
In this chapter, we will learn to combine and abstract connectivity to isolate and protect the database. We will cover the following recipes in this chapter:
- Determining connection costs and limits
- Installing PgBouncer
- Configuring PgBouncer safely
- Connecting to PgBouncer
- Listing PgBouncer server connections
- Listing PgBouncer client connections
- Evaluating PgBouncer pool health
- Installing pgpool
- Configuring pgpool for master/slave mode
- Testing a write query on pgpool
- Swapping active nodes with pgpool
- Combining the power of pgBouncer and pgpool
Abstraction can protect a database from even the busiest platform. At the time of writing this book, applications and web services often involve hundreds of servers. If we follow a simple and naïve development cycle where applications have direct access to the database, each of these servers may require dozens of connections per program, even with a small server pool that can result in hundreds or thousands of direct connections to the database. Is this what we want? Consider the scenario illustrated in the following diagram:

We need a way to avoid overwhelming the database with the needs of too many clients. As we suggested in the previous chapter, a PostgreSQL server experiences its best performance when the amount of active connections is less than three times the available CPU count. With a thousand incoming client connections, we will need hundreds of CPU cores to satisfy the formula.
Every incoming connection requires resources such as memory for query calculations and results, file-handle and port allocations for network traffic, process management, and so on. In addition, each connection is another process the OS has to schedule for CPU time. Very large servers are extremely capable, but resources are not infinite. Even if the database can handle thousands of connections, performance will suffer for each in excess of design capacity. We need to change the map to something slightly different, as seen here:
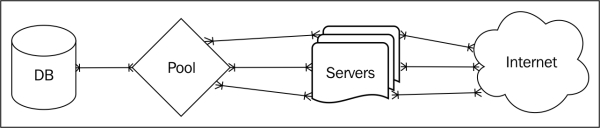
By inserting a connection pool in front of the database, hundreds of PostgreSQL server processes are reduced to dozens. A database pool works by recycling database connections as soon as the client completes its current transaction or when its database work is complete. Instead of hundreds of mostly idle database connections, we maintain a specific set of highly active connections.
Two popular tools for PostgreSQL that provide pooling capability are pgBouncer and pgpool. In this chapter, we will explore how to use these services properly and reduce overhead and database availability.