
The final important aspect of database sharding that we are going to explore in this chapter is reorganization. The purpose of allocating a large number of logical shards is to prepare for future expansion needs. If we started with 2048 shards, all of which are currently mapped to a single server, we will eventually want to move some of them elsewhere.
The easiest way to do this is to leverage PostgreSQL replication. Essentially, we will create a streaming replica for the server we want to split and drop the schemas we don't need on each server. Consider a database with two shards. Our end goal is to produce something like this:
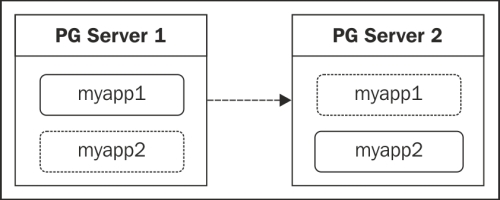
On each server, we simply drop the schema indicated by the dashed box. This way, we still have two shards, and only the location of myapp2 has changed; its data remains unharmed.
This recipe will cover the process described here, making it easy to move shards to a new physical location.
This recipe depends on the work we performed in the Creating a scalable nextval replacement and Talking to the right shard recipes. Please review these recipes before continuing.
In addition to our usual pg-primary PostgreSQL server, we will also be using pg-primary2 for this recipe. Database data will remain in the /db/pgdata directory. A server named pg-shared will play the role of our shared database as well. Follow these steps as the postgres system user and postgres database user where indicated:
- Use
pg_basebackuponpg-primary2to clone the data frompg-primary:pg_basebackup -h pg-primary -D /db/pgdata - Create a file named
recovery.confin/db/pgdataonpg-primary2with these contents:standby_mode = 'on' primary_conninfo = 'host=pg-primary user=postgres'
- Start PostgreSQL on
pg-primary2:pg_ctl -D /db/pgdata start - When ready to split the shards, promote
pg-primary2to master status:pg_ctl -D /db/pgdata promote - Execute this SQL statement on
pg-sharedto change the shard mapping:UPDATE shard.shard_map SET server_name = 'pg-primary2' WHERE shard_schema = 'myapp2';
- Refresh any cached copies of the
shard_maptable. - Drop the
myapp2schema onpg-primary:DROP SCHEMA myapp2;
- Drop the
myapp1schema onpg-primary2:DROP SCHEMA myapp1;
We've already discussed the process to create streaming replicas several times through this book, so we've elected to use a shortened version here. Our primary goal here is to create a full database clone of pg-primary on pg-primary2. This clone should continue to receive data from pg-primary until we are ready to split up our application data. When database activity is low or we can temporarily disable write activity to the myapp2 schema, we can promote pg-primary2 so that it acts as a writable server.
Once pg-primary2 is writable, we execute an UPDATE statement on the shard_map table in pg-shared. Then, we either refresh or invalidate cached copies of that table so that they are rebuilt. From this point on, all new requests to interact with data stored in the myapp2 shard will be directed to the pg-primary2 server.
With the myapp2 shard's physical location changed and caches updated, it should be safe to drop the unneeded schemas on each PostgreSQL server. The pg-primary server is only in charge of the myapp1 shard now, so we can drop myapp2. Similarly, the pg-primary2 server is only handling the myapp2, so we can drop myapp1.
If our data was evenly distributed, each PostgreSQL server should now be half the size of what pg-primary originally was. Furthermore, database load, IOPS and TPS requirements, and other metrics are also scaled down. By doubling our server count, we've cut our hardware needs in half and have thereby increased our query response times and availability.
Though our example used only two schema shards, this process scales well to any number of preallocated shards. It's surprisingly easy to relocate schemas using the method described here, and there's no reason we must limit ourselves to splitting one server into only two. The only real limitation is that we can't effectively recombine servers once they've been split this way.
There is, however, one important caveat we must explain. This type of database sharding works best when the application is designed to accommodate it. In fact, it's even better to create all of the logical shards upfront, before data is inserted into any shard. Why is this?
Consider an existing schema with existing data. Foreign keys, customers, and customer activity has been accumulating for years. Redistributing this data into all of the necessary tables of our shard schemas will be extremely difficult and will likely be an entirely manual migration process.
This same problem exists if we only start our application with a small number of shards instead of allocating the maximum from the beginning. If we only have four out of 2048 active shards and they're already on four physical servers, we will need to create new shards and manually distribute the data once again.
However, we can also start with all 2048 shards at the beginning. From the very start, customers are assigned to shards, and data is inserted to the proper shard. Even if all shards start on one server, we can expand using the method described in this recipe. If we want to immediately grow to four servers, we merely create three clones and evenly distribute the shards to each system.
It's important to advocate and impose this architecture early in systems that are likely to require high transactional volume. Otherwise, the path to horizontal scalability and the availability associated with it will be a long and hard one.