
In this chapter, we will mainly discuss the following topics:
- Introducing speech recognition, synthesis, and various speech processing frameworks
- Working with speech recognition and synthesis using Python in Ubuntu/Linux, Windows and Mac OS X
- Working with speech recognition and synthesis packages in ROS using Python
If the robots are able to recognize and respond the way human beings communicate, then the robot-human interaction will be much more easier and effective than any other method. However, extracting speech parameters such as meaning, pitch, duration, and intensity from human speech is a very tough task. Researchers found numerous ways to solve this problem. Now, there are some algorithms that are doing a good job in speech processing.
In this chapter, we will discuss the applications of speech recognition and synthesis in our robot and also look at some of the libraries to perform speech recognition and synthesis.
The main objective of speech synthesis and recognition system in this robot is to make the robot-human interaction easier. If a robot has these abilities, it can communicate with the surrounding people and they can ask various questions about the food and the cost of each item. The speech recognition and synthesis functionality can be added using the framework that we will discuss in this chapter.
In the first section of this chapter, you will learn about the steps involved in speech recognition and synthesis.
Speech recognition basically means talking to a computer and making it recognize what we are saying in real time. It converts natural spoken language to digital format that can be understood by a computer. We are mainly discussing the conversion of speech-to-text process here. Using the speech recognition system, the robot will record the sentence or word commanded by the user. The text will be passed to another program and the program will decide which action it has to execute. We can take a look at the block diagram of the speech recognition system that explains how it works.
The following is a block diagram of a typical speech recognition system. We can see each block and understand how a speech signal is converted to text:
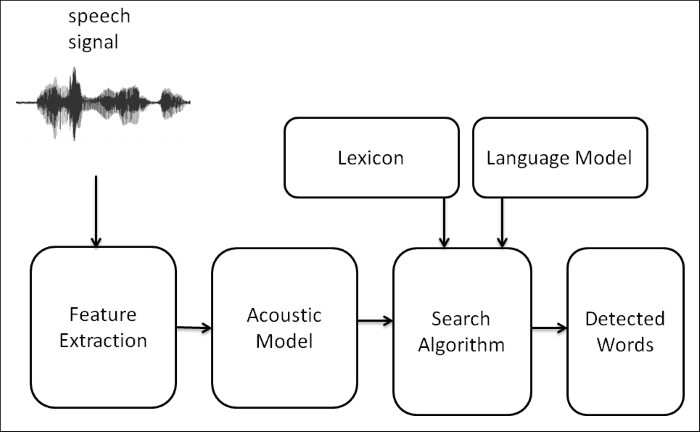
Speech recognition system block diagram
The speech signal is received through a microphone and will be converted to a digital format such as PCM (Pulse Code Modulation) by the sound card inside the PC. This digital format can be processed by the software inside the PC. In a speech recognition process, the first phase is to extract the speech features from the digital sound format.
In the speech recognition system, the following are the common components:
- Feature extraction: In this process, the raw digital sound is converted to sound feature vectors, which carry information of sounds and suppress the irrelevant sources of sound. The sound feature vectors can be mathematically represented as a vector with respect to time. After getting the sound feature vectors, they will be decoded to text from a list of possible strings and selected according to its probability.
- Acoustic model: The first stage of decoding is acoustic models. Acoustic models are trained statistical models and are capable of predicting the elementary units of speech called phonemes after getting the sound feature vectors. Popular acoustic modeling in speech recognition is HMM (Hidden Markov Models) and another hybrid approach is to use artificial neural networks.
- Lexicon: A lexicon (also known as dictionary) contains the phonetic script of words that we use in training the acoustic model.
- Language model: This provides a structure to the stream of words that is detected according to the individual word probability. The language model is trained using large amounts of training text (which includes the text used to train the acoustic model). It helps to estimate the probabilities and find the appropriate word detected.
- Search algorithm: This is used to find the most probable sequence of words in the sound vectors with the help of the language model and lexicon.
- Recognized words: The output of the search algorithm is a list of words that has the highest probability for given sound vectors.
The following are some good and popular implementations of speech recognition algorithms in the form of libraries.
Sphinx is a group of speech recognition tools developed by Carnegie Mellon University. The entire library is open source and it comes with acoustic models and sample applications. The acoustic model trainer improves the accuracy of detection. It allows you to compile its language model and provides a lexicon called cmudict. The current Sphinx version is 4. The Sphinx version customized for an embedded system is called Pocket Sphinx. It's a lightweight speech recognition engine that will work on desktop as well as on mobile devices. Sphinx libraries are available for Windows, Linux, and Mac OS X.
There are Python modules available to handle Pocket Sphinx APIs from Python. The following is the official website of CMU Sphinx:
This is a high performance and continuous speech recognition library based on HMM and can detect continuous stream of words or N-grams. It's an open source library that is able to work in real time. There are Python modules to handle Julius functions from Python. Julius is available in Windows, Linux, and Mac OS X. The official website of Julius is:
Microsoft provides a SDK to handle speech recognition and synthesis operation. SDK contains APIs to handle speech-related processing that can be embedded inside the Microsoft application. The SDK only works on Windows and it has some ports for Python like the PySpeech module. These speech APIs are comparatively accurate than other open source tools.
Speech synthesis is the process of converting text data to speech. The following block diagram shows the process involved in converting text to speech:
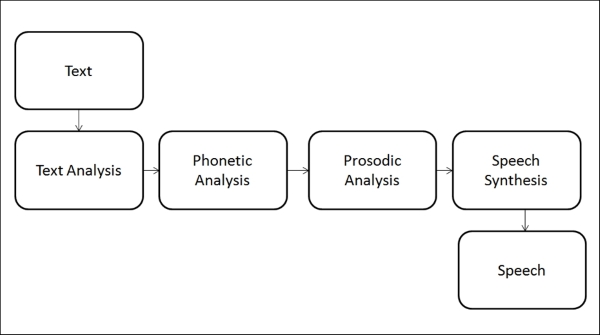
Block diagram of speech synthesis process
For more details, refer to page 6 of Spoken Language Processing, X. Huang, A. Acero, H.-W. Hon, Prentice Hall PTR, published in 2001.
Let us take a look at the speech synthesis stages:
- Text analysis: In text analysis, the text to be converted to speech will check for the structure of text, linguistic analysis, and text normalization to convert numbers and abbreviations to words
- Phonetic analysis: In phonetic analysis, each individual text data called grapheme is converted to an individual indivisible sequence of sound called phoneme
- Prosodic analysis: In prosodic analysis, the prosody of speech (such as rhythm, stress, and intonations of speech) added to the basic sound makes it more realistic
- Speech synthesis: This unit finally binds the short units of speech and produces the final speech signal
Let's now discuss a bit about the various speech synthesis libraries.
eSpeak is an open source lightweight speech synthesizer mainly for English language and it will also support several other languages. Using eSpeak, we can change the voices and its characteristics. eSpeak has the module to access its APIs from Python. eSpeak works mainly in Windows and Linux and it's also compatible with Mac OS X. The official website of eSpeak is as follows:
Festival is an open source and free speech synthesizer developed by Centre of Speech Technology Research (CSTR) and is written completely in C++. It provide access to the APIs from Shell in the form of commands and also in C++, Java, and Python. It has multi language support (such as English and Spanish). Festival mainly supports Linux-based platform. The code can also be built in Windows and Mac OS X. The following is the official website of the Festival speech synthesis system: