
In this recipe, you'll learn how to acknowledge problems with a host or service, in order to prevent further notifications coming from it and to signal that the problem is being worked on. This is useful if more than one administrator has access to the Nagios Core web interface. This is done in order to prevent more than one administrator trying to fix a problem and to prevent unnecessary notifications for a longer term problem after the operations team has been made aware of it. The exact changes in behavior that the acknowledgement causes are defined at the time it's submitted.
To acknowledge a notification, there needs to be at least one host or service suffering problems. Any host or service in the WARNING, CRITICAL, or UNKNOWN state can be acknowledged.
You will need access to the Nagios Core web interface and permission to run commands from the CGIs. The sample configuration provides the nagiosadmin user all the necessary privileges when authenticated via HTTP.
If you find that you don't have this privilege, check the authorized_for_all_service_commands and authorized_for_all_host_commands directives in /usr/local/nagios/etc/cgi.cfg and include your username in both, for example, tom:
authorized_for_all_service_commands=nagiosadmin,tom authorized_for_all_host_commands=nagiosadmin,tom
We can acknowledge a host or service problem as follows:
- Log in to the Nagios Core web interface, and click on the Hosts or Services section in the left-hand side menu, to visit the host or service having problems. In this example, I'm acknowledging a problem with the
APTservice on myspartamachine; Nagios is reporting upgrades that are available, but they're not critical and I can't run them right now, so I'm going to acknowledge them so that other administrators know I've got a plan for the problem:
- Click on the Acknowledge this service problem link under the Service Commands menu:
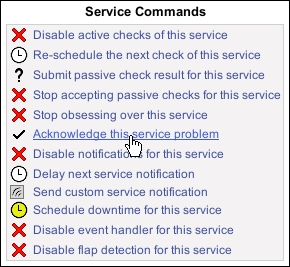
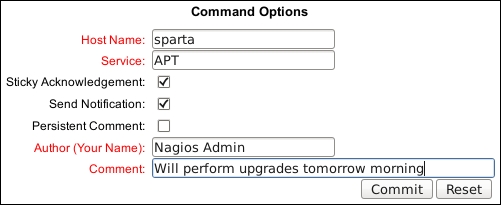
- Complete the resulting form. Include the following details:
- Host Name: This refers to the hostname for the host or service that has the problem. This should be filled in automatically.
- Service: This refers to the service description for the service having problems, if applicable. This will also be filled in automatically.
- Sticky Acknowledgement: If this is checked, notifications will be suppressed until the problem is resolved; the acknowledgement will not go away if Nagios Core is restarted.
- Send Notification: If this is checked, an ACKNOWLEDGEMENT notification will be sent to all the contacts and contact groups for the host or service.
- Persistent Comment: Acknowledgements always leave comments on the host or service in question. By default, these are removed when the host or service recovers, but if you wish you can arrange to have them take the form of a permanent comment.
- Author (Your Name): This is the name of the person acknowledging the fault. This should default to your name or username; it may be grayed out and unchangeable, depending on the value of
lock_author_namesin/usr/local/nagios/etc/cgi.cfg. - Comment: This is an explanation of the acknowledgement; this is generally a good place to put expected times to resolution and what's being done about the problem.
Note that explanatory notes also appear on the right-hand side of the command description. Click on Commit when you're done:
With this done, the effects you chose for the downtime should take effect shortly. It may take a little while for the command to be processed. You will find that there is an acknowledgment icon added to the host or service's link in its menu, and that a comment has been added:

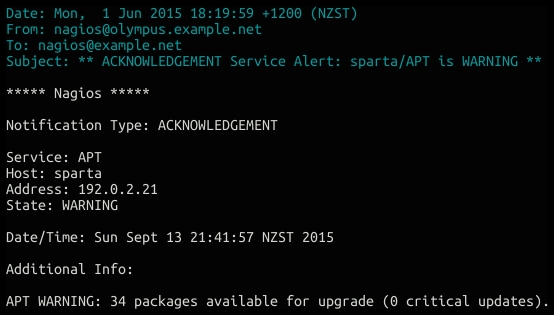
Your contacts may also receive an ACKNOWLEDGEMENT notification:
Like most changes issued from the Nagios Core web interface, acknowledging a host or service is a command issued by the server for processing, along with its primary task of executing plugins and recording states. This is why it can sometimes take a few seconds to apply even on an idle server. This is all written to the command file, by default stored at /usr/local/nagios/var/rw/nagios.cmd, which the Nagios Core system regularly reads.
When the command is executed, and the Sticky Acknowledgement option is selected, the effect is that the filters normally applied by Nagios Core before dispatching a notification will notice that the host or service has had its problems acknowledged and will therefore prevent the notification from being sent.
When the host recovers (a RECOVERY event), a notification to that effect will be sent, and the Acknowledgement will be removed, as it's no longer needed. Future problems with the host or service, even if they're exactly the same problem, will need to be acknowledged.
Acknowledging host and service problems is a really good habit to get into for administrators, particularly if they are working in a team, as it may prevent a lot of confusion or duplication of work. It's therefore helpful in the same way comments are, for keeping your team informed about what's going on with the network.
The distinction between scheduled downtime and acknowledgements is important. Downtime is intended to be for planned outages to a host or service; acknowledgement is intended as a means of notification that an unanticipated problem has occurred and is being worked on. For this reason, you should avoid getting in the habit of using the scheduled downtime feature to suppress notifications for a problem that you didn't expect; this is what acknowledgements are for.
If we're getting nagged repeatedly by notifications for problems that we already know about, as well as using acknowledgements, it may be appropriate to review the notification_interval directive for the applicable hosts or services in order to limit the frequency at which notifications are sent. For example, to only send repeat notifications every 4 hours, we could write the following code:
define host {
...
notification_interval 240
}For low-priority hosts, for example, it's perhaps not necessary to send notifications every 10 minutes!
Do not confuse this directive with notification_period, which is used to define the times during which notifications may be sent, another directive that may require review:
define host {
...
notification_period 24x7
}- Scheduling downtime for a host or service, Chapter 3, Working with Checks and States
- The Adding comments on hosts or services in the web interface recipe in this chapter