
Highly available databases often come in pairs for redundancy purposes. These servers can have any number of procedures to keep the data synchronized, and this book suggests direct connections when possible. Direct connections between servers ensure fast communication between redundant servers, and it resembles the following network design:
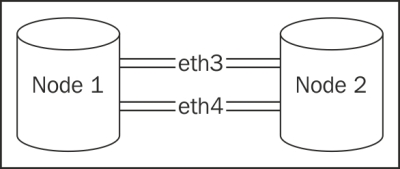
In some cases, it can be advantageous to connect the database servers to a general network fabric. Depending on the interaction of the upstream network devices, this can significantly increase the network packet's round-trip-time (RTT). This is usually fine for PostgreSQL replication, but OLTP systems may be more sensitive. Block-level replication systems, such as DRBD, which operate beneath the filesystem, fare even worse.
Each of our database servers should be equipped with at least two independent network interfaces. In order to prevent downtime, these interfaces must be linked with a bond. Network bonds act as an abstract layer that can route traffic over either interface, and like many kernel-level services, bond status can be checked via the Linux /proc filesystem.
The health and current communication channel of the server network bond is surprisingly relevant to throughput. In order to rule out potential delays caused by upstream network hardware, we need to understand how the bond is operating.
As we are going to examine the network bond on two paired PostgreSQL servers, connect to each before continuing. We don't need any special permissions or attributes for this recipe.
In order to check the status of the network bond, follow these steps:
- Determine the current bonding method by executing this command:
grep Mode /proc/net/bonding/bond0 - Check the currently active interface with this command:
grep Active /proc/net/bonding/bond0
Surprised that it's so simple? Don't be. Much like /proc/meminfo and /proc/cpuinfo, the difficulty is not in obtaining the information we need, but in interpreting it. The first thing that concerns us is the bond mode. There are several modes, but only one is relevant to us for a dual-failover configuration. The mode should reflect some kind of an active-backup status; otherwise, it's combining the interfaces for bandwidth and throughput purposes. The line we want looks like this:
Bonding Mode: fault-tolerance (active-backup)
Next, we check the currently active interface. If the system was configured so that the network bond is in active-backup mode, only one is active at any one time. The other serves act as a backup in case the network connection or the interface itself fails. In an ideal situation, similar interfaces on both servers—eth3, for instance—are attached to the same switch. If not, we should talk to our network and server administrators to correct the setup.
We suggest that you use the same interface name on both the servers for one simple reason: it's difficult to diagnose network routes on bonded interfaces. For best throughput and RTT, our network should look like this:
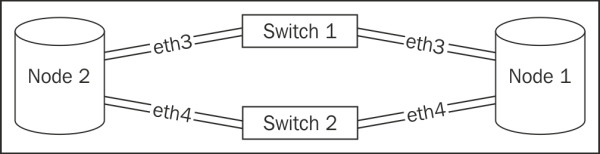
We hope it's clear from the diagram that this architecture introduces a possible source of network lag. As the servers cannot transfer data to each other directly, at least one extra switch that increases the RTT is involved. As our servers hopefully have two network interfaces, each server is communicating with the same two switches. However, if each server is currently working through a different switch, this actually adds at least two more jumps, as the switches must communicate with an upstream router. If we follow the dotted path, that unfortunate situation looks like this:
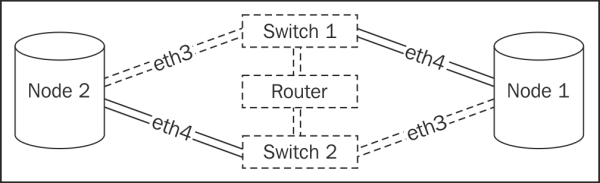
We've seen this increase ping time from 0.03 ms to 0.3 ms. This may not seem like much, but when the network RTT is 10 times slower, replication and monitoring can suffer significantly. This is one of the few obscure troubleshooting techniques that can elude even experienced network administrators. Armed with this, we should be able to diagnose replication and idle-wait problems using nothing more than grep.
- By their nature, networks are standardized to encourage intercommunication. As a result of this, link aggregation (bonding) is available on Wikipedia as a standard term. If you want to learn more about how it works, please visit the longer explanation on Wikipedia at http://en.wikipedia.org/wiki/Link_aggregation.