
5.2 Multi-Group SEM model
In the last section, we have demonstrated how to test factorial invariance across groups using multi-group CFA model. Very often, invariance of path coefficients is of interest, and we wonder whether some relationships among variables, including observed and unobserved latent variables/factors remain unchanged in different populations or groups, then multi-group SEM applies. In this section we switch our attention to examining invariance of specific structural path coefficients across groups using multi-group SEM. Similar to the multi-group CFA model, some path coefficients in a multi-group SEM model can be restricted to be equal, while other coefficients remain varying, across groups. By testing equality or invariance of path coefficients across groups, it enables us to examine whether different groups behave similarly (Hayduk, 1987).
Our demonstration of the multi-group SEM model will be based on the model specified in Figure 3.4. As discussed in Section 3.2, the relationship between substance abuse and mental health is complicated. For the purpose of model demonstration, we assume: (1) only crack-cocaine use affects mental problems and there are no reciprocal effects; and (2) depression is a function of anxiety, instead of the other way around.
We start by establishing a baseline SEM model for Ohio and Kentucky, respectively. If the baseline models fit data well, we will test: (1) whether the effect of anxiety (ANX, ![]() ) on depression (DEP,
) on depression (DEP, ![]() ) remains unchanged across populations, controlling for covariates; and (2) whether the effects of crack-cocaine use (CRACK,
) remains unchanged across populations, controlling for covariates; and (2) whether the effects of crack-cocaine use (CRACK, ![]() ) on mental problems remains unchanged across populations, controlling for socio-demographics.
) on mental problems remains unchanged across populations, controlling for socio-demographics.
The following Mplus programs are for the baseline models for Ohio and Kentucky, respectively.
Mplus Program 5.16


Mplus Program 5.17

where two factors (DEP and ANX) are defined in the measurement model, and then they are treated as latent endogenous variables in the structural equations. Observed variables Crack (frequency of crack-cocaine use in the past 30 days), Gender (1, male; 0, female), White (1, white drug users; 0, non-white drug users), Age (age at baseline interview), and Edu (education measured with a six-point scale) are included in the model to predict the latent endogenous variables DEP and ANX. In addition, Crack is regressed on the four individual background variables.
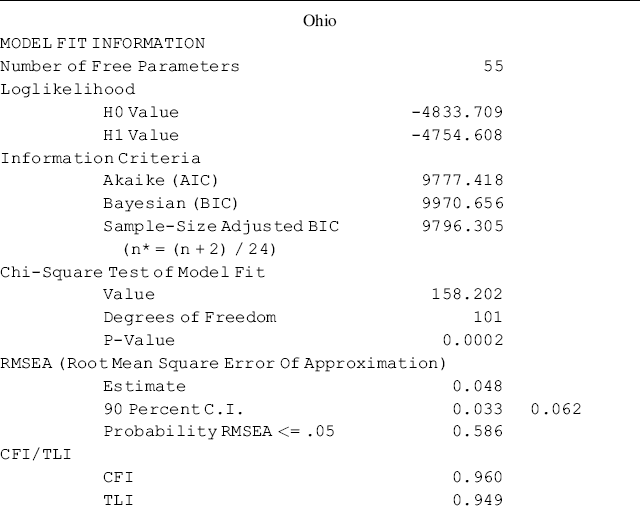
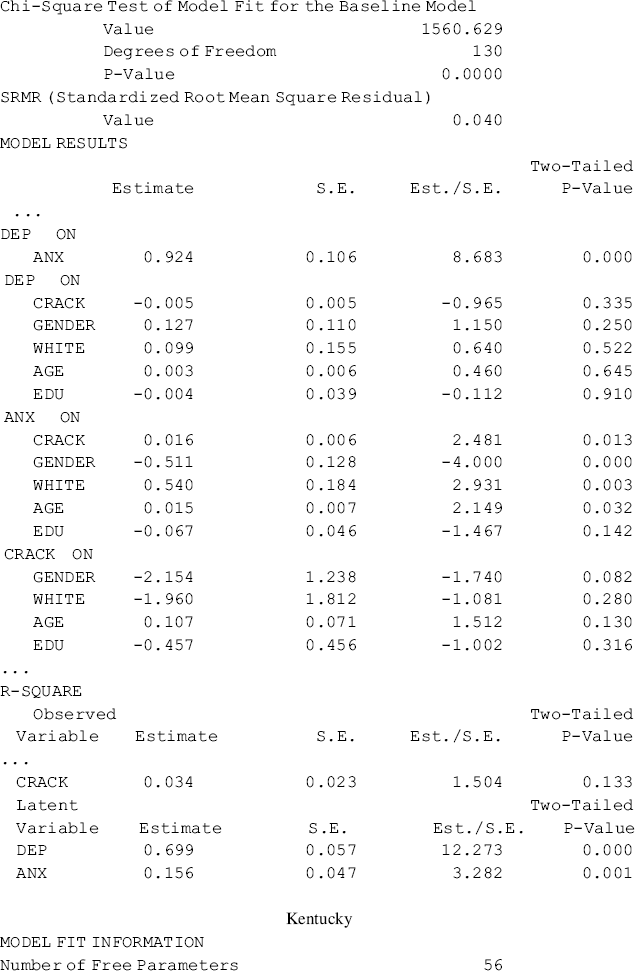
The Ohio model fits data very well: RMSEA = 0.048, 90% CI = (0.033, 0.062); close-fit test P = 0.586; CFI = 0.960; TLI = 0.949; SRMR = 0.040. Anxiety (ANX) has a significant positive effect on depression (DEP) (0.924, P < 0.001), however, crack-cocaine use and all the socio-demographical variables show no effects on depression. Crack-cocaine use and three socio-demographical variables significantly affect anxiety: crack-cocaine has a significant positive effect (0.016, P = 0.013), both ethnicity and age have significant positive effects (0.540, P = 0.003; and 0.015, P = 0.032, respectively), and gender has a negative effect (−0.511, P < 0.001). None of the socio-demographical variables has a significant effect on crack-cocaine use.
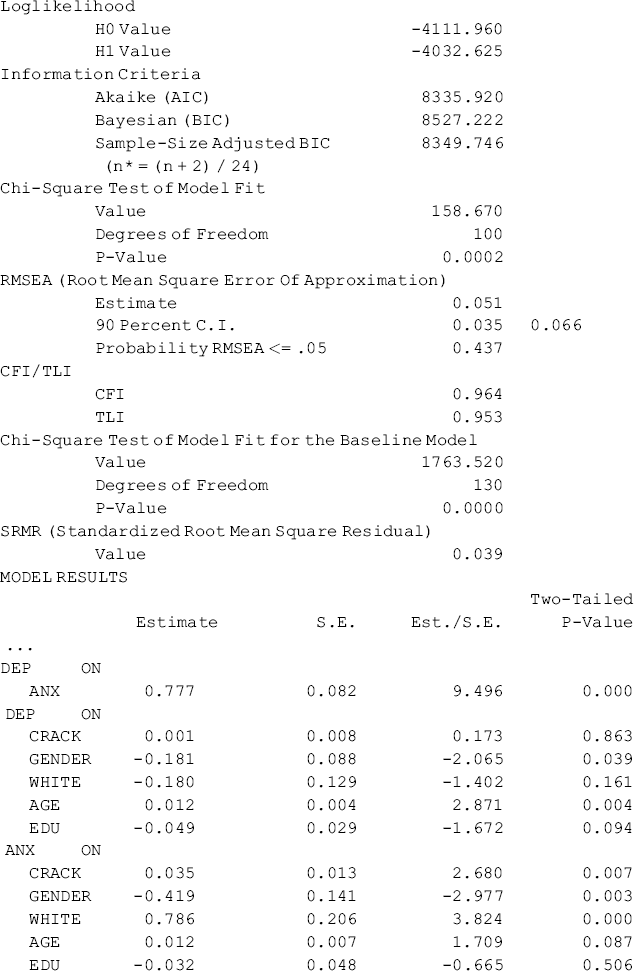
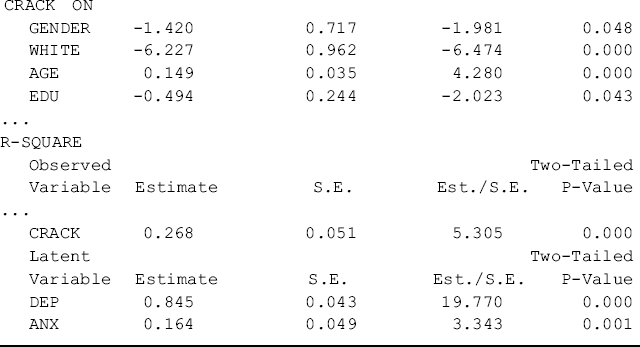
The Kentucky model also fits data very well: RMSEA = 0.051, 90% CI = (0.035, 0.066); close-fit test P = 0.437; CFI = 0.964; TLI = 0.953; SRMR = 0.039. As in the Ohio model, anxiety has a significant positive effect on depression (0.777, P < 0.001). However, the results of the Kentucky model show that the effects of socio-demographics on both depression and anxiety, as well as on crack-cocaine use, differ from those in the Ohio model. In the Ohio model, none of the socio-demographic variables shows a significant effect on depression, but in the Kentucky model two socio-demographic variables have significant effects on depression: gender has a significant negative effect (−0.181, P = 0.039), and age has a significant positive effect (0.012, P = 0.004). The effects of crack-cocaine use (0.035, P = 0.007), gender (−0.419, P = 0.003) and ethnicity (0.786, P < 0.001) on anxiety in the Kentucky model remain similar to those in the Ohio model, but the effect of age on anxiety that is statistically significant in the Ohio model becomes only marginally significant (0.012, P = 0.087) in the Kentucky model. Education shows no significant effect on anxiety and depression in both models. In regard to the effects of socio-demographics on crack-cocaine use, it is very interesting that all the socio-demographical variables have statistically significant effects on crack-cocaine use in the Kentucky model while none of these variables shows a significant effect on crack-cocaine use in the Ohio model. The explanations for these discrepancies are outside the scope of this book.
Table 5.16 shows that both the Ohio and Kentucky baseline SEM model fit data very well, but the estimated path coefficients differ between the two models. The noninv ariance in structural path coefficients implies that population membership moderate the causal relationships in the models. In the following, we will discuss and demonstrate how to test invariance or equality of the structural path coefficients across populations/groups.
Table 5.16 Selected Mplus output: the baseline SEM models.
Test invariance of structural path coefficients across groups: To test structural path coefficient invariance, we first estimate a configural SEM model using Ohio and Kentucky samples simultaneously. Just like the configural CFA model we have discussed in Section 5.1, this model will serve as a base model for model comparisons later. All path coefficients in the model are set free across groups. The Mplus program follows.
Mplus Program 5.18


where the measurement model is only specified by the BY statement in the overall MODEL command, thus the item intercepts and factor loadings are restricted invariant across group by default. This is important for two reasons. First, because the model will estimate intercepts of the latent variables/factors, equality restrictions have to be imposed on item intercepts in order to make the mean structure part of the model identifiable. Secondly, to compare the relationships between latent variables and covariates, we need to ensure the same metric for the latent variables across groups; that is, the factor loadings of the latent variables must be invariant across groups.
The three ON statements in Mplus Program 5.18 establish the structural equations in the multi-group SEM model by regressing dependent variables (i.e., depression, anxiety, and crack-cocaine in this example) on predictors simultaneously. The structural equations are only specified in the overall MODEL command to ensure the same structural equations across groups, but the structural path coefficients will be estimated separately for each group without equality restriction. Here we focus on testing the following hypotheses:
- H0-1 The direct effect of anxiety on depression is invariant among rural drug users in Ohio and Kentucky.
- H0-2 The indirect effect of crack-cocaine use on depression via anxiety is invariant among rural drug users in Ohio and Kentucky.
Interested readers may practice on their own to test the invariance of other structural parameters in the model.
The estimator used for modeling here is MLMV, a robust estimator, that handles non-normality in data and provides mean and variance adjusted χ2 test of model fit. Recall that once a robust estimator, such as MLR, MLM, and WLSM, is used for modeling, the difference between the scaled χ2s for the nested models does not follow a χ2 distribution, thus cannot be used directly for the LR test. Instead, a scaled difference in χ2 test should be computed for comparison (see Chapters 1 and 2). Alternatively, for WLSMV and MLMV,11 difference testing can be done using the DIFFTEST option of the SAVEDATA and ANALYSIS commands in a two-step approach (see Section 2.4.1). In Step 1 a less restrictive H1 model is estimated, and the DIFFTEST option of the SAVEDATA command is used to save the derivatives needed for the χ2 difference test (the testing information is saved in an output file named Test_H1.dat in this example). In Step 2 the more restrictive H0 model is estimated, and the DIFFTEST option of the ANALYSIS command is used to retrieve the testing information saved in file Test_H1.dat to conduct the χ2 difference test.
In the following Mplus program, the direct effect of anxiety on depression is restricted invariant across groups. Comparing this restricted model with the unrestricted model estimated in Mplus Program 5.18 enables H0-1 to be tested.
Mplus Program 5.19

where placing a number 1 in parentheses after the variable ANX in the first ON statement in the overall MODEL command imposes equality restriction on the effect of ANX on DEP across groups. The DIFFTEST option in the ANALYSIS retrieves the testing information saved in file Test_H1.dat and produces a χ2 test with df = 1. Note that the ON statement should be broken into different lines right after the restriction; otherwise, the slope coefficients of variables that are placed after the restriction on the line will not be estimated, and it would end up with a different χ2 test statistic. For example, if we place the ON statement like DEP ON ANX(1) GENDER WHITE AGE EDU CRACK on the same line in the overall MODEL command in Mplus Program 5.19, the slope coefficients of the covariates GENDER, WHITE, AGE, EDU, and CRACK would not be estimated in both groups, therefore, the degrees of freedom for the χ2 test would be 11 rather than 1.
The model specified in Mplus Program 5.19 is the more restricted H0-1 model and will be compared with the H1-1 model specified in Mplus Program 5.18. The χ2 test for difference testing is: ![]() = 1.055, df = 1, P = 0.3044, indicating that H0-1 cannot be rejected. In other words, the effect of anxiety on depression remains invariant among rural drug users in Ohio and Kentucky. Statistically speaking, population membership does not significantly moderate the effect of anxiety on depression.
= 1.055, df = 1, P = 0.3044, indicating that H0-1 cannot be rejected. In other words, the effect of anxiety on depression remains invariant among rural drug users in Ohio and Kentucky. Statistically speaking, population membership does not significantly moderate the effect of anxiety on depression.
Alternatively, the null hypothesis H0-1 can also be tested using the MODEL TEST command. This command is a very useful tool that allows a variety of specific null hypotheses to be tested, including testing multiple hypotheses simultaneously. In the following Mplus program, we show how to use the MODEL TEST command to test equality of the effect of anxiety on depression across groups.
Mplus Program 5.20

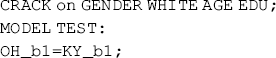
where OH_b1 and KY_b1 are placed in parentheses to represent the slope coefficients of regressing DEP on ANX in different groups. The line following the MODE TEST command (i.e., OH_b1=KY_b1) allows the null hypothesis H0-1 to be tested. Mplus provides a Wald test: ![]() = 0.060, df = 1, P = 0.8069, leading to the same testing conclusion as the two-step test result. Note that using MODE TEST to test the hypothesis does not influence model parameter estimates since the Wald test is performed after the model parameters are estimated. In the Mplus output we can see that the estimated slope coefficient of regressing DEP on ANX is 0.851 (P < 0.001) for Ohio and 0.830 (P = 0.000) for Kentucky, which are not identical to each other.
= 0.060, df = 1, P = 0.8069, leading to the same testing conclusion as the two-step test result. Note that using MODE TEST to test the hypothesis does not influence model parameter estimates since the Wald test is performed after the model parameters are estimated. In the Mplus output we can see that the estimated slope coefficient of regressing DEP on ANX is 0.851 (P < 0.001) for Ohio and 0.830 (P = 0.000) for Kentucky, which are not identical to each other.
Test invariance of indirect effect across groups: Noninvariance of an indirect effect across groups means existence of an interaction of the indirect effect and the group membership. James and Brett (1984) used the term moderated mediation to describe this kind of interaction. A special approach has been proposed to test invariance of indirect effects in SEM (Wai, 2007). However, testing for invariance of indirect effects can be readily conducted in Mplus. In the following section we will test null hypothesis H0-2, which is proposed to test whether the indirect effect of crack-cocaine use on depression via anxiety is invariant across different populations. This indirect effect can be portrayed as Crack → ANX → DEP, and can be estimated as ![]() ∗
∗![]() where
where ![]() is the direct effect of Crack on ANX and
is the direct effect of Crack on ANX and ![]() is the direct effect of ANX on DEP (see Figure 3.4). In the following Mplus program we will use the MODEL CONSTRAINT command to generate the indirect effect for each group; and then use MODEL TEST command to test H0-2.
is the direct effect of ANX on DEP (see Figure 3.4). In the following Mplus program we will use the MODEL CONSTRAINT command to generate the indirect effect for each group; and then use MODEL TEST command to test H0-2.
Mplus Program 5.21


where the names of the direct effects of ANX on DEP are labeled as b23_OH and b23_KY for Ohio and Kentucky, respectively. The names of the direct effects of Crack on ANX are labeled as b31_OH and b31_KY for Ohio and Kentucky, respectively. The MODEL CONSTRAINT command is used to generate the indirect effect of Crack on DEP via ANX in each group (ind_OH for Ohio and ind_KY for Kentucky), which is the product of two direct effects. The MODEL TEST command provides a Wald test for testing the null hypothesis H0-2: ![]() = 2.521, df = 1, P = 0.1124, indicating that the H0-2 hypothesis cannot be rejected; that is, the indirect effect of crack-cocaine use on depression via anxiety is invariant among rural drug using populations for Ohio and Kentucky.
= 2.521, df = 1, P = 0.1124, indicating that the H0-2 hypothesis cannot be rejected; that is, the indirect effect of crack-cocaine use on depression via anxiety is invariant among rural drug using populations for Ohio and Kentucky.