the class need to be generated and some handwritten.
Often, the easiest way to handle this is to have multiple files for your class; you can then split the generated and handwritten code up as you wish. However, not all programming environments allow this. Java does not, recent versions of C# do—under the name of “partial classes.” If you’re working with Java, you can’t simply split the files in a class.
One popular option was to mark separate areas of the class as generated or handwritten. I always found this a clunky mechanism, one that often leads to mistakes as people edit the generated code. It also usually means that it’s impossible to avoid checking in generated code—which confuses the version control history.
A good solution to this is Generation Gap where you split generated and handwritten code using inheritance. In the basic form, you generate a superclass and handwrite a subclass which can augment and override generated behaviors. This keeps the file separation between generated and handwritten code while allowing a lot of flexibility in combining both styles in a single class. The disadvantage is that you need to relax visibility rules. Methods that might otherwise be private have to be relaxed to protected to allow overriding and calling from a subclass. I find such relaxation a small price to pay for keeping the generated and handwritten code separate.
The difficulty of keeping the generated and handwritten code separate seems to be proportional to the pattern of calls between generated and handwritten code. A simple flow of control, such as Model Ignorant Generation where the generated code calls handwritten code in a one-way flow, makes it much easier to separate the two artifacts. So, if you have difficulty keeping handwritten and generated code separate, it may be worth thinking about ways to simplify the control flow.
8.4 Generating Readable Code
A tension that comes out from time to time when talking about code generation is how readable and well-structured you need to make the generated code. The two schools of thought are those that think that generated code should be as clear and readable as handwritten code, and those that feel that such concerns are irrelevant for generated code, since it should never be modified by hand.
In this debate, I lean towards the group that says that generated code should be well-structured and clear. Although you shouldn’t ever have to hand-edit generated code, there will be occasions where people will want to understand how it works. Things will go wrong and require debugging, and then it’s much easier to debug clear, well-structured code.
Therefore, I prefer to generate code almost as good as that I would write by hand—with clear variable names, good structure, and most of the habits I use normally.
There are exceptions. Perhaps the primary exception is that I’m less concerned if it’s going to take extra time to get the right structure. I’m less inclined to spend the time to figure out or create the best structure with generated code. I worry less about duplication; I don’t want the obvious and easy-to-avoid duplication, but I don’t stress about it to the degree I do with handwritten code. After all, I don’t have to worry about the modifiability, only the readability. If I think some duplication is clearer, I’ll certainly leave it in. I’m also happier to use comments, since I can ensure that generated comments are kept up-to-date with generated code. Comments can refer back to structures in the Semantic Model. I’ll also compromise clear structure to meet performance goals—but that’s true for handwritten code too.
8.5 Preparse Code Generation
Through most of this section, I’ve concentrated on code generation as the output of the DSL script, but there is another place where code generation can play a role. In some cases, you need to integrate with some external information when writing your DSL script. If you are writing a DSL about linking territories for salespeople, then you might want to coordinate with a corporate database used by salespeople. You may want to ensure that the symbols you use in your DSL scripts match those in the corporate database. One way of doing this is to use code generation to generate information you need while writing your scripts. Often, this kind of checking can be done when populating the Semantic Model, but there are times when it’s useful to have the information in source code too, particularly for code navigation and static typing.
An example of this would be where you are writing an internal DSL in Java/C# and you want your symbols that refer to salespeople to be statically typed. You can do this by code-generating enums to list your salespeople and importing those enums into your script files [Kabanov et al.].
8.6 Further Reading
The most extensive book available on code generation techniques is [Herrington]. You may also fine Marcus Voelter’s set of patterns in [Voelter] useful.