
Chapter 6
Solving SEO Roadblocks
In This Chapter
- Ensuring that search engines see your site
- Creating effective sitemaps
- Avoiding page hijacking from 302 Redirects
- Handling SEO problems connected with secure sites
You know the part of an instruction manual that’s just labeled Troubleshooting? It’s sort of a catchall for problems you might have that don’t fit anywhere else in the manual, with tips for what you can do about them. This chapter is sort of like that Troubleshooting section — a place for us to address miscellaneous problems you might run into and give some advice on how to resolve them.
You should look at your search engine optimization (SEO) project as an ongoing process. It’s not a journey with a fixed end point. There’s no “destination” that you can reach and then hang up your keyboard and mouse and declare, “Ahh … we’ve made it!” Even if you reach the number one spot on the search results, you can’t relax; you must continually monitor and fine-tune your site to stay ahead of the competition.
Occasionally, you will hit roadblocks to your SEO progress. Don’t confuse these roadblocks with the time lag that normally occurs before results become apparent. Usually, it takes an SEO project three to six months to see a website rise considerably in ranking and traffic, after you put the initial site optimization in place. Of course, results are always based on the keywords and condition of your site when the project starts. Your mileage is going to vary based on the competition. Sometimes, it happens within a few weeks or even a few days, but that’s very unusual — normally, results take several months. Some keywords actually take years to rank well.
However, you can run into obstacles with SEO. You might find out that a search engine doesn’t have any of your pages in its index (database of web pages that a search engine pulls results from). Or you might find your site plummeting down the search engine results for no apparent reason. Or you might have difficulties related to setting up a secure server (the software and hardware that runs a website) for parts of your website. In this chapter, you find out what to do when you run into these kinds of roadblocks.
Inviting Spiders to Your Site
You may have pages that are missing from one or more of the search engines, which causes lower or non-existent search engine rankings. If you suspect a specific page is missing, find out for sure by entering a long snippet of text from that page in a search query, enclosed in quotation marks like this: [“Here’s a long snippet of text taken directly from the page”]. The quotation marks force the search engine to look for an exact match, so your page should come up in the results if it’s in the index at all. (By the way, this is also a great way to find duplicate content from your site.)
You can also check to see how extensively the search engines have indexed your entire website in a single search. To check for this at Google or Bing, enter the search query [site:yourdomain.com], replacing yourdomain.com with your actual domain (and removing the brackets). You can also gain intelligence about how the search engines have indexed your site using Index Explorer in the free Bing Webmaster Tools (http://bing.com/toolbox/webmaster). If you’ve verified your site in Bing Webmaster Tools, you can navigate to Index Explorer in the Reports & Data section. Here you’ll see how Bing sees your site. As shown in Figure 6-1, Index Explorer takes the pages of your site in Bing’s index and organizes them based on directories. Select a folder and drill down to see how many pages and folders are contained within, how many times pages in that directory have shown up in search, how many clicks they got from a Bing search page, and how many links point to it.
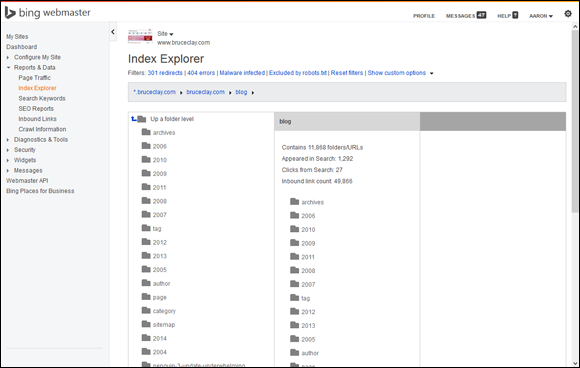
Figure 6-1: Bing Index Explorer reveals how many of your site pages are indexed.
 So if, for example, you had an indexing problem with Bing, you could use this tool to see all the pages Bing knows about and compare it to an independent crawl of your site to see whether
So if, for example, you had an indexing problem with Bing, you could use this tool to see all the pages Bing knows about and compare it to an independent crawl of your site to see whether
- Bing is ignoring an entire directory
- One of your directories is getting a lot more search visibility than others
- A disparity exists between search visibility and inbound links
- One of your folders has more indexed pages than you got from your crawl, in which case you've probably got some problems
If you discover important pages that haven’t been indexed, you need to invite the spiders to your site. You want them to travel all your internal links and index your site contents. What follows are several effective ways you can deliver an invitation to the search engine spiders:
- External links: Have a link to your missing page added to a web page that gets crawled regularly. Make sure that the link’s anchor text relates to your page’s subject matter. Ideally, the anchor text should contain your page’s keywords. Also, the linking page should relate to your page’s topic in some way so the search engines see it as a relevant site. After the link is in place, the next time the spiders come crawling, they follow that link right to your page. This sort of “natural discovery” process can be the quickest, most effective way to get a page noticed by the search engines.
- Direct submission: Each search engine provides a way for you to submit a URL, which then goes into a queue waiting for a spider to go check it out. A direct submission isn’t a fast or even reliable method to get your page noticed, but it doesn’t hurt to do it.
- Internal links: You should have at least two links pointing to every page in your site. This helps ensure that search engine spiders can find every page.
- Sitemap: You should provide a sitemap (a list of the pages in your site that includes keyword-rich links) for your users, but for the search engines you want to create another sitemap in XML (Extensible Markup Language) format. Make sure that your XML Sitemap contains the URL links to the missing pages, as well as every other page that you want indexed. When a search engine spider crawls your XML Sitemap, it follows the links and is more likely to thoroughly index your site.
The two versions of your sitemap provide direct links to your pages, which is helpful for users and important for spiders. Search engines use the XML Sitemap file as a central hub for finding all your pages. But the user’s sitemap is also crawled by the search engines. If the sitemap provides valuable anchor text for each link (for example, Frequently Asked Classic Car Questions, rather than just FAQs), it gives search engines a better idea of what your pages are about. Google specifically states in its guidelines that every site should have a sitemap (www.google.com/support/webmasters/bin/answer.py?answer=35769#design).
The number of links you should have on the user-viewable sitemap is limited. Small sites can place every page on their sitemap, but larger sites shouldn’t. Having more than 99 links on a page just doesn’t provide a very user-friendly experience — no user wants to wade through hundreds of links to find what he’s looking for. So just include the important pages, or split it into several sitemaps, one for each main subject category. (For more tips on creating an effective sitemap, see Book VI, Chapter 2.)
However, unlike a traditional sitemap, XML Sitemaps don't have a 99-link limit. There are still some limitations, but the file(s) is meant to act as a feed directly to the search engines. For full details on how to create an XML Sitemap, visit www.sitemaps.org, the official XML Sitemap guideline site run by the search engines.
 In addition to having the search engine spiders come crawl your site, which is the first goal, you also want to direct them to where you want them to go within your site. For comparison, when people come over to your house, you don’t just let them roam around and look anywhere they want, right? You lead them around, showing them what you want them to see — probably skipping the disorganized garage and messy utility room.
In addition to having the search engine spiders come crawl your site, which is the first goal, you also want to direct them to where you want them to go within your site. For comparison, when people come over to your house, you don’t just let them roam around and look anywhere they want, right? You lead them around, showing them what you want them to see — probably skipping the disorganized garage and messy utility room.
With search engine spiders, you don’t want them to see every page or follow every link, either. The two reasons you want them to crawl around are
- Indexing: You want the search engines to index your pages so that they can find those pages relevant to people’s searches and return them in search results.
- Better ranking: When the spiders follow your links, they pass link equity (the perceived-expertise value of all the inbound links pointing to a web page, which is a search engine ranking factor) to your landing pages (the pages you set up to be the most relevant for a primary keyword). Concentrating link equity on your landing pages makes those pages move higher up in the search engine rankings and bring in more traffic.
Some pages, like your Privacy Policy or Terms of Use, need to be in your global navigation but they don’t need to rank well in the search engine’s index. You don’t want to rank for those pages or to dilute the link equity being passed to your landing pages. Instead, you should “herd” the spiders where you want them to go. To keep spiders away from certain pages, here are a couple of techniques you should know:
- nofollow: You can put a rel="nofollow" attribute on any link that you don’t want the spiders to pass link equity to. Using this technique on links to unimportant pages, you could concentrate link equity onto your landing pages.
- Robots text file (.txt) exclusion: Be consistent. If you add rel="nofollow" to a link to prevent spiders from crawling to your privacy policy page, for instance, do it everywhere. Put the nofollow attribute on every link to that page. Also instruct the spiders not to index the page by excluding it in your robots text file (a central file that gives instructions to spiders of where not to go; check out Chapter 1 of this minibook for more on editing your robots.txt file).
- Meta Robots exclusion: Another way to put up a Do Not Enter sign for search engines is with a noindex Meta robots tag on a specific page. (A Meta robots tag is an HTML command in the Head section [top part] of a web page’s HTML code that gives instructions to search engine spiders whether to index the page and whether to follow its links.) This tag is not needed if you’ve excluded the page in your robots.txt file. But to put the exclusion directly into the page code, you can add a tag such as this:
<meta name="robots" content="noindex">
In Chapters 1 through 5 of this minibook, we talk only about the good search engine spiders — the ones you want coming to your site. However, bad spiders are also out there, ones that come only to harm you.
Spiders called scrapers come to steal your site content so that they can republish it on their own sites. Sometimes they grab entire pages, including the links back to your site and everything. One problem with scraping is that it creates duplicate content (the same or very similar text on two or more different pages) on the web, which can cause your page to drop in ranking or even drop out of the search results if the search engines don’t correctly figure out which page is the original. Another problem is that scraped content may end up ranking above your page/site and grab traffic that should have been yours. Scraping is a copyright violation, and it’s also a crime punishable by law, if you choose to pursue that. Unfortunately, the more good text content you have on your site, the more likely you are to attract scrapers. So as your site expands and your SEO project raises your rankings, you’re probably going to run into this issue.
Webmasters have tried to prevent site scraping in various ways. Some have gone so far as to build a white list (a list of approved sites or agents) that contains only the known good spiders, and then exclude all non-white-listed spiders from entering their sites. Webmasters don’t often use that extreme measure because they can’t easily maintain a current white list without potentially excluding legitimate traffic to their sites.
A more typical defensive move is to sniff out a bad spider by using a server-level process known as user-agent sniffing. This process identifies spiders coming to your site, kind of like a security guard at your front door. If you know who a bad spider is, you can detect its arrival and keep it out. Or, some webmasters choose to do more than just block them; they redirect them to a page with massive quantities of data in hopes of crashing the bad spider’s site. Block them or punish them, you choose, but unfortunately you can only do this after you’ve identified a spider as a scraper — not before you know who it is.
To deter others from copying your content, we recommend that you display a copyright notice on your website and register for a federal copyright. To register for a federal copyright, visit http://www.copyright.gov/, where you also find helpful information about the entire federal copyright process. For more suggestions on handling scrapers, see Book V, Chapter 5.
Avoiding 302 Hijacks
Here’s a scenario that we hope never happens to you: Your website is running smoothly and ranking well with the search engines for your keywords. One day, you find that your search engine traffic is dropping dramatically. Then you notice that your pages have disappeared from the search engine results pages.
This nightmare scenario could mean that your site was a victim of a 302 hijack. A 302 Redirect is a type of redirect (an HTML command that reroutes a user from one page to another automatically) used to indicate that one web page has temporarily moved to another URL. The search engine retains the original page in its index and attributes the content and link equity of the new page to the original page.
An unethical way to use 302 Redirects is called 302 hijacking. This technique exploits the way search engines read 302 Redirects in order to cause a web page’s traffic and SERP rankings to be drained away and given to some other page (the “hijacker”). The hijacker is basically stealing your website, rankings, and search traffic.
Here’s how it works: The hijacker sets up a dummy page, often containing a scraped copy of your web page’s content and a 302 Redirect to your ranking page. The search engines see the 302 Redirect and think that the hijacker’s page is the real version that’s temporarily using your page’s URL. So, the 302 Redirect tricks the search engines into thinking that your ranking page is the temporary version of the hijacker’s virtual page. The search engine therefore gives all your link equity and rankings away to the hijacker’s URL. Figure 6-2 shows how a hijacked page’s listing might appear in a SERP. Notice that the URL on the bottom line doesn’t match the company name shown in the listing; clicking this link takes the user to some other page off the company’s site.
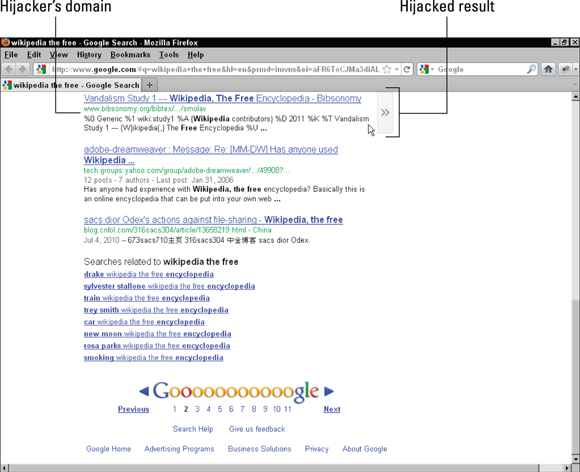
Figure 6-2: A page hijacking transfers existing search engine rankings to another URL of the hijacker’s choice.
 A 302 hijacking can devastate a site, causing duplicate content penalties and loss of ranking. The search engines are aware of this issue and have tried to put preventive measures in place. They’ve had some success combating this crime, but it still happens.
A 302 hijacking can devastate a site, causing duplicate content penalties and loss of ranking. The search engines are aware of this issue and have tried to put preventive measures in place. They’ve had some success combating this crime, but it still happens.
Be on the lookout for page hijacking by regularly searching for snippets of your page text (do a search using quotation marks to find an exact match) to identify copycat pages; you’ll know for certain that it's happening when you see someone else’s URL showing up on your SERP listings. If you have this problem, contact the third-party site and ask it to cooperate with you to fix the situation. Page hijacking is often accidental (through improper use of 302 Redirects), so you may be able to resolve it with the site easily. If you discover that the site’s intentions are malicious, however, you should report the site to the search engines immediately for investigation. If you’re ever in this situation, you need to contact the search engine directly. Unfortunately, there’s not much you can do to fix it on your own — the search engines have to remedy the situation for you.
Handling Secure Server Problems
You may have pages on your site where users provide sensitive data, such as a credit card number or other type of account information. The Internet solution for protecting sensitive information is to put those web pages on a secure server. Technically, this means that the web page is on a secure port on the server, where all data is encrypted (converted into a form that cannot be understood except by knowing one or more secret decryption keys). You can tell when you’re looking at a web page on a secure server because http:// changes to https:// in the URL address. In 2014, Google announced that page security was a ranking factor and that pages hosted on a secure server got a minor ranking boost. So, especially for pages that handle sensitive data, an https:// URL is highly recommended.
Secure servers can cause duplicate content problems if a site has both a secure and nonsecure version of a web page and hasn’t told the search engines which of the two is the preferred, or canonical, version. Two versions of the same page end up competing against each other for search engine rankings, and the search engines pick which one to show in search results.
Here are some SEO-minded best practices for handling secure servers:
- Don’t make duplicates: Many times, people just duplicate their entire website to make an https:// version. This is a very bad practice because it creates instant duplicate content. Never create two versions of your site or of any page on your site. Even if you exclude your secure pages from being indexed, people link to them at some point and the search engines find the secure versions through those links.
- If you have cases of duplication caused by http:// and https://, indicate a canonical version: Any time you have pages with similar or duplicate content, you can tell the search engine which page you prefer to show up in a search result and which page to give all the link equity to by using a canonical tag. Read all about using the canonical tag in Chapter 2 of this minibook.
- Secure the pages that need to be secure: If the page doesn’t receive sensitive account-type information from users, it doesn’t need to be secured. However, if it isn’t cost prohibitive to do so, you may choose to secure many pages across your site for the marginal ranking benefit.
- Spiders shouldn’t be blocked from crawling secure pages if those pages are important for rankings: Search engines do index secure pages, if they can get to them. Banks usually have secure pages indexed because they often put their entire site on an https://. Because of the nature of their business, it makes sense that banks want to give their users the utmost level of confidence by securing their whole site. It’s a good user experience for a page to show up when a user’s searching for it, for example, if a user is looking for her online banking login page.
If your website has secure pages that violate these best practices, here’s how to fix them:
Identify which pages on your site need to be secure.
Always secure the pages on which users need to enter account information.
Make sure that your secure pages are not duplicated.
Your secure pages should have only an https:// version. Don’t offer a non-secured duplicate version. If you do have a duplicate-page situation, include a canonical tag that tells search engines which page is the best one to use. All links to and from secure pages should be full path links, meaning they begin http:// or https://. Using relative links to secure pages is just asking for trouble.
Clean up duplicate pages by using 301 Redirects.
If you currently have secure pages that don’t need to be secured, redirect them to the http:// version by using a 301 (permanent) Redirect. That way, any links going to the secure pages are automatically redirected to the right pages. The same goes for non-secure pages that should be secured, only vice versa.