
Appendix 2.D Calculating Probabilities Using PROBIT Regression Coefficients
Let us define U an observed binary indicator, y* the unobserved continuous response variable; ![]() the latent construct variable or factor, underlying y* ;
the latent construct variable or factor, underlying y* ; ![]() is factor loading, and
is factor loading, and ![]() is measurement error.
is measurement error.
(2.15) ![]()
(2.16) ![]()
where ![]() is a threshold, the probability of having U = 1 is:
is a threshold, the probability of having U = 1 is:
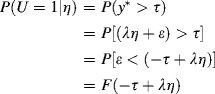
For this function either the PROBIT function or LOGITSTIC function can be the appropriate link function to relate the observed variable y to factor ![]() . Mplus uses LOGIT link for ML estimators and PROBIT link for WLS estimators. The default estimator for modeling categorical outcomes is WLSMV, thus the default link function is PROBIT. In Mplus, threshold parameters are estimated instead of intercepts, and the intercept is represented in threshold, that is,
. Mplus uses LOGIT link for ML estimators and PROBIT link for WLS estimators. The default estimator for modeling categorical outcomes is WLSMV, thus the default link function is PROBIT. In Mplus, threshold parameters are estimated instead of intercepts, and the intercept is represented in threshold, that is, ![]() . Using Equation (2.17), the PROBIT regression coefficients can be converted to the probability of U = 1. As
. Using Equation (2.17), the PROBIT regression coefficients can be converted to the probability of U = 1. As ![]() is the cumulative normal distribution function (CDF),
is the cumulative normal distribution function (CDF), ![]() can be found in the Z distribution table or readily calculated using statistical packages.
can be found in the Z distribution table or readily calculated using statistical packages.
For ordered categorical outcome measures with more than two categories, the probability of being in the categories from 0 to M can be calculated using PROBIT coefficients (Muthé n and Muthé n, 1998– 2010):
(2.19) ![]()
Notes
1. Recently, exploratory SEM has been developed (Asparouhov and Muthé n, 2009), in which the measurement model is an EFA model.
2. In SEM, there are two kinds of indicators of latent variables: causal (‘ formative’) indicators and effect (‘ reflective’) indicators. The former are observed variables that directly affect their latent variables; the latter are observed variables that are a function of the latent variables. Nearly all measurements in real research implicitly assume effect indicators. In this book, only effect indicators are considered. For more information about formative and reflective indicators, readers are referred to Blalock (1964), Bollen (1984), Bollen and Lennox (1991), and Edwards and Bagozzi (2000).
3. For numeric observed indicators, the factor loadings are simple linear regression coefficients. If the observed indicators are categorical, then the factor loadings could be probit or logistic regression coefficients depending on what estimator is used. We will discuss this issue later.
4. No matter which indicator' s unstandardized factor loading is set to 1.0, the standardized solution will always be the same because the completed standardized solution rescales the variances of all latent variables and indicators to be 1.0.
5. In addition to the completely standardized solution, other standardization solutions include: only latent variables/ factors are standardized; and only observed variables are standardized. In this book, we are only interested in the completely standardized solution; and hereafter completely standardized factor loadings and standardized factor loadings are used interchangeably.
6. There are two kinds of measurement errors: random errors and systematic errors. Random errors are errors that are unpredictable fluctuations in measurement, assuming random scattering about the true value with a normal distribution. Systematic errors are biases in measurement that are either constant or proportional to the true value of the measure. Only random errors are considered in this book.
7. By default, TYPE = MISSING in the ANALYSIS command is used to deal with missing values. Mplus Program 2.1 is to demonstrate the CFA model based on covariance structure (COVS) that can be implemented only if MODEL = NOMEANSTRUCTURE statement is specified in the ANALYSIS command. Since the MODEL = NOMEANSTRUCTURE statement is not allowed to be used in conjunction with the default TYPE = MISSING option, the LISTWISE statement in the DATA command is specified to deal with missing values in this example.
8. Mplus provides three standardized solutions: STDYX, STDY and STD. STDYX uses the variances of the continuous latent variables, the variances of the background and outcome variables for complete standardization. STDY uses the variances of the continuous latent variables and the variances of the outcome variables for standardization. STDY should be used when binary covariates are involved because a standard deviation change of a binary variable is not meaningful. STD uses the variances of the continuous latent variables for standardization. When all indicators are on the same scale, STD may be used (Muthé n and Muthé n, 1998– 2010).
9. A very common programming error in Mplus is missing a semicolon at the end of a command line.
10. With Mplus version 6, multiple imputation of missing data (Schafer, 1997) In addition, multiple imputation data generated from other software (e.g., SAS Proc MI) can also be analyzed in Mplus (Muthé n and Muthé n, 1998– 2010).
11. ML χ 2 (T) is the product of MLR χ 2 (T* ) and the scaling correction factor (c).
12. The P- value can be calculated in the following SAS program:

13. LISCOMP stands for LInear Structural equations with a COMPrehensive measurement model (Muthé n, 1988).
14. The label in parentheses can be arbitrary letters, numbers, or a combination of letters and numbers.