
Foreign tables exist as empty shells on the local database, lending merely their structure for query-planning and data-fetching purposes. The foreign data wrapper transforms data requests to something the remote server can understand and presents it in a way PostgreSQL will recognize.
As we're using the postgres_fdw wrapper, the situation is simplified. A PostgreSQL server should have less trouble communicating with another PostgreSQL server than an Oracle server, for instance. Though this means less transformation, there are still limitations to what functionality a foreign table might provide compared to a local table.
In this recipe, we'll use a foreign table in a few scenarios and examine how it performs in each. We'll also explore some of the common caveats involved in foreign table access.
As we will be using the pgbench_accounts foreign table in this recipe, please follow all the previous recipes before proceeding.
All queries in this recipe should be performed by the bench_user mapped user in the pgbench database on the pg-report PostgreSQL server. Follow these steps:
- Execute the following simple query to view a remote query plan:
EXPLAIN VERBOSE SELECT aid, bid, abalance FROM pgbench_accounts WHERE aid BETWEEN 500000 AND 500004;
- Execute this SQL statement to examine how PostgreSQL handles remote aggregates:
EXPLAIN VERBOSE SELECT sum(abalance) FROM pgbench_accounts WHERE aid BETWEEN 500000 AND 500004;
- Execute this SQL statement to see a query plan involving a
JOIN:EXPLAIN VERBOSE SELECT a2.aid, a2.bid, a2.abalance FROM pgbench_accounts a1 JOIN pgbench_accounts a2 USING (aid) WHERE a1.aid BETWEEN 500000 AND 500004
The first query is very simple. We only fetch the five inclusive records from 500,000 to 500,004. We chose these values because they are so far into the table that scanning to find them would be very slow. This encourages the remote system to use the index on the aid column, and we can easily tell if it does not.
As we used EXPLAIN VERBOSE, PostgreSQL reports the query it would have performed on the remote server as well. This is how the full explain looks on our test server:
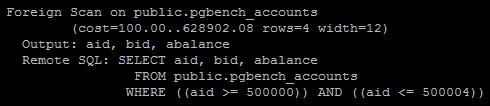
PostgreSQL tries to send WHERE clauses to the remote server when possible. We can see from the Remote SQL lines that aside from some inconsequential transformations, it sent the entire query to the remote server unaltered.
In the next query, we made a very minor change that should have caused the remote server to aggregate the abalance column as a sum and send it back to us. However, the current foreign data wrapper API included with PostgreSQL 9.3 cannot handle aggregates of any kind. Again, let's see the actual output on our test system:
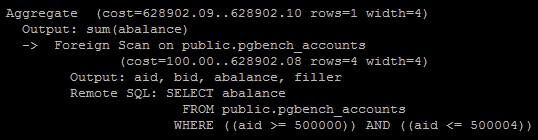
What happened here? The Remote SQL that PostgreSQL sent to the remote server includes no sum aggregate at all. This means that PostgreSQL fetches all five rows before producing a sum for us. This is probably OK for such a small amount of data, but consider the overhead involved if we had wanted a sum of a million rows.
All of these rows must be fetched from storage, sent over the network, received, and then summarized into an aggregate locally. The situation becomes even more dire when we try to join two foreign tables. We only have the pgbench_accounts table, so we joined it with itself. The query still only asks for five rows, and both of its inputs are on the remote server, so we might expect the remote server to perform the join.
This expectation would be wrong. To illustrate, here's the EXPLAIN output for the last query on our test server:
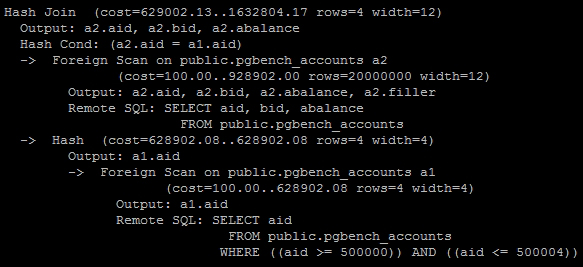
Don't worry too much about most of this output. Simply direct your attention to both of the Remote SQL sections. First, observe that there are two of these sections. This means our single query was transformed into two remote queries. Next, notice that one of the queries has no WHERE clause and is fetching all 200 million of the rows in pgbench_accounts.
The foreign data wrapper is literal in its interpretation of our WHERE clause. We supplied one WHERE clause for the first instance of pgbench_accounts, and in normal circumstances, this would be enough. Unfortunately, search conditions are not transitive when foreign tables are concerned. One of the queries returns five rows as we expected, while the other must process 200 million rows to find the matching aid values for those five rows.
Foreign tables are very powerful, but they must be used judiciously. Failing to observe the previous lessons will result in the same scenarios, or worse.
There's actually a very simple reason PostgreSQL is failing our expectations in the last two of our query examples. The answer lies in the structure of foreign tables themselves. When we defined the pgbench_accounts table, we specified four column names. PostgreSQL expects to see one or more of those column names within the SELECT clause in every interaction with the foreign table.
The second query example changes the SELECT clause to read sum(abalance). While the abalance column is part of our foreign table definition, sum is not. A functional transformation of any kind renders the column mappings moot, and PostgreSQL must apply them after data is retrieved from the remote server.
The third query example performs badly for a different reason. If we ignore the problem with the nontransitive WHERE clause, there's still another issue. We could add another WHERE clause for the second instance of pgbench_accounts in that query, but as the EXPLAIN output shows, we would still be executing two queries on the remote server instead of one.
This is due to how PostgreSQL currently handles foreign data. If we imagine the postgres_fdw wrapper as a worker carrying a large box, every box requires a new worker. In this scenario, every foreign table is a box, and every box is separate. Each time PostgreSQL encounters a foreign table, it dispatches a worker with his box and waits for the results. As JOIN is a distinctly separate action, we get two workers and two boxes.
This may change in the future, but for now, this means that the remote server cannot combine requests for foreign tables.