
In this section, we will discuss Python interfacing with Pocket Sphinx, Julius, and Microsoft Speech SDK and speech synthesis frameworks such as eSpeak and Festival. Let's start with speech recognition libraries and their installation procedures.
The following packages are required to install Pocket Sphinx and its Python bindings:
python-pocketsphinxpocketsphinx-hmm-wsj1pocketsphinx-lm-wsj
The packages can be installed using the apt-get command. The following commands are used to install Pocket Sphinx and its Python interface.
Installing Pocket Sphinx in Ubuntu can be done either through source code or by package managers. Here, we will install Pocket Sphinx using the package manager:
- The following command will install HMM of Pocket Sphinx:
$ sudo apt-get install pocketsphinx-hmm-wsj1 - The following command will install LM of Pocket Sphinx:
$ sudo apt-get install pocketsphinx-lm-wsj - The following command will install the Python extension of Pocket Sphinx:
$ sudo apt-get install python-pocketsphinx
Once we are done with the installation, we can work with Python scripting for speech recognition.
The following is the code to perform speech recognition using Pocket Sphinx and Python. The following code demonstrates how we can decode the speech recognition from a wave file:
#!/usr/bin/env python import sys #In Ubuntu 14.04.2, the pocketsphinx module shows error in first import and will work for the second import. The following code is a temporary fix to handle that issue try: import pocketsphinx except: import pocketsphinx
The preceding code will import the pocketsphinx Python module and Python sys module. The sys module contain functions that can be called during program runtime. In this code, we will use the sys module to get the wave filename from the command-line argument:
if __name__ == "__main__": hmdir = "/usr/share/pocketsphinx/model/hmm/en_US/hub4wsj_sc_8k" lmdir = "/usr/share/pocketsphinx/model/lm/en_US/hub4.5000.DMP" dictd = "/usr/share/pocketsphinx/model/lm/en_US/cmu07a.dic"
The hmdir, lmdirn, and dictd variables hold the path of HMM,
LM (Language Model), and dictionary of Pocket Sphinx:
#Receiving wave file name from command line argument wavfile = sys.argv[1]
The following code will pass HMM, LM, and the dictionary path of Pocket Sphinx to Pocket Sphinx's Decoder class. Read and decode the wave file. In the end, it will print the detected text:
speechRec = pocketsphinx.Decoder(hmm = hmdir, lm = lmdir, dict = dictd) wavFile = file(wavfile,'rb') speechRec.decode_raw(wavFile) result = speechRec.get_hyp() print " Detected text:>",result print " "
The preceding code can be run using the following command:
$ python <code_name.py> <wave_file_name.wav>
The following is a screenshot of the output. The detected text was not the content on the wave file. The detection accuracy with the default acoustic model and LM is low; we have to train a new model or adapt an existing model to improve accuracy:
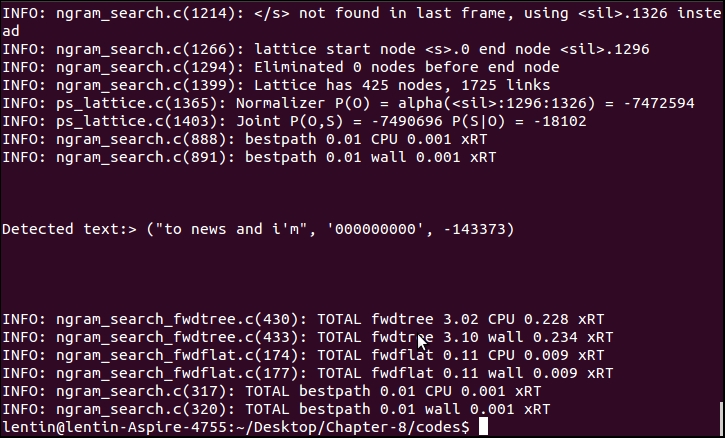
The previous method we discussed was an offline recognition; in the next section, we will see how to perform real-time speech recognition using Pocket Sphinx, GStreamer, and Python. In this approach, real-time speech data comes through the GStreamer framework and is decoded using Pocket Sphinx. To work with the GStreamer Pocket Sphinx interface, install the following packages:
The following command will install the GStreamer plugin for Pocket Sphinx:
$ sudo apt-get install gstreamer0.10-pocketsphinx
The following package will install the GStreamer Python binding. It will enable you to use GStreamer APIs from Python:
$ sudo apt-get install python-gst0.10
The following package will install the GStreamer plugin to get information from GConf:
$ sudo apt-get install gstreamer0.10-gconf