
In this recipe, you'll learn how to establish a parent-child relationship for two hosts in a very simple network in order to take advantage of Nagios Core's reachability logic. Changing this configuration is very simple; it involves adding only one directive and optionally changing some notification options.
You will need to run Nagios Core 4.0 or a newer server and have at least two hosts, one of which is only reachable via the other. The host that allows communication with the other is the parent host. You should be reasonably confident that a loss of connectivity to the parent host necessarily implies that the child host will become unreachable from the monitoring server.
Access to the web interface of Nagios Core would also be useful as making this change will change the appearance of the network map; this is discussed in the "Using the network map" recipe in this chapter.
Our example will use a Nagios Core monitoring server, olympus.example.net, which will monitor the following three hosts:
calpe.example.net, which is a routerjanus.example.net, which is another routercorsica.example.net, which is a web server
The hosts are connected as in the following diagram:
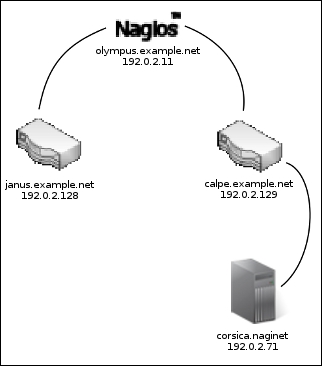
Note that the Nagios Core server olympus.example.net is only able to communicate with the corsica.example.net webserver if the calpe.example.net router works correctly. If calpe.example.net were to enter a DOWN state, we would see corsica.example.net enter a DOWN state too. Take a look at the following screenshot:
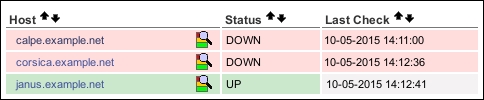
This is a little misleading as we don't actually know whether corsica.example.net is down. It might be, but with the router between the hosts not working correctly, Nagios Core has no way of knowing. A more informative and accurate status for the host would be UNREACHABLE; this is what the configuration we're about to add will arrange.
We can configure a parent-child relationship for our two hosts like so:
- Change to the objects configuration directory for Nagios Core. The default is
/usr/local/nagios/etc/objects. If you've put the definition for your host in a different file, move to its directory instead and run the following line of code:# cd /usr/local/nagios/etc/objects - Edit the file containing the definition for the child host. In our example, the child host is
corsica.example.net, which is a web server. The host definition might look something similar to this:define host { use linux-server host_name corsica.example.net alias corsica address 192.0.2.71 }
- Add a new
parentsdirective to the host's definition and give it thehost_namevalue of the host on which it is dependent for connectivity. In our example, this host iscalpe.example.net. Execute the following:define host { use linux-server host_name corsica.example.net alias corsica address 192.0.2.71 parents calpe.example.net }
- Validate the configuration and restart the Nagios Core server, as follows:
# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg # /etc/init.d/nagios restart
With this done, if the parent host enters a DOWN state and the child host can't be contacted, then the child host will enter an UNREACHABLE state rather than also being flagged as DOWN:

The child host's contacts will also receive UNREACHABLE notifications instead of DOWN notifications for the child host, provided the u flag is included in notification_options for the host and host_notification_options for the contacts. Refer to the Specifying which states to be notified about recipe in Chapter 4, Configuring Notifications, for details on this.
This is a simple application of Nagios Core's
reachability logic. When the check to calpe.example.net fails for the first time, Nagios Core notes that it is a parent host for one child host: corsica.example.net. If during checks for the child host it finds that it cannot communicate with it, then instead of the DOWN state, it flags an UNREACHABLE state, firing a different notification event.
The primary advantages to this are two fold:
- The
DOWNnotification is only sent for the nearest problem parent host. All other hosts beyond this host fireUNREACHABLEnotifications. This means that Nagios Core's reachability logic automatically determines the point of failure from its perspective, which can be very handy in diagnosing which host is actually experiencing a problem. - If the host is parent to a large number of other hosts, the configuration can be arranged not to send urgent notifications for
UNREACHABLEhosts. There may not be much point in sending a hundred pager or e-mail messages to an administrator when a very central router goes down; they know there are problems with the downstream hosts, so all we would be doing is distracting them with useless information.
With a little planning and some knowledge of the network, all we need to do is add a few parents directives to host definitions to build a simple network structure and Nagios Core behaves much more intelligently as a result. This is one of the easiest ways to refine the notification behavior of Nagios Core; it can't be recommended enough!
Note that a child host can itself be a parent to other hosts in turn, allowing a nesting network structure. Perhaps in another situation, we might find the corsica.example.net server is two routers away from the monitoring server, as shown in the following diagram:
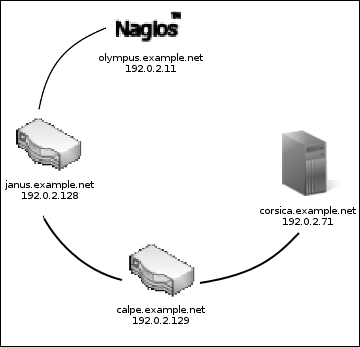
In this case, not only is corsica.example.net the child host of calpe.example.net, but calpe.example.net is itself the child host of janus.example.net. We could specify this relationship in exactly the same way. Take a look at the following code:
define host {
use linux-router
host_name calpe.example.net
alias calpe
address 192.0.2.129
parents janus.example.net
}It's also possible to set multiple parents for a host if there are two possible paths to the same machine, as follows:
define host {
use linux-server
host_name corsica.example.net
alias corsica
address 192.0.2.71
parents calpe.example.net,janus.example.net
}With this configuration, corsica.example.net would only be deemed UNREACHABLE if both of its parent hosts were down. This kind of configuration is useful to account for redundant paths in a network—for example, spanning tree technologies or BGP/OSPF failover.
After you set up a good basic structure for your network using the parents directive, definitely check out the Using the network map recipe in this chapter to get some automatic visual feedback about your network's structure as generated through your new configuration.
- The Using the network map, section from Chapter 8, Managing Network Layout
- The Establishing a host dependency, section from Chapter 8, Managing Network Layout
- The Specifying which states to be notified about, section from Chapter 4, Configuring Notifications
- The Configure notification groups, section from Chapter 4, Configuring Notifications