
To avoid potential conflicts, we will continue to add resources to Pacemaker in the same order as if we were starting them manually. After DRBD comes our second LVM layer. The primary purpose of Pacemaker in this instance is to activate or deactivate the VG_POSTGRES volume group that we created in the previous chapter.
This is necessary because DRBD can not demote a primary resource to secondary status as long as there are any open locks. Any LVM volume group that contains active volumes can cause these kind of locks. Also, we cannot utilize a volume group that has no active volumes when DRBD is promoted on the second node.
This recipe will explain the steps necessary to manage our VG_POSTGRES/LV_DATA data volume with Pacemaker.
As we're continuing to configure Pacemaker, make sure you've followed all the previous recipes.
Perform these steps on any Pacemaker node as the root user:
- Add an LVM
primitiveto Pacemaker withcrm:crm configure primitive pg_lvm ocf:heartbeat:LVM params volgrpname="VG_POSTGRES" op start interval="0" timeout="30" op stop interval="0" timeout="30"
- Clean up any errors that might have accumulated with
crm:crm resource cleanup pg_lvm - Display the status of our new LVM resource with
crm:crm resource status
As with the previous recipe, we begin by adding a primitive to Pacemaker. For the sake of consistency and simplicity, we name this resource pg_lvm. In order to manage LVM, we also need to specify the ocf:heartbeat:LVM resource agent.
The only parameter (params) that concerns us regarding the LVM resource agent is volgrpname, which we set to VG_POSTGRES. The other options we set are more advisory minimum values, which reflect the number of seconds we should wait before considering an operation as failed.
In our case, we wait 30 seconds before declaring a start or stop ping a failed action. If Pacemaker is unable to start LVM, it will attempt to do so on other available nodes. In the event where Pacemaker can't stop LVM, it will report an error and perform no further actions until the error is cleared or corrected.
Speaking of clearing errors, it's a good practice to perform a resource cleanup after adding a new resource to Pacemaker. While not strictly required, this keeps the status output clean and ensures that Pacemaker will add the next resource as expected. Sometimes, Pacemaker will refuse to perform further actions if the error list contains any entries.
As we will do with all recipes in this chapter, our last action is to view the status of the resources to prove that the new addition is listed. Our test server shows that it is:
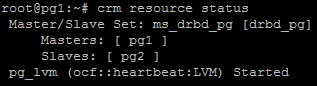
Now, in addition to the ms_drbd_pg resource that represents drbd_pg, we can see the new pg_lvm resource. Pacemaker also checked the status of LVM and displays it as Started.
If you're tired of always checking the status of Pacemaker manually, there is a tool we can use instead. Much like top, which displays the current list of running processes, the crm_mon command monitors the status of a Pacemaker cluster and prints the same output as crm status. For our cluster in its current state, it looks like this:
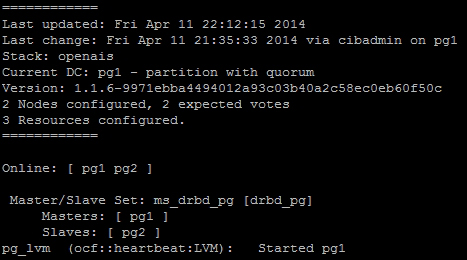
This will refresh regularly and makes it easy to watch live transition states as Pacemaker performs actions related to cluster management. Feel free to keep this running in another terminal window for the sake of convenience.