
Now that we have a working Pacemaker cluster-management system, we should put it to use. There are a lot of scenarios where we might need to manually change the active PostgreSQL node. Doing this with Pacemaker is much easier than the process we outlined in the previous chapter. That was a long process composed of several manual steps, each of which we would want to confirm in a perfect world.
With Pacemaker, we can change the active system by issuing a single command from any node in the cluster. There are some safeguards we'll also need to discuss and possibly a caveat or two to consider, but this will be our first use of Pacemaker as a piece of functional software. We've done a lot of work setting everything up!
Let's make Pacemaker do some work on our behalf for a change.
In order to migrate resources from one node to another, we need a fully functional Pacemaker cluster that manages all of our software layers. Make sure you've followed all the previous recipes before continuing.
This recipe will assume pg1 is currently the active node, and we want to move PostgreSQL to pg2. Perform these steps on either Pacemaker node as the root user:
- Initiate the migration with
crm:crm resource migrate PGServer pg2 - Remove the continued forced migration with this command:
crm resource unmigrate PGServer - Use
crmto display the currently active node:crm resource status PGServer
The process is as simple as we claimed. We can launch a migration by specifying resource migrate as our primary crm arguments. There are only two remaining parameters for us to set: the resource we want to migrate and the target location. The PGServer group represents PostgreSQL and all of its prerequisite storage elements, so that is our third parameter.
The last parameter is the target node, and as pg2 is the only other node in this Pacemaker configuration, it's an easy choice. What happens during a migration? The following is a screenshot of crm_mon during a migration:
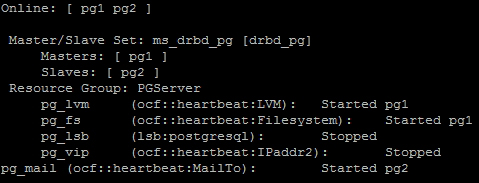
As you can see, Pacemaker is doing just as we claimed in the previous section and is shutting down PGServer resources in reverse order. It has already stopped pg_vip and pg_lsb and will shortly proceed to the rest of the services. In fact, here is a full ordered list of what Pacemaker does during a migration with our configuration:
- Create a rule with an infinite score that the
PGServergroup should be running onpg2. - Stop the
pg_mailalert onpg1, causing an e-mail alert. - Start the
pg_mailresource onpg2. - Stop the
pg_vipresource onpg1. - Stop the
pg_lsbresource onpg1. - Stop the
pg_fsresource onpg1. - Stop the
pg_lvmresource onpg1. - Demote
ms_drbd_pgtoSecondaryonpg1. - Promote
ms_drbd_pgtoPrimaryonpg2. - Start the
pg_lvmresource onpg2. - Start the
pg_fsresource onpg2. - Start the
pg_lsbresource onpg2. - Start the
pg_vipresource onpg2.
We hope you can see the obvious linear progression Pacemaker is following, mirrors the process we used when we performed these tasks manually. After the migration is over, we call unmigrate to remove the infinite score that Pacemaker added. This way, PGServer can remain on pg1 again in the future.
Our final step is to examine the resource status of the PGServer group itself. If we did our job right, we should see this output:
Pacemaker reports that PGServer is running on pg2, just as we asked.
When we call crm resource migrate, Pacemaker merely' but makes a simple configuration change. As the PGServer resource is running on pg1 and we set stickiness to 100, any score higher than that will override the current (and preferred) node.
When we ask for a migration, Pacemaker sets the node score for pg2 at the highest value possible. The next time the resource target evaluation system runs, it sees that the score has changed and starts reorganizing the cluster to match. It's actually quite elegant. Unfortunately, it means that we need to remove the score, or we could be in trouble later.
When we unmigrate the PGServer group, Pacemaker removes the infinite score assigned to pg2, leaving it with the regular score of 100. This is enough to keep PGServer attached to pg2, but nothing more. This is important because the score is absolute.
Imagine if the rule was still in place and Pacemaker vastly preferred pg2 over pg1. In the event pg2 crashes, Pacemaker will dutifully move PostgreSQL over to pg1. This is exactly what we want. However, what happens after we fix pg2 and reattach it to Pacemaker? That's right; the infinite score means Pacemaker will move it to pg2 immediately. Oh no!