
Supervised machine learning can be further subdivided into exercises that involve either of the following:
- Classification
- Regression
The concepts are quite straightforward.
Classification involves a machine learning task that has a discrete outcome - a categorical outcome. All nouns are categorical variables, such as fruits, trees, color, and true/false.
The outcome variables in classification exercises are also known as discrete or categorical variables.
Some examples include:
- Identifying the fruit given size, weight, and shape
- Identifying numbers given a set of images of numbers (as shown in the earlier chapter)
- Identifying objects on the streets
- Identifying playing cards as diamonds, spades, hearts and clubs
- Identifying the class rank of a student based on the student's grade
- The last one might not seem obvious, but a rank, that is, 1st, 2nd, 3rd denotes a fixed category. A student could rank, say, 1st or 2nd, but not have a rank of 1.5!
Images of some atypical classification examples are shown below:
 Classification of different types of fruits |
 Classification of playing cards: diamonds, spades, hearts, and clubs |
Regression, on the other hand, involves calculating numeric outcomes. Any outcome on which you can perform numeric operations, such as addition, subtraction, multiplication, and division, would constitute a regression problem.
Examples of regression include:
- Predicting daily temperature
- Calculating stock prices
- Predicting the sales price of residential properties and others
Images of some atypical regression examples are shown below. In both the cases, we are dealing with quantitative numeric data that is continuous. Hence, the outcome variables of regression are also known as quantitative or continuous variables.
 Calculating house prices |
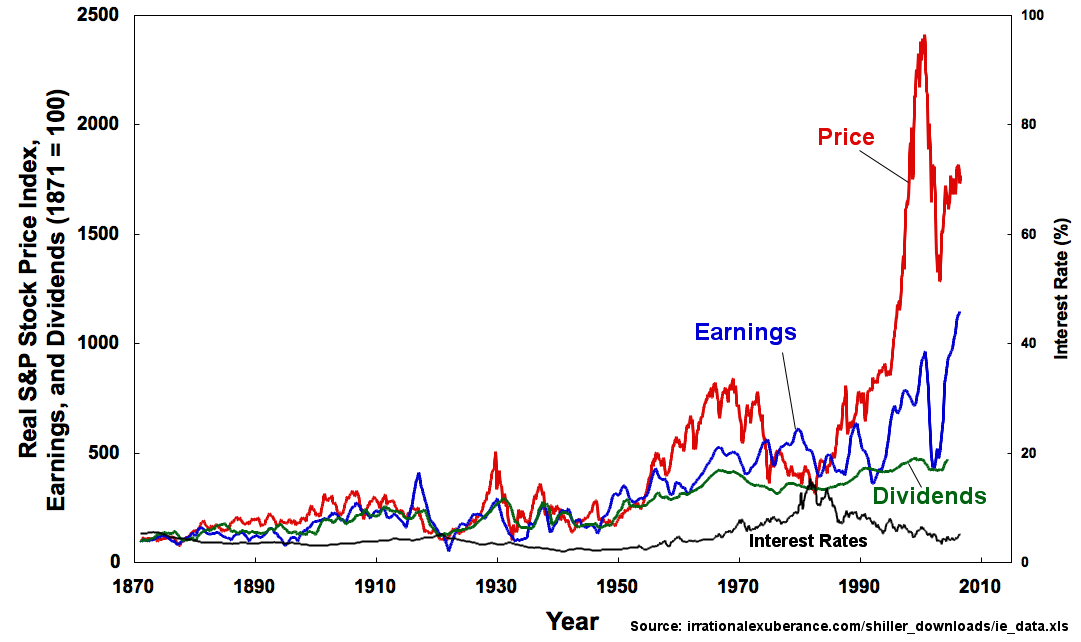 Calculating stock prices using other market data |
Note that the concepts of classification or regression do not as such apply to unsupervised learning. Since there are no labels in unsupervised learning, there is no discrete classification or regression in the strict sense. That said, since unsupervised learning categories data into clusters, objects in a cluster are often said to belong to the same class (as other objects in the same cluster). This is akin to classification, except that it is created after-the-fact and no classes existed prior to the objects being classified into individual clusters.