
11
Resolving the Alignment Problem in Visual Cryptography
Feng Liu
Institute of Software, Chinese Academy of Sciences, China
CONTENTS
11.1 Introduction
The basic principle of the Visual Cryptography Scheme (VCS) was first formally introduced by Naor and Shamir [10]. The idea of the VCS proposed in [10] is to split an image into two random shares (printed on transparencies), which separately reveal no information about the original secret image other than the size of the secret image. The image is composed of black and white pixels. The original image can be recovered by stacking the two transparencies together.
One important parameter in VCS is pixel expansion, where the pixel expansion reflects the size of the recovered secret image. Many papers in the literature are dedicated to proposing VCS with smaller pixel expansion. However, all these works are based at the pixel level, i.e., to reduce the number of subpixels that represent a pixel of the original secret image.
We notice that, the final goal of reducing the pixel expansion is to reduce the size of the transparencies that are distributed to the participants, because smaller transparencies are easier to transport. However, the size of the subpixels that are printed on the transparencies affects the final size of the transparencies; in fact, the size of the transparencies is the product of the size of the subpixels and the number of the subpixels in each transparency. Unfortunately, there is a dilemma when one tries to determine the size of the subpixels: When the subpixel size is large, it is easy to align the shares (most publications in the literature require aligning the shares precisely in the decrypting phase), but the large subpixel size will result in large transparencies. On the other hand, when the subpixel size is small, it is relatively hard to align the shares, but smaller transparencies result. From the point of view of the participants of the VCS, the goal is to align the shares easily and have small transparencies as well. Table 11.1 shows the relationship between the size of the subpixels of the transparencies and the ease to align them (more comparisons will be given in Table 11.5 later). Hence, there is a trade-off between the size of the subpixels of the transparencies and the ease to align them.
Table 11.1 The advantages and disadvantages of large and small subpixels.
| size of the subpixels | advantages | disadvantages |
| larger | easier to align | larger transparency size |
| smaller | smaller transparency size | harder to align |
The usual way of tackling the alignment problem of the VCS is by adding frames to the shares. To align the shares one just needs to align the frames. Yan et al. [13] employed the Walsh transform to embed marks in both of the shares so as to find the alignment position of these shares. However, both methods need to align the transparencies precisely. Besides, Kobara and Imai [6] considered a different problem. They calculated the visible space when viewing the transparencies. The results are somehow related to the alignment problem, but not exactly, as [6] has no discussion about alignment at all. Kobara and Imai [6] do not consider the stacking of more than two shares. Nakajima and Yamaguchi [9] proposed a (2, 2), extended VCS, which the secret image and shares are natural images. Their scheme can simultaneously reduce the alignment difficulty. However, their scheme does not hold the perfect security like a secret sharing scheme.
In fact, the precise alignment of small subpixels is not critical. The secret image can still be recovered visually even if the participants do not align the transparencies precisely. This phenomenon helps to determine the size of the subpixels printed on the transparencies.
This chapter focuses on some recent results about the alignment problem of the visual cryptography scheme [8, 16]. Two kinds of alignment problems of share images are considered. First, the share images are misaligned by integer number of subpixels (less than the pixel expansion). This part mainly comes from [8]. In such a case, the secret image can still be observed as its complementary image. Second, the share images are misaligned by less than one subpixel. This part mainly comes from [16]). Conditions that the secret image can still be recovered are studied, and the different misalignment tolerances of large and small subpixels are compared. The results indicate that the VCS, by itself, has some misalignment tolerance. At last, we provide a misalignment tolerant VCS based on the trade-off between the usage of large and small subpixels.
11.2 Preliminaries
In the VCS, there is a secret image that is encrypted into some shares. The secret image is called the original secret image for clarity, and the shares are the encrypted images (and are called the transparencies if they are printed). When a qualified set of shares (transparencies) are stacked together, it gives a visual image that is almost the same as the original secret image, we call it the recovered secret image. In the case of black and white images, the original secret image is represented as a pattern of black and white pixels. Each of these pixels is divided into subpixels, which themselves are encoded as black and white to produce the shares. The recovered secret image is also a pattern of black and white subpixels that should visually reveal the original secret image if a qualified set of shares is stacked.
In order to simplify the discussion, in this paper, we will only consider the black and white VCS, where black pixels are denoted by 1 and white pixels are denoted by 0.
By a (k, n)-VCS we mean a scheme where the original secret image is divided into n shares, which are distributed to n participants. Any subgroup of k out of these n participants can get a recovered secret image, but any subgroup consisting of less than k participants does not have any information other than the size about the original secret image.
For a vector v ∈ GFm(2), we denote by w(v) the Hamming weight of the vector v, i.e., the number of nonzero coordinates in v. A (k, n)-VCS, denoted by (C0,Cı), consists of two collections of n × m binary matrices C0 and C1. To share a white (resp. black) pixel, a dealer (the one who sets up the system) randomly chooses one of the matrices, called a share matrix, in C0 (resp. C1) and distributes its rows (representing a pattern of subpixels in the share) to the n participants of the scheme, giving row i to participant i, i = 1, …, n. More precisely, we give a formal definition of the (k, n)-VCS as follows:
Definition 1 Let k, n, m be nonnegative integers, l and h be positive numbers satisfying 2 ≤ k ≤ n and 0 ≤ l < h ≤ m. The two collections of n × m binary matrices (C0,C1) constitute a visual cryptography scheme (k, n)-VCS if the following properties are satisfied:
(Contrast) For any s ∈ C0, the OR of any k out of n rows of s is a vector v that satisfies w(v) ≤ l.
(Contrast) For any s ∈ C1, the OR of any k out of n rows of s is a vector v that satisfies w(v) ≥ h.
(Security) For any i1 < i2 < … < it in {1,2, … ,n} with t < k, the two collections of t × m matrices Dj, j = 0, 1, obtained by restricting each n×m matrix in Cj, j = 0, 1, to rows i1, i2 … it, are indistinguishable in the sense that they contain the same matrices with the same frequencies.
Note that, in the above definition,
m is called the block length and determines the pixel expansion of the scheme. A pixel of the original secret image is represented by m subpixels in the recovered secret image. In general, we are interested in schemes with m being as small as possible. h and l are called the darkness thresholds of the black and white pixels, respectively.
Define the value α=h−lm
α=h−lm to be the contrast of the scheme. Note that, however, there are other definitions of the contrast of VCS. We use this definition to establish our result. The proof is similar for other definitions of contrast.
We consider VCS in which C0, C1 are constructed from a pair of n × m binary matrices M0, M1, called basis matrices. The set Ci, i = 0,1 consists of the m! matrices obtained by applying all permutations to the columns of Mi. This approach of VCS construction will have small memory requirements (it only keeps the basis matrices) and high efficiency (to choose a matrix in C0 (resp. C1) as it only needs to generate a permutation of the basis matrix). We will use the basis matrices to simplify the discussions.
The above definition of VCS is also called the Deterministic Visual Cryptography Scheme (DVCS). The original secret image can be deterministically recovered by the qualified shares pixel by pixel in such schemes. In contrast to the DVCS, Yang and Cimato et al. proposed the Probabilistic Visual Cryptography Scheme (PVCS) in [14, 4], where the pixels of the original secret image can only be probabilistically recovered by the qualified shares, however, in the overall view the original secret image can be recovered visually as well.
Definition 2 (Probabilistic VCS [14, 4]) Let k, n, and m be nonnegative integers, I and h be positive numbers, satisfying 2 ≤ k ≤ n and 0 ≤ l < h ≤ m . The two collections of n x m binary matrices (Co,Ci) constitute a probabilistic threshold Visual Cryptography Scheme (k, n)-PVCS if the following properties are satisfied:
(Contrast) For the collection C0 and a share matrix s ∈ C0, by v a vector resulting from the OR of any k out of the n rows of s. If w(v) denotes the average of the Hamming weights of v, over all the share matrices in C0, then ˉw(υ)≤ˉl
w¯¯¯(υ)≤l¯ .(Contrast) For the collection C1, the value of ˉw(υ)
w¯¯¯(υ) satisfies ˉw(υ)≥ˉhw¯¯¯(υ)≥h¯ .(Security) For any i1 < i2 < … < it in {1, 2, … ,n} with t < k, the two collections of t × m′ matrices Dj, j = 0, 1, obtained by restricting each n × m′ matrix in Cj, j = 0, 1, to rows i1, i2, … it are indistinguishable in the sense that they contain the same matrices with the same frequencies.
The definition of PVCS in [14] only considers the case with n × 1 share matrices, we extend their definition to the n × m′ case. And the definition of PVCS in [4] used the factor ß to reflect the contrast, we use the values ˉl
The contrast of the DVCS is fulfilled for each pixel (consisting of m sub-pixels) in the recovered secret image, however, this is quite different in the PVCS. The application of the average contrast, denoted by ˉα
11.3 Misalignment with Integer Number of Subpixels
According to the traditional view, the subpixels of the transparencies should be aligned precisely. Here, we point out that, to recover the secret image visually, it is not necessary to align the subpixels precisely. In this section, we will only consider the misalignment with integer number of subpixels.
We will show that, by shifting one of the shares by some number (at most m − 1) of subpixels to the right (resp. left), one can still recover the secret image visually, for the reason that the average contrast ˉα≠0
We first give an example to show this phenomenon.
Example 1 We take the (2, 2)-DVCS as an example, where the basis matrices of the scheme are,
M0=[100100] and M1=[100010]

FIGURE 11.1
The stacking results of the (2,2)-DVCS (a) when no share is shifted; (b) when one share is shifted by one subpixels; (c) when one share is shifted by two subpixel. A printed-text ”CRYPTO” is tested.
Figure 11.1 are the experimental results of the recovered secret image, where (a) is the recovered secret image without being shifted, and (b) is the recovered secret image with the second share being shifted to the left by one subpixel, and (c) is the recovered secret image with the second share being shifted to the left by 2 subpixels. From the experimental results we notice that, the original secret image can be recovered visually by shifting one or two subpixels for the (2, 2)-DVCS with pixel expansion m − 3. And the clearness of the recovered secret image with two subpixels being shifted is not as clear as the one with one subpixel being shifted. Furthermore, the shifted scheme is not a DVCS anymore; we give an example to show this point:
Example 2 Take the share matrices S0=[010010]
S00=[*0|010100] S01=[*0|010101] S10=[*0|100100] S11=[*0|100101]
where Sij, i=0,1,j=0,1
For the above four shifted share matrices, the stacking Hamming weights are 2, 3, 1, and 2. In particular, the stacking Hamming weight of S00
Generally, we aim at proving the conclusion that, the shifted scheme can visually recover the original secret image based on the (k, n)-DVCS. However, it is noticed that this proof can be reduced to the proof based on the (2, 2)-DVCS in the case that only one share is shifted. The reason is as follows:
First, a (k, n)-DVCS consists of (nk) (k,k)
Second, denote the k shares of a (k, k)-DVCS as s1, s2, ⋯ ,sk, without loss of generality, let sk be the share that is shifted, and let s′k
We analyze the structure of the basis matrix of the (2, 2)-DVCS. Denote M0 and M1 as the basis matrices of the (2, 2)-DVCS, then the M0 and M1, without loss of generality, are in the following form:
M0=[1⋯10⋯01⋯10⋯01⋯1︸a0⋯0︸b0⋯0︸c1⋯1︸d],
and
M1=[1⋯10⋯01⋯10⋯01⋯1︸a′0⋯0︸b′0⋯0︸c′1⋯1︸d′],
where a, b, c, d, a′, b′, c′, and d′ are nonnegative integers satisfying a+c+d = l and a′ + c′ + d′ = h. According to the contrast and security property of Definition 1, we have,
{a+b+c+d=a′+b′+c′+d′a+c=a′+c′a+d=a′+d′b>b′
solving the above equations, we get a − a' = b − b' = c' − c = d′ − d. Let e = b − b', hence, by deleting identical columns of M0 and M1, we get,
M′0=[1⋯10⋯01⋯1︸e0⋯0︸e]
and,
M′1=[1⋯10⋯00⋯0︸e1⋯1︸e]
where the number of columns in M′0
Now we know that the basis matrices of an arbitrary (2, 2)-DVCS M0 and M1 contain the same number of identical columns [11],[10],[01]
M0=[1⋯10⋯01⋯10⋯01⋯10⋯01⋯1︸a′0⋯0︸b′0⋯0︸c′1⋯1︸d1⋯1︸e0⋯0︸e]
and
M1=[1⋯10⋯01⋯10⋯01⋯10⋯01⋯1︸a′0⋯0︸b′0⋯0︸c1⋯1︸d0⋯0︸e1⋯1︸e].
Let m be the pixel expansion, then it is obvious that m = a' + b' + c + d + 2e. The collections C0 and C1 contain all the permutations of the basis matrices M0 and M1 , and hence each has m! share matrices.
The shifted scheme is generated as follows:
Shift the second row of the m! share matrices in C0 (resp. C1) to the left (resp. right) by r subpixels, and let c1,c2, ⋯ ,cr be the r-bit string that is shifted in, where each ci ∈ {0,1} represents a subpixel. By the above discussion, we get m! shifted share matrices for C0 (resp. C1). Take the share matrix M0 ∈ C0 as an example, then the shifted share matrix, denoted by M(r)0
M(r)0=[*⋯*1⋯10⋯01⋯10⋯01⋯10⋯01⋯1︸a′0⋯0︸b′0⋯0︸c1⋯1︸d1⋯1︸e0⋯0︸ec1⋯cr︸r],
where c1 ⋯ cr of share 2 are the adjacent subpixels of the right pixel that are shifted in.
By going through all m! share matrices of C0 and C1 and all the possible string of subpixels c1 ⋯ cr ∈ {0,1}r, where {0,1}r is the set of all the binary strings of length r, the shifted scheme is generated. Hence, we have:
Theorem 1 The shifted scheme of a DVCS is a PVCS, where the average contrast of the shifted scheme is ˉα=−(m−r)em2(m−1)
Proof: Without loss of generality, we only prove the case when the share 2 is shifted to the left, which is equivalent to the case when the share 1 (the first share) is shifted to the right. Note that, swapping rows 1 and 2 corresponds to swapping the parameters c and d. We observe that, since the share matrices of the DVCS satisfy condition 3 of Definition 1 and the shifting operation is the same for matrices in C0 and C1, the share matrices of the shifted scheme satisfy condition 3 of Definition 2.
First, we prove the case that the share 2 is shifted by one subpixel, and then we extend it to the case when it is shifted by r subpixels.
When share 2 is shifted by one subpixel, the adjacent right subpixel of share 2 is shifted in. Let p1 be the probability that a 1 is shifted in, and p0 be the probability that a 0 is shifted in. Because the share matrices are all the permutations of the basis matrices, so p1 and p0 have fixed values and p1 + p0 = 1, i.e., the shifted in subpixel is either 1 or 0. More precisely, by the above discussion we have p1=a′+d+em
Because, under the OR operation, the stacking of two black subpixels results in a black subpixel, i.e., 1 OR 1 = 1, so this means that there is a black subpixel that is ineffective (overlapped). Now we define a black pixel (value 1) to be ineffective if it does not contribute to the total number of black pixels in the recovered secret image. There are three cases when a black subpixel 1 is ineffective: (1) when that is in the top right corner of the matrix M0 (or M1) and another 1 is shifted in, this results in a overlap; (2) when that is in the bottom left corner of the matrix which is then shifted out (appear below an asterisk ‘*’); and (3) when an overlap happens after a shift, which is possible on the first m − 1 positions (and m − r positions in general). Hence, the total Hamming weight of the stacking of the shifted share matrices can be calculated by the total number of the 1’s subtracted by the number of the 1’s that are ineffective (when two 1’s overlapped, we only count one as ineffective).
In the first case, denote by s10,c
In the second case, denote by s20,c
In the third case, denote by s30,c
Table 11.2 The probability of the four patterns appearing at the columns i and i + 1 in the collections C0 and C1.
| collectionspatterns | [1011] |
[1111] |
[1001] |
[1101] |
| C1 | a′md+em−1 |
a′ma′−1m−1 |
c+emd+em−1 |
c+ema′m−1 |
| C0 | a′+emdm−1 |
a′+ema′+e−1m−1 |
cmdm−1 |
cma′+em−1 |
The collection C0 and C1 contain all the column permutations of the basis matrices in all possible ways, and there are only m − 1 choices for the value of i, so the total number of 1’s that are ineffective of the four patterns of the collection C1 is S31,1=S31,0=(a′md+em−1+a′ma′−1m−1+c+emd+em−1+c+ema′m−1)(m−1)m!
Denote the total number of 1’s in the share matrices in collections C0 and C1 plus the number of 1’s in the subpixel c that is shifted in as T0, c and T1, c, respectively. Then, when a 1 is shifted in, we have T0,1 = T1, 1 = (2a' + c + d + 2e + 1)m!, and when a 0 is shifted in, we have T0,0 = T1, 0 = (2a' + c+d+2e)m!.
Denote Tc, C as the total stacking Hamming weight of all the matrices of the collection C (C0 or C1) when a string of subpixels c are shifted in. The above discussion shows that when a 1 is shifted in, the total stacking Hamming weight of all the matrices of the collection C1 is
T1,C1=T1,1−s11,1−s21,1−s31,1 =[(2a′+c+d+2e+1)−a′+d+em−a′+c+em −(a′(d+e)m+a′(a′−1)m+(c+e)(d+e)m+(c+e)a′m)]m!
and that of the collection C0 is
T1,C0=T0,1−s10,1−s20,1−s30,1 =[(2a′+c+d+2e+1)−a′+d+em−a′+c+em −((a′+e)dm+(a′+e)(a′+e−1))m+cdm+c(a′+e)m)]m!
When a 0 is shifted in, the total stacking Hamming weight of the collection C1 is,
T0,C0=T1,0−s11,0−s21,0−s31,0 =[(2a′+c+d+2e)−a′+d+em− (a′(d+e)m+a′(a′−1)m+(c+e)(d+e)m+(c+e)a′m)]m!
and that of the collection C0 is
T0,C0=T0,0−s10,0−s20,0−s30,0 =[(2a′+c+d+2e)−a′+d+em− ((a′+e)dm+(a′+e)(a′+e−1)m+cdm+c(a′+e)m)]m!
We now define the average stacking Hamming weight of each share matrix to be the total stacking Hamming weight of all the share matrices being divided by the number of the share matrices, i.e., Tc,Cm!
DA=(T1,C1−T1,C0)p1+(T0,C1−T0,C0)p0=−e(p1+p0)m=−em
According to the definition of the average contrast in Section 11.2, with ˉh=T1,C1p1+T0,C1p0
Now we consider the general case when the share 2 is shifted by r subpixels. For this case there are 2r possible subpixels that can be shifted in. For example, for r = 2, the shifted in strings of subpixels have four cases, 00, 01, 10 and 11. Denote by p00, p01 p10 and p11 the probabilities of these four cases to happen respectively, then we have p00 + p01 + p10 + p11 = 1.
We consider the string of subpixels c, let the Hamming weight of c be s, i.e., w(c) = s. The total number of 1’s that are ineffective in the top right corner of all the share matrices in C0 and C1 is s10,c=s11,c=s ·a′+c+emm!
(a′md+em−1+a′ma′−1m−1+c+emd+em−1+c+ema′m−1)(m−r)m!
and of the collection C0 is
(a′+emdm−1+a′+ema′+e−1m−1+cmdm−1+cma′+em−1)(m−r)m!
Hence, when a string of subpixels of c is shifted in, the total stacking Hamming weight of all the matrices of the collection C1 is
Tc,C1=[(2a′+c+d+2e+s)−r⋅a′+d+em−s⋅a′+c+em −(a′(d+e)m+a′(a′−1)m+(c+e)(d+e)m+(c+e)a′m)m−rm−1]m!
and that of the collection C0 is
Tc,C0=[(2a′+c+d+2e+s)−r⋅a′+d+em−s⋅a′+c+em −((a′+e)dm+(a′+e)(a′+e−1))m+cdm+c(a′+e)m)m−rm−1]m!.
Hence, the difference between the average stacking Hamming weight of each share matrix of the shifted collections C0 and C1, denoted by DA, is
DA=(T1⋯1,C1−T1⋯1,C0)p1⋯1+⋯+(T0⋯0,C1−T0⋯0,C0)p0⋯0 =−e(p1⋯1+⋯+p0⋯0)mm−rm−1 =−emm−rm−1
and the average contrast is
ˉα=DAm=−em2m−rm−1.
Because the shifted scheme is not a DVCS anymore and ˉα ≠ 0, let ˉh=T1⋯1,C1p1⋯1+⋯+T0⋯0,C1p0⋯0
Note that, after a shift, the value of the average contrast has a negative value ˉα < 0
The above Theorem 1 shows that, to align the transparencies when decrypting the DVCS, one does not need to align the transparencies precisely. So, when the participants of a DVCS want to align the transparencies, for example, the transparencies in Example 1, they can first align the transparencies precisely in the vertical direction, and then move the second transparencies to the right then to the left in the horizontal direction. Then they will get the recovered secret image for three times. Furthermore, this phenomenon also helps to determine the size of the subpixels printed on the transparencies.
For other visual cryptography schemes, such as the extended visual cryptography schemes in [2], the visual cryptography schemes for the general access structures [1] and the color visual cryptography schemes [15, 12], they all have the phenomenon stated above. The proof for these visual cryptography schemes can be modified from that of Theorem 1.
11.4 Misalignment with Less Than One Subpixel
In this section, we do further investigation on misalignment with less than one subpixel. We show that the secret image can still be recovered visually by a slight misalignment. We first give an example, a (2, 2)-VCS, to show this phenomenon. Denote (dx, dy) as the horizontal and vertical misalignment deviations from the original position of the subpixel.
Example 3 The images (a), (b), and (c) in Figure 11.2 show the recovered secret image of a (2,2)-VCS for three misalignment deviations, (dx,dy) = (0, 0), (0.5, 0), and (1, 2) (unit: subpixel).

FIGURE 11.2
Recovered secret images of a (2,2)-VCS for three misalignment deviations (a) (dx,dy) = (0,0), (b) (dx,dy) = (0.5,0), and (c) (dx,dy) = (1, 2).
From Figure 11.2, we can observe that, the clearness ofFigure 11.2 (b) is worse than the Figure 11.2 (a), and the secret on Figure 11.2 (c) is completely invisible.
Figure 11.2 shows the case that only two shares are superimposed. The misalignment problem will become more complex for stacking k shares for a ( k, n)-VCS. Note that, the recovered image will disappear if any one out of k shares is not at the correct position. In fact the misalignment problem critically increases as k grows.
The next two subsections are organized as follows: first, we will investigate the conditions that the secret image can still be observed when the shares are slightly misaligned, whereby saying slight misalignment we mean deviation (dx, dy) satisfying 0 ≤ dx, dy ≤ 1; and then we will investigate the misalignment tolerance of large and small pixels. To simplify the discussion, we only consider the case of (2, 2)-VCS.
11.4.1 Shares with Slightly Misalignment Can Still Recover the Secret Image
We consider a (2, 2)-VCS with deviation (dx, dy), where a pixel 1W1B (resp. 1B1W) represents a white pixel that contains a white (resp. black) and a black (resp. white) subpixel; and a pixel 2B0W represents a black pixel that contains two black subpixels. All possible four cases, (a1), ( a2), (b1), and (b2), of stacked shares with deviation (dx, dy) are shown in Figure 11.3. The stacked results in Figure 11.3 are marked with red boxes. As shown in Figure 11.3, the stacked result is divided into eight parts. Denote A1, A2, A3, A4, A′1, A′2, A′3 and A′4 as the areas of the eight parts respectively, and they satisfy the following equations.
A1=A′1=dxdyA2=A′2=(s−dx)dyA3=A′3=dx(s−dy)A4=A′4=(s−dx)(s−dy)A1+A2+A3+A4=s2(11.1)
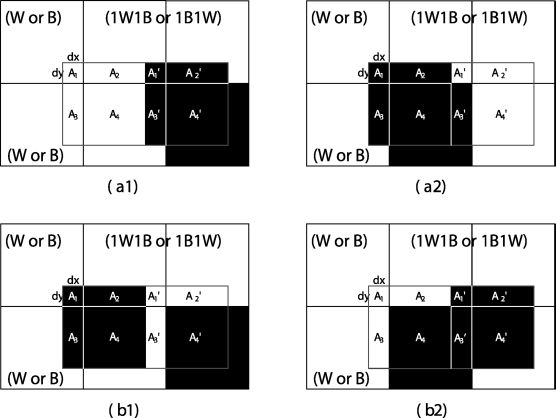
FIGURE 11.3
Stacked results of white pixels (a1: 1W1B+H1W1B, a2: 1B1W+ 1B1W) and black pixels (b1: 1W1B+1B1W, b2: 1B1W+1W1B) for the same deviation ( dx, dy).
Denote s × s as the size of a subpixel, and denote AC, C as the area in the stacked results with color C ∈ {W, B} for case c ∈ (a1), (a2), (b1), and (b2). Note that, some areas are not deterministic in Figure 11.3, for example the area A1 in Figure 11.3 (a1) belongs to the adjacent pixel on the top left. It can be either black or white with equal probability 50%. We introduce a symbol P(A) to denote it, i.e., P(A) is the area of A to be either black or white with equal probability 50%. Furthermore, we denote P(A1,A2) as the area that is either A1 or A2 with equal probability 50% since there exist such cases that one of two areas is black and the other is white, for example the areas A′1 or A′2 in Figure 11.3 (a2). The symbols P(A) and P(A1, A2) satisfy the following equations:
min{P(A)}=0max{P(A)}=AˉP(A)=A/2min{P(A1,A2)}=min{A1,A2}max{P(A1,A2)}=max{A1,A2}ˉP(A1,A2)=A1/2+A2/2(11.2)
According to Figure 11.3, it is easy to verify the following equations:
AW,a1=P(A1)+P(A2)+P(A3)+A4AB,a1=P(A1)+P(A2)+P(A3)+A′1+A′2+A′3+A′4AW,a2=P(A′1,A′2)+A′4AB,a2=A1+A2+A3+A4+P(A′1,A′2)+A′3AW,b1=P(A′1+A′2)+A′3AB,b1=A1+A2+A3+A4+P(A′1+A′2)+A′4AW,b2=P(A1)+P(A2)+P(A3)AB,b2=P(A1)+P(A2)+P(A3)+A4+A′1+A′2+A′3+A′4(11.3)
The following Theorem 2 shows that the stacked shares with slight misalignment can still recover the secret image. Note that, by saying the secret image is recovered by its original color, we mean that a black (resp. white) pixel in the secret image is represented by a black (resp. white) pixel in the recovered secret image; and by saying the secret image is recovered by its complementary color, we mean that a black (resp. white) pixel in the secret image is represented by a white (resp. black) pixel in the recovered secret image. In order to consist with Definition 1 and Definition 2, we generalize the definition of contrast α and average contrast ˉα
α=h−l2s2 and ˉα=ˉh−ˉl2s2(11.4)
where 2s2 is the area of a pixel (including two subpixels) and the definitions of h, l, ˉh
Theorem 2 For a misaligned (2, 2)-VCS, denote (dx,dy) as the deviation of the stacked shares, then the secret image can still be recovered if(dx, dy) falls in the regions of R1, R2, and R3 in Figure 11.4, where the properties of the misaligned scheme are shown in Table 11.3.
Proof: Denote lWblack area (resp. hBblack area)
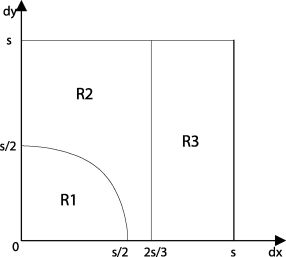
FIGURE 313.11
The regions of deviation ( dx, dy) that can recover the secret image.
Table 11.3 The properties of the misaligned schemes.
| regions | R1 | R2 | R3 |
| (dx, dy) satisfy | (s − dx)(s − dy) > s2/2 0 ≤ dx,dy < s | 0 ≤ dx < 2s/3 0 ≤ dy < s | 2s/3 < dx ≤ s 0 ≤ dy < s |
| misaligned scheme | DVCS | PVCS | DVCS |
| contrast | αR1=s2−2(dx+dy)s+2dxdy2s2 |
ˉαR2=(2s−3dx)(s−dy)4s2 |
ˉαR3=−(3dx−2s)(s−dy)4s2 |
| recovered secret image | original color | original color | compl ementary color |
lWblack area
lWblack area=max{AB,a1,AB,a2} =max{P(A1)+P(A2)+P(A3)+A′1+A′2+A′3+A′4 A1+A2+A3+A4+P(A′1,A′2)+A′3} =A1+A2+A3+A4+ max{P(A1)+P(A2)+P(A3),P(A′1,A′2)+A′3} =A1+A2+A3+A4+A1+A2+A3 =s2+A1+A2+A3 =2s2−A4(11.5)
hBblack area
hBblack area=min{AB,b1,AB,b2}=s2+A4(11.6)
ˉlWblack area
ˉlWblack area=ˉAB,a1+ˉAB,a22 =12[¯(P(A1)+P(A2)+P(A3)+A′1+A′2+A′3+A′4) +¯(A1+A2+A3+A4+P(A′1,A′2)+A′3)] =12[(ˉP(A1)+ˉP(A2)+ˉP(A3)+A′1+A′2+A′3+A′4) +(A1+A2+A3+A4+ˉP(A′1,A′2)+A′3)] =s2+A12+A22+3A34(11.7)
ˉhBblack area
ˉhBblack area=ˉAB,b1+ˉAB,b22=s2+A12+A22+A34+A4(11.8)
hBwhite area
hBwhite area=min{AW,b1,AW,b2}=0(11.9)
lWwhite area
lWwhite area=max{AW,a1,AW,a2}=s2(11.10)
ˉhBwhite area
ˉhBwhite area=ˉAW,b1+ˉAW,b22=A12+A22+3A34(11.11)
ˉlWwhite area
ˉlWwhite area=ˉAW,a1+ˉAW,a22=A12+A22+A34+A4(11.12)
According to Definition 1 (definition of a deterministic VCS), in order to deterministically recover the secret image by its original color, the values of lWblack area
αR1=hBblack area−lWblack area2s2=s2−2(dx+dy)s+2dxdy2s2
Similarly, in order to recover deterministically by its complementary color, the values of hBwhite area
According to Definition 2 (definition of a probabilistic VCS), in order to probabilistically recover the secret image by its original color, the values of ˉlWblack area
ˉαR2=hBblack area−lWblack area2s2=(2s−3dx)(s−dy)4s2
Similarly, in order to probabilistically recover the secret image by its complementary color, the values of ˉhBwhite area
ˉαR3=hBblack area−lWblack area2s2=(3dx−2s)(s−dy)4s2
The above Theorem 2 is consistent with Theorem 1. According to Theorem 1 and Theorem 2, for the deviation (dx, dy) = (s, 0), the secret image can be probabilistically recovered by its complementary color with average contrast ˉα=1/4.
The above Theorem 2 considers the deviations (dx, dy) less than one subpixel. In fact, when the value of dx is between s and 2s for a misaligned (2, 2)-VCS, the secret image can also be recovered. The proof is left to the interested readers.
11.4.2 Large Subpixels Have Better Misalignment Tolerance
In this subsection, we investigate the misalignment tolerance of the large and small subpixels. And show that shares with large subpixels have better misalignment tolerance when recovering the secret image by its original color than that with small subpixels. Denote the size of the large and small subpixels as s2 × s2 and s1 × s1 respectively, where s2 > s1. According to Figure 11.5, the recovered secret image using the small subpixels (Figure 11.5(a)) has a higher resolution than that using the large subpixels (Figure 11.5(c)). It is observed that Figure 11.5(a) indeed has the refined resolution in detail of Lena image. We can clearly view the hair in Figure 11.5(a) but the area of hair is all black in Figure 11.5(c). The image quality using the medium-sized subpixel (Figure 11.5(b)) is between Figure 11.5(a) and Figure 11.5(c). Although using large subpixels in share has poorer resolution, it will be more robust to the misalignment error. Next, the misalignment tolerance of different-sized subpixels is formally analyzed.

FIGURE 11.5
Recovered Lena images for (2,2)-VCS using the different sized subpixels: (a) the small-sized subpixel, (b) the medium-sized subpixel and (c) the large-sized subpixel.
Consider a misalignment deviation (dx, dy) in the (2, 2)-VCS. All the possible cases of stacked shares of a white secret pixel (1B1W) and a black secret pixel (2B0W) with a deviation (dx, dy) are shown in Figure 11.3. For the small subpixel (s1 × s1), we define the whiteness RW, a1 (resp. RW, a2) as the ratio of black area in a stacked two-subpixel area for the case a1 (resp. a2) in Figure 11.3, and the darkness RB, b1 (resp. RB, b2) as the ratio of the black area in a stacked two-subpixel area for the case b1 (resp. b2) in Figure 11.3. For the large subpixel (s2 × s2), the corresponding denotations are R′W,a1, R′W,a2, R′B,b1
To simplify the discussion, we only consider the one dimension deviation, i.e., (dx, 0) or (0, dy). Then we have the following one-dimensional deviation lemma.
Lemma 3 (One-dimensional deviation) The darkness and the whiteness ratios always satisfy R′W,a1≥RW,a1,R′W,a2≥RW,a2 R′B,b1≥RB,b1
Proof: We only consider the case with deviation (dx, 0) since the proof is the same for the case with deviation (0, dy). According to equation (11.1), when dy = 0, we have
A1=A′1=0A2=A′2=0A3=A′3=dxsA4=A′4=(s−dx)sA3+A4=s2(11.13)
We consider the relation of RC, c and R′C,c
RC,c=AC,c2s21 and R′C,c=AC,c2s22(11.14)
We have Table 11.4 to show the relation of RC, C and R′C,c
Table 11.4 The relation of the ratios RC, C and R′C,c
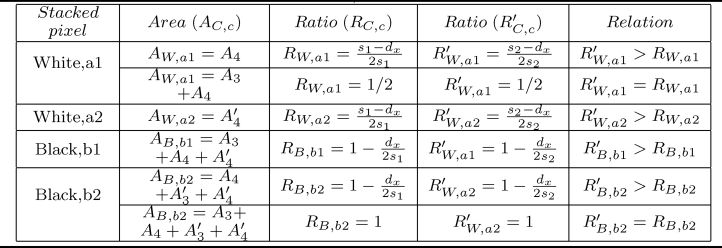
The proofs of the relations in Table 11.4 are quite similar. We only take the proof of the relation between R′W,a1
According to equation (11.3), for the stacked pixel of Figure 11.3 ( a1), there are two cases of AW, a1, i.e., I: AW, a1 = A4 and II: AW, a1 = A3 + A4.
For the Case I, we have RW,a1=AW,a12s21=A42s21=s1−dx2s1
For the Case II, we have R′W,a1−RW,a1=s222s22−s212s21=0
According to Table 11.4, the lemma follows. □
According to Lemma 3, for one-dimensional deviation, it is evident that if R′W≥RW

FIGURE 11.6
Recovered secret image for a (2, 2)-VCS using two different-sized subpixels and (dx ,dy ) = (0.5, 0.5), (s1/s2) = 2: (a) the small subpixel and (b) the large subpixel; two secret image (a printed text ”VSS” and a halftoned Lena image) are tested.
From the preceding description and the results in Figure 11.5 and Figure 11.6, unfortunately, there exists another dilemma of using the large or small subpixels. Together with previous comparisons in Table 11.1, we summarize the advantages and disadvantages of large and small subpixels in Table 11.5.
In order to bring these conflicting goals in a kind of balance, we properly distribute two-sized subpixels in shares to develop their specialities and simultaneously avoid corresponding disadvantages. Our method is based on the trade-off between the usage of large and small subpixels. Both two-sized subpixels create a trade-off, which a large size subpixel leads to the high misalignment tolerance but the low resolution, while the small subpixel has the opposite properties. Finally, we successfully reduce the difficulty of aligning shares. Designing our misalignment tolerant VCS therefore delivers the following problems: (1) What is the appropriate percentage of the large subpixel in a share? (2) What is the appropriate size ratio of the large subpixel to the small subpixel? (3) How do we arrange the large and small subpixels in one share?
Table 11.5 The advantages and disadvantages of large and small subpixels.
| size of the subpixels | advantages | disadvantages |
| larger | easier to align and better misalignment tolerance | larger transparency size and lower resolution |
| smaller | smaller transparency size and higher resolution | harder to align and worse misalignment tolerance |
11.5 A Misalignment Tolerant VCS
11.5.1 The Algorithm
Concerning the first two problems, both items (the percentage and the size ratio) can be used to trade the quality of the recovered secret image for the misalignment tolerance. Different percentages and size ratios will be experimented and analyzed in Section 11.5.2. Consider the third problem, how to arrange the large and small subpixels in one share. In this chapter, we arrange them in a regular mask or a random mask. Subsequently, we describe the encrypting/decrypting algorithm of a (k, n)-threshold misalignment tolerant VCS, when given a percentage (the item in Problem (1)), a size ratio (the item in Problem 2) and an arrangement mask (the item in problem (3)).
Notation Used:
I A gray secret image of size × × y.
γ2 The size ratio of a large to a small subpixel, i.e., γ2 = (s2/s1)2.
IS A small-scaled secret image of size × × y. This image is obtained by halftoning I into a binary image. Note that, this image is used for embedding small subpixels.
IB A large-scaled secret image of size (x/γ) × (y/γ). This image is obtained by reducing the secret image I to size (x/γ) × (y/γ) and then halftoning to a binary image. Note that, this image is used for embedding large subpixels.
PB (pS) VB and pS are percentages of large and small subpixels, respectively.
Mreg A regular mask of size (x/γ) × (y/γ). This mask is only designed for pB = ps = 50%. Figure 11.7(a) shows the regular mask with the alternate blocks, ![]() and
and ![]() , where a block
, where a block ![]() contains large subpixels and a block
contains large subpixels and a block ![]() contains small subpixels.
contains small subpixels.
Mran A random mask of size (x/γ) × (y/γ). This mask is designed for any pB and ps. At this time, ![]() and
and ![]() are randomly chosen according pB and ps, as shown in Figure 11.7(b).
are randomly chosen according pB and ps, as shown in Figure 11.7(b).
DB (∙) Let A = [ai, j] , where ai, j is the element of the i-th row and j-th column in A, be a matrix in C1 or C0. The function DB(∙) divides a secret pixel s into m large subpixels (bp)ij((bp)ij=0
DB(s)={(bp)ij=ai,jin A∈C0 for s is the white secret pixel.(bp)ij=ai,jin A∈C1 for s is the white secret pixel.
Ds(∙) Similar to DB(∙), it divides a secret pixel into m small subpixels (sp)ij
Amx,my(·)
O(i) n output shares, i ∈ [1, n], of size (x × mx) × (y × my).
I' The recovered secret image of size (x × mx) × (y × my).
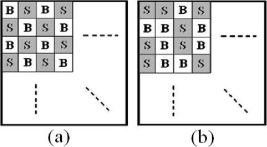
FIGURE 11.7
Regular and random masks for arranging the large and small subpixels: (a) regular mask and (b) random mask.
Even though the shares use a regular mask, an attacker could not gain any information from the mask and the secrecy is not compromised.
Encrypting Algorithm:
Input: I, γ2, pB, ps, C0 and C1 of a (k, n)-threshold VCS.
Output: O(i), i ∈ [1,n].
Step 1: Obtain the large-scaled and small-scaled secret images IB and Is from a secret image I.
Step 2: Use pB and pS to generate the Mran mask or choose the Mreg mask for the case pB = pS = 50%; let the chosen mask M = Mran or Mreg.
Step 3: For each block in the mask M, do the following:
Step 3-1: If the block is the large block ![]() , for the secret pixel ”s” in the corresponding block of the large-scaled image IB, do the following:
, for the secret pixel ”s” in the corresponding block of the large-scaled image IB, do the following:
Assign (bp)ij=DB(s)
Use Amx,my((bp)ij)
Step 3-2: If the block is the large block ![]() , for the secret pixel ”s” in the corresponding block of the large-scaled image IS, do the following:
, for the secret pixel ”s” in the corresponding block of the large-scaled image IS, do the following:
Assign (bp)ij=DS(s)
Use Amx,my((sp)ij)
Decrypting Algorithm:
Input: Any k shares from O(i), i ∈ [1, n].
Output: I′.
Step 1: Print out k shares on transparencies. Stack and align them by hand with the approximate accuracy.
/* Note that, when stacking shares the tradition VCS needs the precise alignment; the proposed scheme has the misalignment tolerance and so that one just aligns them roughly. */
Step 2: Decrypt the secret directly by human eyes.
Step 3: Align shares gradually to get a refined secret image of I′.
/* One can first align transparencies precisely in the vertical direction, and then move gradually by hand without losing the secret in the horizontal direction, finally the recovered secret image with no deviation can be obtained.*/
For easily understanding the encrypting algorithm, we herein give an example to show how to encode a secret image.
Example 4 Construct two shares by the (2, 2) misalignment tolerant VCS, where pB = pS = 50%, γ2 = 4, and Mreg are used. We use a 16 × 16-pixel secret image I, one black horizontal on a white background (Figure 11.8).
Since I is black and white now, so IS = I, and IB has the size of 8 × 8 pixels shown in Figure 11.8(a) and (b). By using Mreg (Figure 11.7(a)), we encrypt the first pixel in IB, which is a white secret pixel. Suppose the white pixel is divided into two subpixels (■□) in the first share O(1) and the corresponding two subpixels in the second share O(2) are also (■□). Subsequently, encrypt four small secret pixel in Is (see Figure 11.8(c)), these four white secret pixels  are respectively encrypted into
are respectively encrypted into  and
and ![]() in O(1) and O(2). According to the Mreg mask, encrypt all secret pixels in IB and IS. Finally, we obtain two shares O(1) and O(2) of 32 × 16 pixels.
in O(1) and O(2). According to the Mreg mask, encrypt all secret pixels in IB and IS. Finally, we obtain two shares O(1) and O(2) of 32 × 16 pixels.
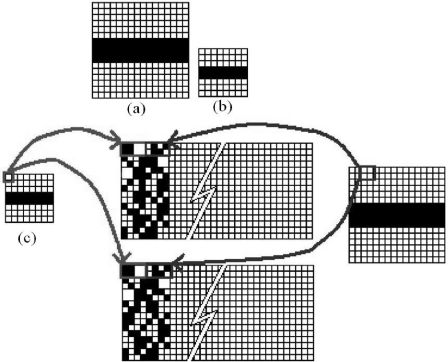
FIGURE 11.8
Encrypt a 16 × 16-pixel secret image by using a (2, 2) misalignment VCS, where pB = ps = 50%, γ2 = 4, and Mreg are used: (a) the small-scaled secret image IS,(b) the large-scaled secret image IB, and (c) two shares O(1) and O(2).
11.5.2 Simulations
In this section, we give some simulations to show the performance of the misalignment tolerant VCS for different deviations, size ratios, percentages, and masks. Example 5 uses fifty-fifty large and small subpixels with regular and random masks, respectively, such that we can try out the performance of the mask. In Example 6, we use different size ratios to study how the size ratio affects the visual quality and the misalignment tolerance.
Example 5 Construct the (2, 2) misalignment tolerant VCS, where pB = pS = 50% and γ2 = 16. Regular mask Mreg and random mask Mran are tested, respectively. The printed-text ”VSS”is used as a secret image.

FIGURE 323.11
Recovered secret images for a (2, 2) misalignment VCS using two-sized subpixels of γ2 = 16: (a) pB = 0%, (b) pB = pS = 50%, Mreg, (c) pB = pS = 50%, Mran and (d) pB = 100%, horizontal deviations: 0, 0.5, 1, and 2 are tested (unit: small subpixel).
Use the deviations (0, 0), (0.5,0), (1, 0), (1.5, 0) and (2, 0) to test the misalignment tolerance of the following four schemes: (a) pB = 0%, (b) PB = pS = 50%, Mreg, (c) pB = pS = 50%, Mran and (d) pB = 100%. Notice that (a) and (d) are just the traditional VCS with all small subpixels and large subpixels, respectively. The first scheme has the best resolution when aligning correctly, as shown in Figure 11.9 (a1), but the secret on the recovered secret image diminishes quickly when the deviation increases. The secret becomes invisible when the deviation is large enough (see Figure 11.9 (a5)). Comparing Figure 11.9 (a) and (d), the small subpixel gives the high resolution (see Figure 11.9 (a1) and (d1)), whereas the large subpixel enhances the misalignment tolerance. For example, the deviation is (dx, dy) = (2, 0), the secret in Figure 11.9 (a5) becomes invisible but we still visually view the secret ”VSS” in Figure 11.9 (d5). As shown in Figure 11.9 (a3) and (a4), the secret image is recovered by its complementary color. This interesting phenomenon is compatible with the result in Section 11.3 and Section 11.4. From these stacked results, our two-sized subpixel approach actually provides the misalignment tolerance. Also, it is observed that Figure 11.9 (b) (Mreg) has the better visual quality than Figure 11.9 (c) (Mran). This result is anticipated because the random arrangement of subpixels will introduce additional noise to the recovered secret image.
Example 6 Consider the first scheme in Example 5 (a (2, 2) misalignment tolerant VCS that the large and small subpixels are half used, respectively, and regularly arranged in a share). Three size ratios, γ2 = 4, 16, and 64, are tested. The printed-text ”VSS” is used as a secret image.

FIGURE 11.10
Recovered secret images for a (2, 2) misalignment tolerant VCS using pB = pS = 50%, Mreg and three size ratios: (a) γ2 = 4, (b) γ2 = 16 and (c) γ2 = 64, horizontal deviations: 0, 0.5, 1, 1.5, 2, 2.5, 3, and 3.5 are tested (unit: small subpixel).
Figure 11.10 (a–c) reveal the recovered secret images for γ2 = 4, 16, and 64, respectively. The clearness of the recovered secret image diminishes when the misalignment increases. The misalignment tolerant VCS using γ2 = 64 has the best misalignment tolerant capability, whereas it has the worst visual quality for no deviation. On the contrary, the misalignment tolerant VCS using γ2 =4 has a different characteristic. We may trade the misalignment tolerance for the image quality by the size ratio.
11.6 Conclusions and Discussions
This chapter is intended to show some recent results about the alignment problem of the VCS. We considered two kinds of misalignment, (1) misalignment with integer number of subpixels and (2) misalignment with less than one subpixel. In both cases, the secret image can be visually recovered. This phenomenon indicates that, the VCS, by itself, has some misalignment tolerance.
Then we compared the misalignment tolerance of large and small subpixels, and showed that the large subpixel had better misalignment tolerance. Based on this result, a misalignment tolerant VCS was given that traded the large and small subpixels in one share. Simulations were provided to show the performance of the misalignment tolerant VCS.
Because of the page limit, we cannot introduce more misalignment tolerant VCS. Interested readers can find more information about the alignment problem of the VCS in the following papers [8, 16, 13, 6, 9].
11.7 Acknowledgments
I gratefully acknowledge Prof. Chuankun Wu, as he introduced me to visual cryptography. We shared many pleasant memories on studying visual cryptography. This work was supported by NSFC grant No. 60903210.
Bibliography
[1] G. Ateniese, C. Blundo, A. De Santis, and D.R. Stinson. Visual cryptography for general access structures. In Information and Computation, volume 129, pages 86–106, 1996.
[2] G. Ateniese, C. Blundo, A. De Santis, and D.R. Stinson. Extended capabilities for visual cryptography. In ACM Theoretical Computer Science, volume 250 Issue 1-2, pages 143–161, 2001.
[3] E. Biham and A. Itzkovitz. Visual cryptography with polarization. In the Dagstuhl Seminar on Cryptography, September 1997, and in the RUMP Session of CRYPTO’98, 1997.
[4] S. Cimato, R. De Prisco, and A. De Santis. Probabilistic visual cryptography schemes. In The Computer Journal, volume 49, Number 1, pages 97–107, 2006.
[5] S. Droste. New results on visual cryptography. In CRYPTO ’96, Springer-Verlag LNCS, volume 1109, pages 401–415, 1996.
[6] K. Kobara and H. Imai. Limiting the visible space visual secret sharing schemes and their application to human identification. In ASIACRYPT ’96, Springer-Verlag LNCS, volume 1163, pages 185–195, 1996.
[7] H. Kuwakado and H. Tanaka. Size-reduced visual secret sharing scheme. In IEICE Transactions on Fundamentals, volume E87-A, No. 5, pages 1193–1197, 2004.
[8] F. Liu, C.K. Wu, and X.J. Lin. The alignment problem of visual cryptography schemes. In Designs, Codes and Cryptography, volume 50, pages 215–227, 2009.
[9] M. Nakajima and Y. Yamaguchi. Enhancing registration tolerance of extended visual cryptography for natural images. In Journal of Electronic Imaging, volume 13, pages 654–662, 2004.
[10] M. Naor and A. Shamir. Visual cryptography. In EUROCRYPT ’94, Springer-Verlag Berlin, volume LNCS 950, pages 1–12, 1995.
[11] R. Ito, H. Kuwakado, and H. Tanaka. Image size invariant visual cryptography. In IEICE Transactions on Fundamentals of Electronics, Communications and Computer Science, volume E82-A, No. 10, pages 2172–2177, 1999.
[12] S. J. Shyu. Efficient visual secret sharing scheme for color images. In Pattern Recognition, volume 39, pages 866–880, 2006.
[13] W.Q. Yan, D. Jin, and M.S. Kankanhalli. Visual cryptography for print and scan applications. In Proceedings of the 2004 International Symposium on Circuits and Systems, volume 5, pages 572–575, 2004.
[14] C.N. Yang. New visual secret sharing schemes using probabilistic method. In Pattern Recognition Letters, volume 25, pages 481–494, 2004.
[15] C.N. Yang and C.S. Laih. New colored visual secret sharing schemes. In Designs, Codes and Cryptography, volume 20, pages 325–335, 2000.
[16] C.N. Yang, A.G. Peng, and T.S. Chen. Mtvss:(m)isalignment (t)olerant (v)isual (s)ecret (s)haring on resolving alignment difficulty. In Signal Processing, volume 89, pages 1602–1624, 2009.