
12
Applications of Visual Cryptography
Bernd Borchert and Klaus Reinhardt
Universität Tühingen, Germany
CONTENTS
12.1 Introduction
Naor and Pinkas in their seminal paper [13] suggested to use visual cryptography in a transparency-on-screen version. Their main purpose was authentication, in the sense that an online server is able to authenticate itself to a user sitting in front of the screen. Implicitly, this already suggests the following application of visual cryptography to the problem of manipulation of online transactions, like online money transfers, by trojans:
Main Method. In order to secure online transactions, like online money transfers, the user gets a numbered set of transparencies, each with a visual cryptography pattern printed on it, from the transaction server. Now the user is able to command online transactions in a secure way, see Figure 12.1 as follows. He fills out an online form containing the data for the intended transaction; in the case of a money transfer this would be the account number and bank number of the destination bank account and the amount of the money. This transaction data is submitted via Internet to the server. The server does not execute the transaction immediately because in that case it would be an easy task for a man-in-the-middle to manipulate the transaction: the man-in-the-middle would just send his manipulated transaction to the server. In order to prevent such a manipulation, the server sends a visual message containing the transaction data to the user’s screen — but of course this image is not sent openly but instead it is encoded via visual cryptography: if the user puts the transparency with a certain number on top of the encoded image on the screen he can see the message contained within the image, i.e., the transaction data. Note that the image on the screen is random to a man-in-the-Middle, as this a guaranteed by visual cryptography. The number of the transparency requested to be used is shown by the server on the user’s screen together with the secret image. In order to finally confirm the transaction the user types a transaction number (TAN), which is additionally shown on the secret image message from the server, into a form on the screen and submits this TAN to the server. When the server receives the right TAN it executes the transaction, otherwise not.
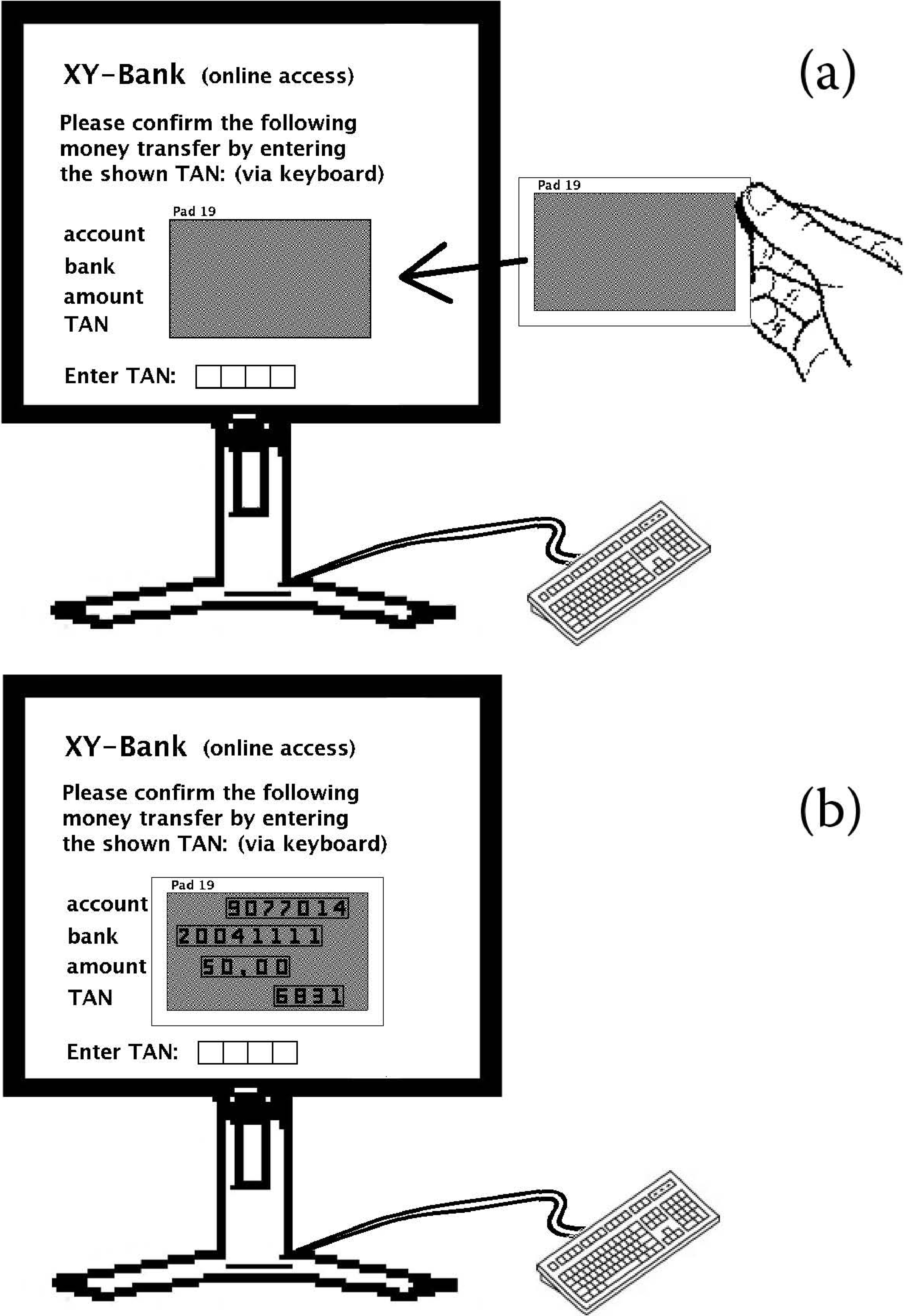
FIGURE 12.1
(a) The bank sends the information to be confirmed in an encrypted image to the user’s computer and (b) the user is able read this information using the transparency he got from the bank.
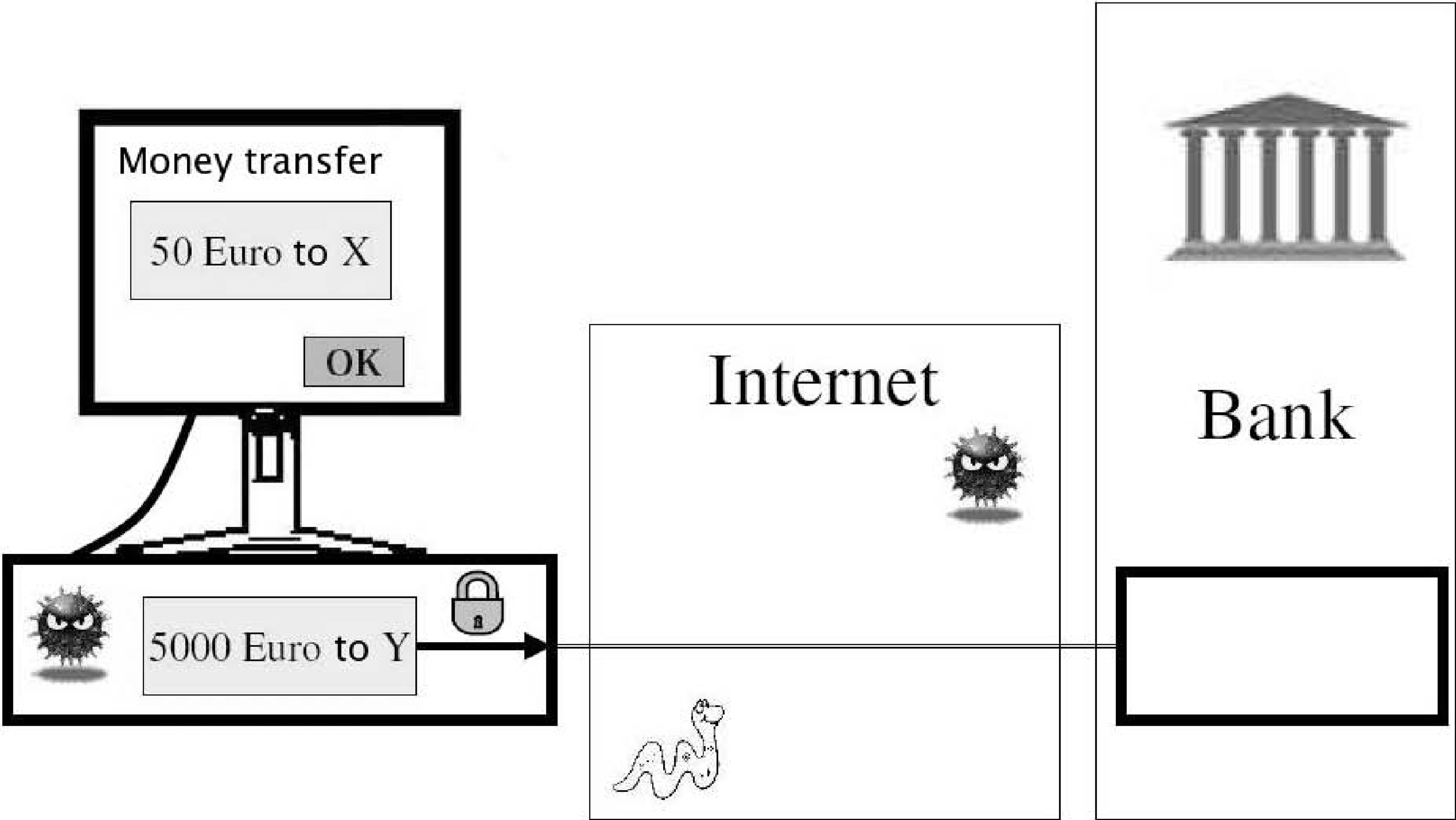
FIGURE 331.12
A man-in-the-middle manipulation attack by a trojan on an online money transfer.
Why does this method protect the transaction from being manipulated by a man-in-the-middle (which may be, for example, a trojan sitting on the user’s PC)? Because a man-in-the-middle does not know the transparencies the user got from the server, the man-in-the-middle is not able to manipulate the image message sent from the server to the user. In other words, the user will see the transaction that is planned to be executed by the server and will only confirm such a transaction—a clandestine manipulation of the transaction by the trojan is impossible.
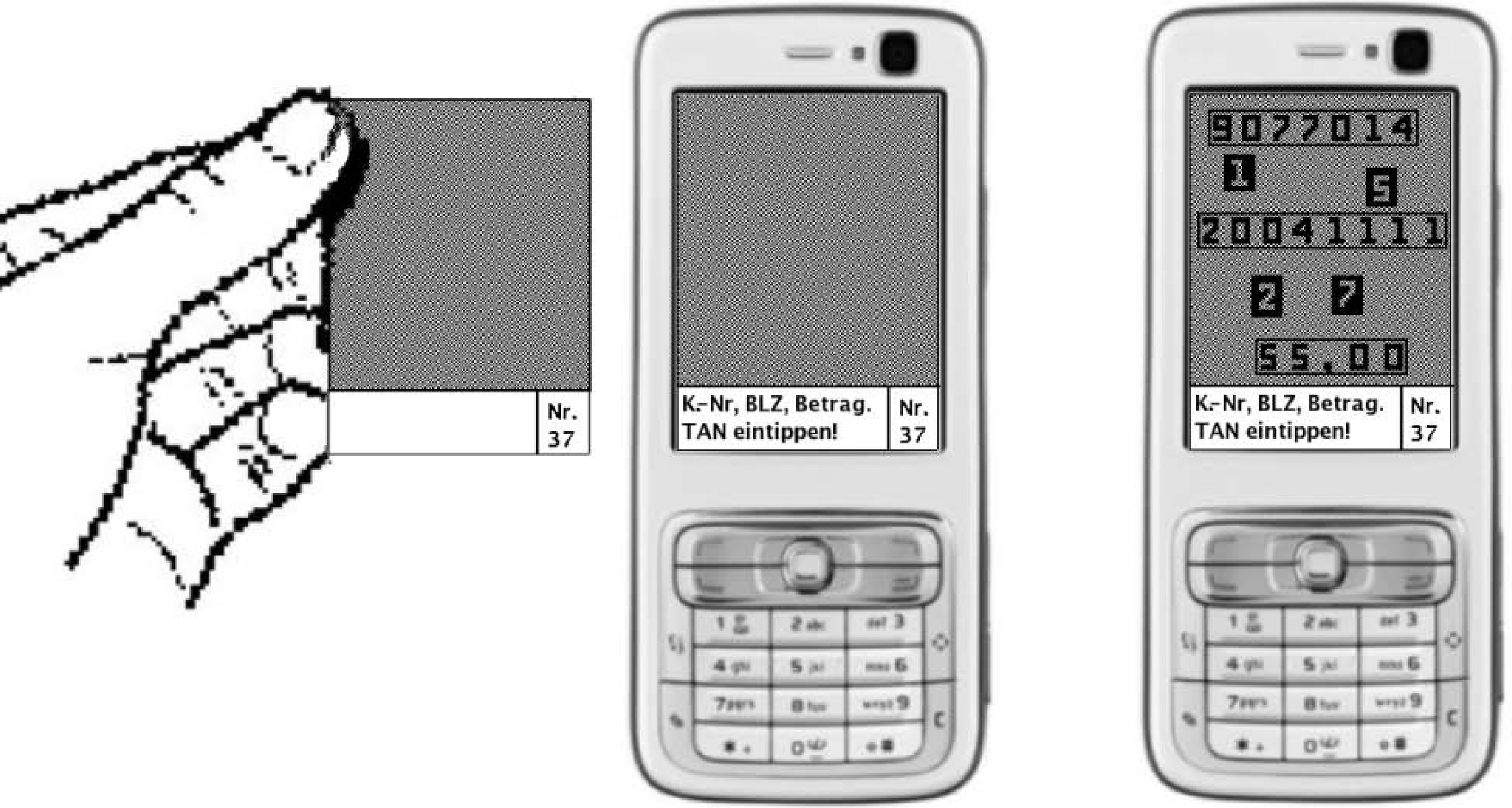
FIGURE 332.12
The main method is also applicable to mobile banking.
In the original purpose of secret sharing in [14], the order of the slides was not relevant. Later work [15] showed that a better contrast can be achieved with colors if the first slide can have non-transparent colors. Furthermore, practical applications will work in the way that the (first) slide is sent first from Alice to Bob over a secure channel (i.e., by surface mail) and used later as a key to decrypt an image received over an insecure channel.
We regard visual cryptography as a special case of the Cardano grille, which works on pixels instead of letters. In both cases we can describe the slide (grille) as a 2-dimensional array over {0,1}, where 0 stands for ”transparent” and 1 for ”black.” We describe the encrypted image as a 2-dimensional array over Σ = {0,1} or Σ = {0, 1, red, green, …} or Σ = {0, a,b, c, d, …}, where 0 stands for ”white” and 1 for ”black.” Colors are used for pixel-oriented applications and in case the areas are big enough, any alphabet of symbols can be used, which the receiver of the image can read through a transparent area.
A compromise between pixel- and symbol-orientation is the segment-based method described in [2], which works as demonstrated in Figure 12.5. It is applicable whenever the message consists of symbols that can be represented by a segment code, for example the 10 digits by the well-known 7-segment code. The encryption method is basically the same: Instead of pixels, longish and larger segments are encoded via two possible parallel positions.
Outline: Based on the above idea in [13], we describe techniques in Section 12.2 where the user can confirm a transaction as shown in Figure 12.1. Section 12.3 describes similar techniques that allow the user who received a slide from an account provider to securely enter a PIN or confirm transactions. The multiple use of a slide would be an economical and ecological asset and improve the convenience of the user who could, for example, leave the slide adjusted to the screen, but leads to security problems addressed in [13] and in Section 12.4. A further generalization concerning the slide leads to refractional (optical) cryptography, which is described in Section 12.5. Technical problems are discussed in Section 12.6. Section 12.7 describes Chaum’s application of visual cryptography in elections. It verifies that a ballot was counted without giving the voter the possibility to show others what she voted for.
12.2 Trojan-Secure Confirmation of Transactions
Naor and Pinkas state the application to online transactions implicitly in their conference paper [13]. Explicitly it is stated in Appendix A of their full paper, which can be found on their homepages. Klein, in 2005, describes this Naor/Pinkas ”transparency onto screen” idea as a main application of visual cryptography in [11]. Hogl independently re-invents visual cryptography and the Naor/Pinkas idea in the patent application [9]. Greveler refines some of the aspects of the Naor/Pinkas idea in [8]. Borchert and Reinhardt [3] discuss variants of the Naor/Pinkas idea.
We assume the computer can be infected with a trojan, which is able to eavesdrop and manipulate all input- and output information. Even after a secure login, a trojan (Malice) can manipulate a transaction, which is confirmed with the TAN or iTAN method in the following way as in Figure 12.2: Bob wants to instruct his banker Alice to transfer 50 dollars to X, but Malice chances this to ”transfer 5000 dollars to Y.” When Alice requests a confirmation by sending the message ”To transfer 5000 dollars to Y enter the TAN No. 37,” Malice changes it to ”To transfer 50 dollars to X enter the TAN No. 37,” and Bob will cluelessly enter the TAN No. 37.
To prevent this kind of attack, the authors proposed in [3] methods as in Figure 12.1 and Figure 12.4, with the idea that Eve is not able to produce a forged encrypted image of the original transaction. Here again, the image of message is shifted by a random offset in the x and y-direction to prevent Eve from concluding back to the slide.
However, the method in Figure 12.1 has the disadvantage that the user still needs TANs and that Eve might place the image of the original transaction in an unencrypted way on the screen, which will have the same appearance with the slide as if it would be the encrypted image of the original transaction. Thus, Bob might get fooled, if he did not check that there should be a ”gray” pattern without any information before he places the slide.
This can be improved using the method in Figure 12.4; it makes sure that the user is able to see the black balls, which is only possible if (at least most of) the encrypted image from Alice was sent unchanged to Bob. Since Malice does not know the position of the parts of the transactions on the picture, any attempt to alter a part of the transaction would most likely lead to an incorrect image, which can easily be detected by Bob. A similar version using the segment-based method in [2] is shown in Figure 12.6 and another similar version for mobile phones is shown in Figure 12.3. Two versions using Cardano Cryptography, where the user has to verify the transaction consiting of an account number by following the blue path, are shown in Figure 12.7 and implemented in [1]. In the 1-factor confirmation case, the user has to confirm entering the numbers along the red path; in the 2-factor confirmation case, the user has to confirm by typing his PIN on the keyboard below according to the permutation of the digits shown within the red-edged holes.
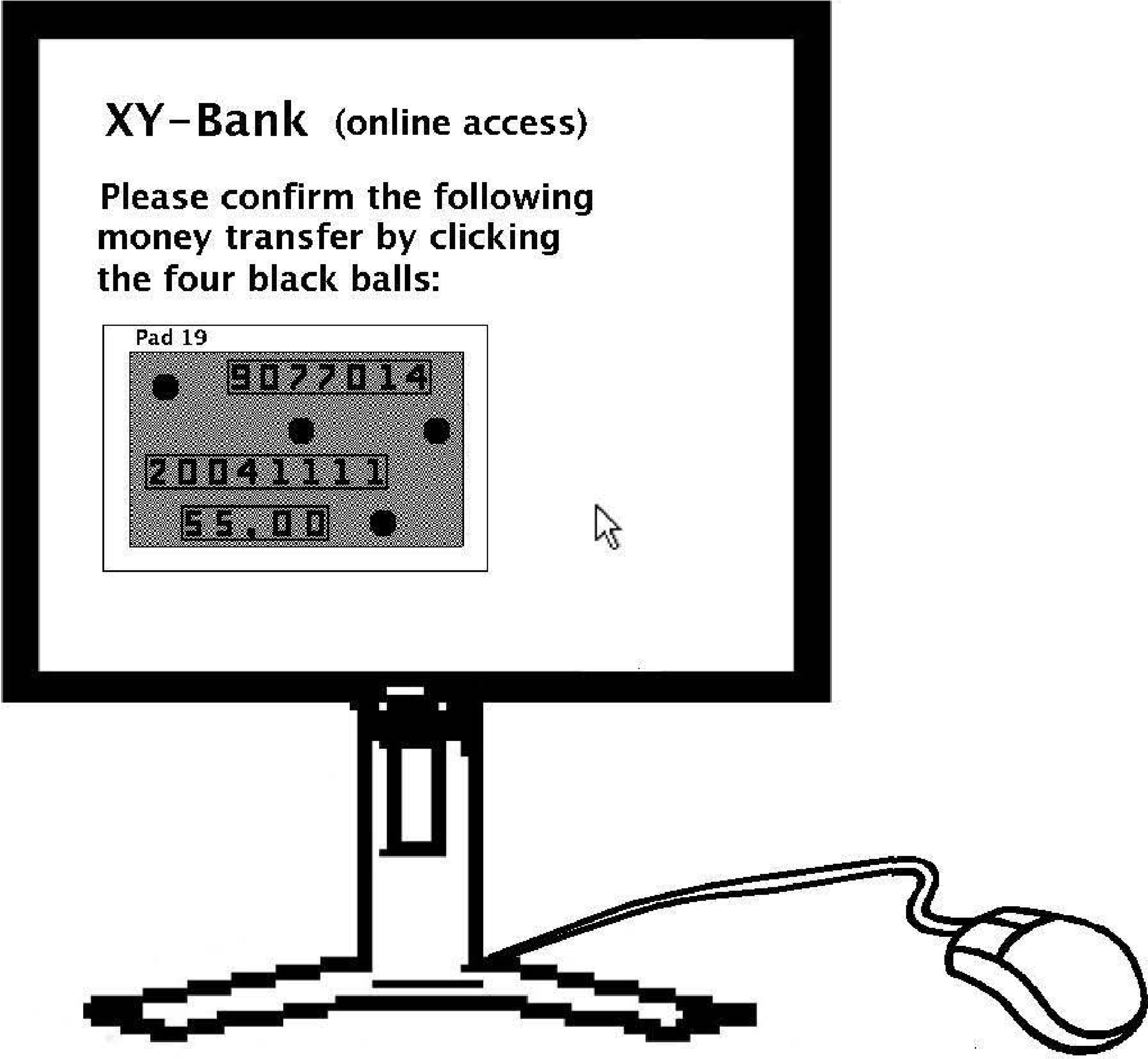
FIGURE 12.4
For confirmation, the user has to click the black balls placed between parts of the transaction data.
12.3 Trojan-Secure Authentication Using a PIN
The purpose of this section is to apply visual cryptography in a way such that the user can enter a password to the server in a way such that the trojan is not able to get the password.

FIGURE 335.12
Pixel-based (left) versus segment-based (right) visual cryptography.

FIGURE 336.12
The main method using segment-based visual cryptography in (a) and (b).

FIGURE 337.12
Cardano cryptography: above a 1-factor confirmation (user types 3752), below a 2-factor confirmation (for example, in case his PIN is 1234, the user types in 4136).

FIGURE 338.12
(a) To log in, the server sends an encrypted image of a permutated keyboard, which the user can only read after placing the slide over it. (b) The user enters the PIN by clicking at the positions according to their order in the PIN.
As shown in Figure 12.8, the trojan on the computer is not able to see the permutation chosen by Alice on the keys, which was randomly chosen by the server. Thus, the mouse-clicks of the user cannot be interpreted by the trojan. This method can be generalized to any alphabet and allows Bob to send short messages to Alice in a secure way.
Note here that this method becomes insecure if the message contains multiple occurrences of the same symbol, a PIN should thus be chosen without repetitions. In case Bob wants to send messages of length l that may contain repetitions, this could still be accomplished in a secure way by extending the alphabet to Σ ⋃ {r1, r2, …, rl–1}, where ri indicates the repetition of the symbol at position i. In this way, for example, the message ”messages” could be submitted as ”mesr3agr2r4” containing no repetitions in the extended alphabet.
In order to achieve 2-factor security for transactions, we combine the PIN method with the confirmation method of Section 12.2 as described in Figure 12.9.
Furthermore, to prevent the attack using the original transaction in an unencrypted way on the screen as in Section 12.2, we use the refined method of Figure 12.9.
12.4 Security versus Multiple Use
To achieve information theoretic security for a single use, we can divide the array into clusters of c pixels (resp. areas), where c is the size of the alphabet of the encrypted image. Only one pixel in each cluster has a 0 on the slide. To encrypt a pixel p ∈ Σ, place p at the position of the cluster with the 0 on the slide and fill the rest of the cluster with a random permutation of Σ {p}. Since each pixel-value in Σ occurs in each cluster of the encrypted image, each image is possible from the viewpoint of an a evesdropper.
In the model of a known plaintext attack, we assume that the a evesdropper Eve may receive the secret image later, then she can find out which position in each cluster has the o on the slide and thus the slide cannot be used securely a second time.
Known plaintext is relevant for authentication as considered in [13] as well as for confirmation as considered in Section 12.2; in both cases Bob has to be convinced that the message was sent by Alice. The problem of multiple usability is solved in [13] by dividing the slide in distinct areas, where each has to be big enough to contain the complete message; here we use an approach with a different distribution. To achieve information theoretic security use a slide n times, we propose the following two possibilities:
For one pixel use a cluster of nc pixels divided into n subclusters of c pixels in which each subcluster has a 0 on the slide. To encrypt the i-th image, we use only the i-th subcluster as above and fill the rest with 1. This leads to a contrast of .

FIGURE 340.12
For confirmation, the user has to click his PIN using a permutation of digits on the right side in (a) and (b).
FIGURE 341.12
For confirmation, the user has to click his PIN using inverted numbers.For one pixel use a cluster of cn pixels, which we address as an n-dimensional array (but arrange 2-dimensionally). Only one pixel in each cluster has a 0 on the slide. To encrypt a pixel p ∈ Σ in the i-th image, place p at each position of the cluster, which has the same i-th coordinate as the 0 on the slide then choose a random permutation of Σ {p} and fill the rest of the cluster in a way such that pixels with the same i-th coordinate get the same color. This leads to a contrast of .
In both cases each combination of images is consistent with any combination of encrypted images. In the first case, the contrast can be improved only to using refraction, whereas it can be improved to 1 using refraction in the second case.
In the case of an unknown plaintext attack, Eve is still able to obtain the secret images if the slide was used too often and if she can anticipate patterns in the picture. Let us consider the simple case Σ = {0,1}, c = 2 and the slide was used twice. Then Eve can XOR both encrypted images resulting in an image that is 0 at pixels where both original images coincide and 1 at pixels where both original images differ, thus she can see the difference of the original pictures as shown in [12] page 35 and Figure 12.11. Now assume the original images depict messages using a Font F consisting of f = |F| small symbols (symbol-pictures) having q pixels.

FIGURE 12.11
Superimposing two encrypted images for the same key-slide shows the difference of the original picture.
Assume furthermore the symbols are placed on fixed positions, then Eve can identify the pairs of symbols on corresponding positions as long as f 2/2 << 2q. Then Eve can use, for example, the redundancy of natural languages to decipher the text. One measure to complicate this attack is to shift the picture by a random number of pixels to the left or the right. Then Eve will have to try out the position of the first symbol and consider x · y · f 2/2 combinations, where x and y are the differences of the shifts but smaller than the width and the height of the symbols. Further complications can be caused by filling the space around the text by partially random patterns, which Bob can easily distinguish from the symbols, but Eve will have to start analyzing parts in the middle of the image. Here she can only assume that about a quarter of the surface of the letters overlap, which means this method of attacking can be expected to be successfull if x · y · f 2/2 << 2q/4.
Furthermore, the partially random patterns can compensate the statistical imbalance of the correlation of neighboring points. For example, Eve could look at pairs of pixels, where one is in some small distance above the other. If both are on a position having a 0 on the slide, then, given many encrypted images of texts, Eve could detect that they have the same color with a higher probability than other pairs. But the partially random patterns are made in a way such that this probability decreases in the overall image.
Let us now turn to the slides on the previous page: If the slide was used more than n times, then Eve can try the following attack: She chooses an area of q = x · y pixels somewhere in the image, then she tries each combination of positions of the 0 in each of the corresponding q clusters on the slide ((2n)q possibilities) and checks if it is consistent with each encrypted image in the sense that there are 4 symbols in F overlapping the area. This takes 4 · x · y · f steps. And thus 2n·q · 4 · x · y · f steps in total.
The number of possible subimages of a possible original image, where four symbols overlap, is approximately (x · y · f )4. This means each observed encrypted image can help Eve to exclude a sufficient number of possible choices if 2q >> (x · y · f )4. We therefore estimate the number of steps for Eve as >> (x · y · f)4·n · 4 · x · y · f = 4 · (x · y · f)4·n+1. Now assume we use x = y =10 and a huge font F with many possibilities to depict a symbol that leads to f = 1000 and roughly 1020·n steps for Eve. Considering many obvious and also less obvious improvements of the algorithm for Eve, we believe that the attack is still too expensive for Eve for n = 3.
12.5 Using Refraction
In [4] we generalize the slide from a 2-dimensional array over Σ = {0,1} to a 2-dimensional array over Σ ⊂ {1} ⋃ ℝ × ℝ with the idea that each pixel on the slide can either be black or contains a prism ( x, y) that refracts the light from a region on the encrypted image or, from the perspective of the user as shown in Figure 12.12, refracts the view to a region that is shifted by (x, y) from the pixel, which is directly behind the pixel on the slide. For example (0, 0) would correspond to the 0 in the case of usual Visual Cryptography just showing the pixel directly behind. One possible application would be to use clusters of 2 · 2 = 4 pixels for each pixel of the original and randomly choose one of the 4 pixels to be visible. For exampl 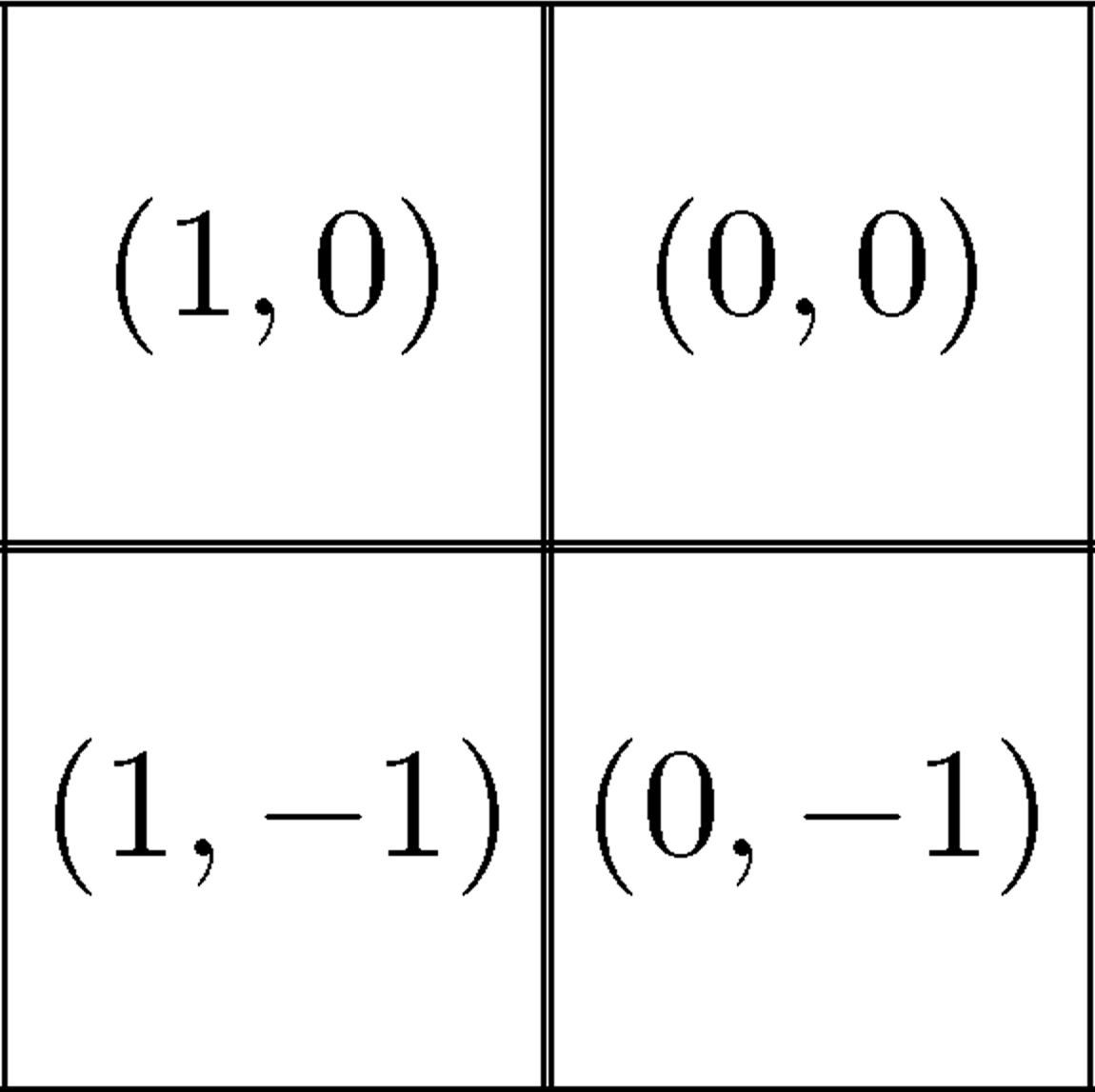 would direct the view to the upper right pixel on the encrypted image. This corresponds to construction 2 in Section 12.4. Using the slide two times is information theoretically secure and the contrast is 1.
would direct the view to the upper right pixel on the encrypted image. This corresponds to construction 2 in Section 12.4. Using the slide two times is information theoretically secure and the contrast is 1.
If we use lenses or fragments of lenses instead of prisms, the view can be focused on a point inside a pixel. This has the advantage that the positioning of the slide allows an error of up to half of a pixel. An example is shown in Figure 12.13. While producing fragments of lenses and prisms on the slide might require expensive special machines, it will be much cheaper to produce complete lenses. Since the lenses do not need to have a perfect shape, it would be sufficient to place drops of a transparent liquid that becomes hard on the side. This can be done by either using a modified ink-printer or by spraying the liquid using physical randomness (and Alice can scan it before sending it to Bob). The use of such a slide is shown in Figure 12.14. Figure 12.15 shows an optical generalization of Cardano cryptography. The advantage to Cardano cryptography is that the letters are magnified and can be read in a more natural ordering. The advantage to pixel-based visual cryptography is that much less precision is needed to position the slide. The disadvantage is that, in order to achieve a sufficient level of security, more than four choices (like in Figure 12.15) would be required. A repeated use would be too insecure as the slide contains only little information. Furthermore, a bigger distance of slide and screen is required.
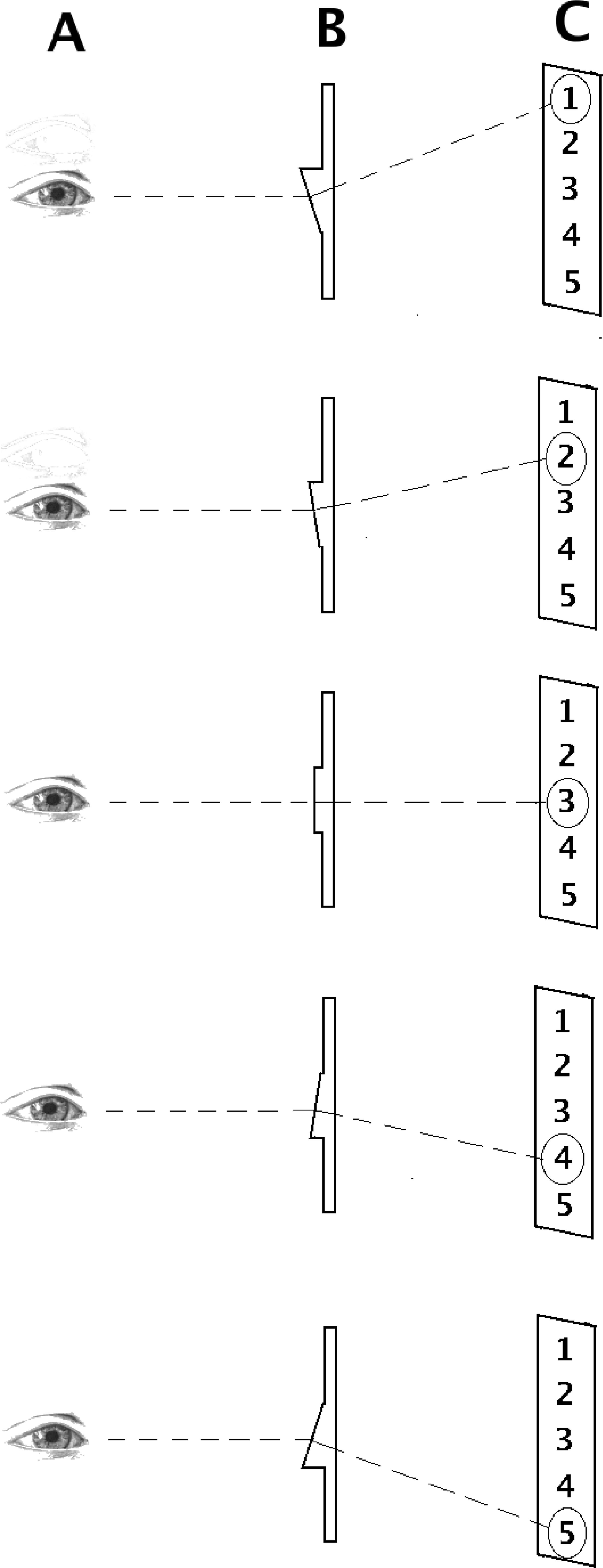
FIGURE 12.12
This example shows how the view from the observer (A) through prisms (B) is directed to areas 1,2,… or 5 on the encrypted image (C); the deviation depends on the slope of the prism.

FIGURE 345.12
Some parts of the encrypted image (C) is magnified for the observer (A), while other parts are hidden. For example, d and j are in the focus while b, c, e, f, h, i, k, and l are hidden.

FIGURE 12.14
Lenses are placed randomly on the slide (b). This can be done by spraying a transparent liquid that becomes hard on the side. The area in the focus of the lenses in the encrypted image (a) is colored in the color of the original image at this region. The rest of (a) is filled such that colors in (a) are equally distributed so that the original image can not be obtained from (a) alone but only together with the slide (b).

FIGURE 346.12
Each area of the slide (b) has fragments of lenses, which direct the view (c) in a magnifying manor to one of the symbols on the encrypted text (a).
12.6 Technical Problems Concerning Adjustment and Parallaxes
A disadvantage of pixel-based visual cryptography to Cardano cryptography is that the slide has to be placed at an exact position. We propose to position the slide at the (for example, left lower) corner of the screen making use of its frame. Then use the mouse to position and stretch the encrypted image on the screen accordingsly. The parallaxes is the shift of the pixel on the screen that can be seen through one point of the slide, which is caused by looking at it from a certain angle that differs from the right angle because of central projection and because the viewer has two eyes at different positions. This is estimated in [10] to be 0.25 mm in the case of a usual TFT screen, less for displays of new mobile phones, but might be more if we require a higher distance of slide and screen so that the use of refraction can take effect (depending on the size of the lenses). Slight misplacements of the slide cause effects like a bad contrast or even inverting the picture as described in [10] where the author also proposes methods to use interference effects at the frame of the slide as an aid for adjustment.

FIGURE 12.16
The voter enters the vote, verifies the image, and separates the slides.
12.7 Voting with a Receipt Based on Visual Cryptography
The purpose is to give a voter a receipt, which allows her or anyone else to verify that her vote was counted in the final result. The difficulty comes from the requirement that the voter should not be able to prove to anyone else, what her vote was since this would make abuses such as vote selling possible.
The main procedural method in [6] lets the voter enter her ballot on a touch screen and then the voting machine produces two slides laminated together that show the ballot image with visual cryptography to the voter only as shown in Figure 12.16. Then the voter separates the two slides and goes to the poll worker. Here one of the slides is destroyed and the other one is scanned and uploaded to the official election website. Furthermore, the voter keeps her slide as her receipt.
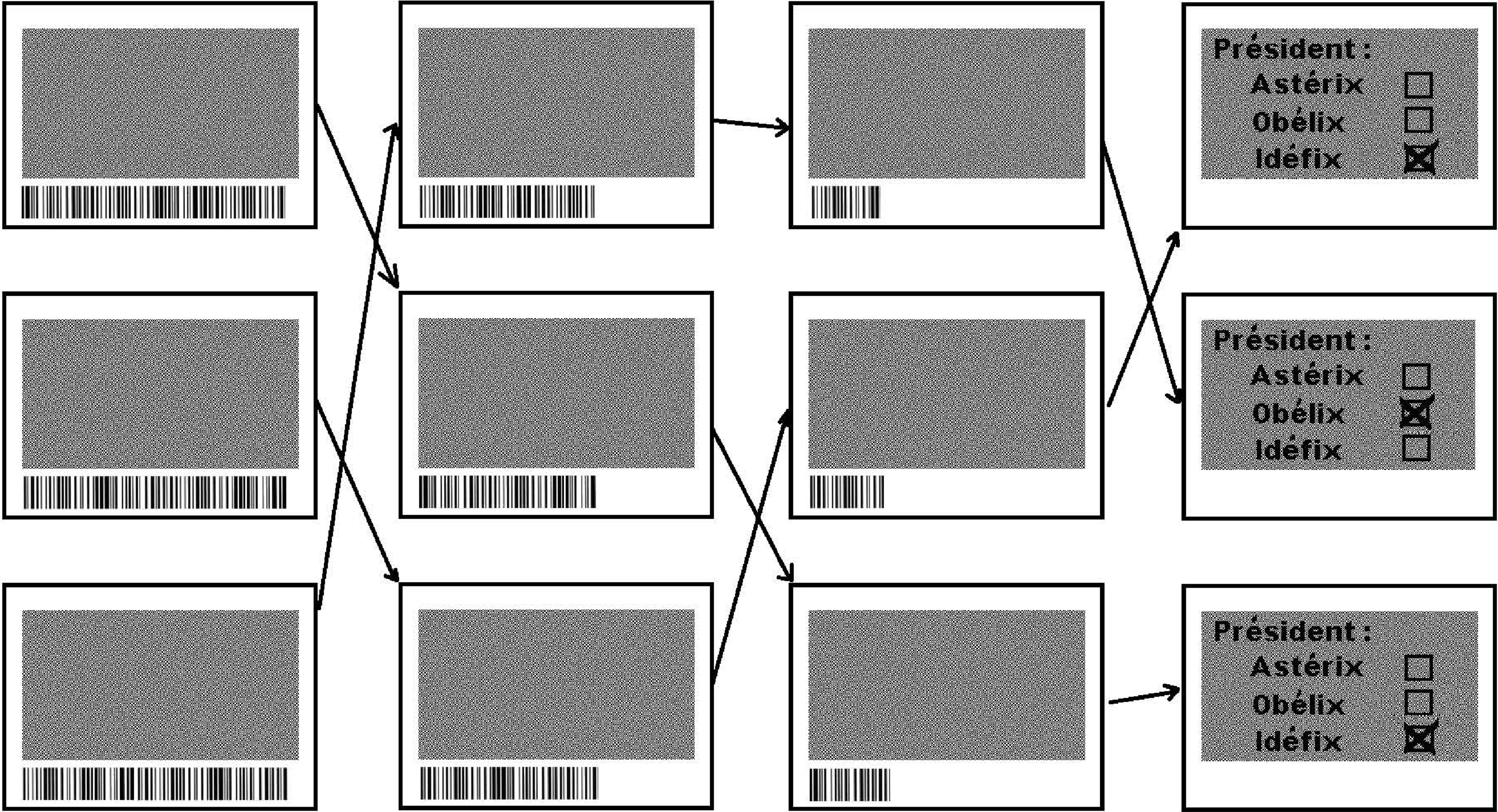
FIGURE 12.17
Each trustee strips one layer of the doll (represented by the barcode) and uses it to modify the image. The order is randomly permutated.
For confidentiality, the voter has to trust that the voting machine has no memory. But how can the results be computed only from the scanned slides? To make this possible, the slide cannot be completely random (as usual in visual cryptography) but is produced by a pseudorandom generator from the cryptographic version of a nested doll that contains the necessary information to reproduce the ballot image inside. This means that confidentiality is not information theoretically secure but only computationally secure under the usual cryptographic assumptions.
The cryptographic version of a nested doll is produced by the voting machine from the serial number of the ballot by successively encrypting with the public keys of a sequence of trustees and printed on the slide as a barcode. Only all trustees together would be able to compute the ballot image using their secret keys. The result of the election is computed by a sequence of mix-operations as described in [5]: The first trustee gets a batch of scanned slides as input. For each vote, he removes the first layer of the doll and modifies the encrypted image using the removed layer of the doll. Then he uploads a batch containing a random permutation of the results to the official election website. All other trustees do the same with the batch from their predecessor (see Figure 12.17). In the batch produced by the last trustee, the dolls were used up and the image became the original ballot image, which can be seen (and thus counted) by anyone.
To verify that the trustees worked properly, a public random choice is used to audit the trustees, which have to reveal half of the connections to the following batch by publishing the removed layer of the doll, which again allows anyone to verify these connections. But the choice was made in a way such that there will be no complete path visible leading from a scanned slide to its ballot image. In [7], a refinement of the choice is described, which ensures that nothing can be learned about the ballots of even groups of voters.
But how can the voter be sure that she was not cheated by the voting machine printing a false second (and later destroyed) slide letting her see her ballot image but producing a different one after passing all the mixes? The idea is that after the voting machine printed the visual cryptography part on the laminated slides, the voter has still the choice to take the upper or lower slide as receipt and tell the choice to the voting machine before it continues by printing the barcode of the doll to it; in this way the voting machine would for each voter only have a 50% chance of cheating without being caught.
12.8 Conclusion
Visual cryptography is a fascinating technique and very intuitive to the user. However, it is surprising that within the last 15 years since its invention by Naor and Shamir only a few suggestions have been made to apply it to practical problems. In this paper we presented Naor and Pinkas technique to use visual cryptography in order to protect online transactions against manipulation and Chaum’s idea to apply it to verify the correctness of the outcome of an election. Because of difficulties like adjustment, multiple use, and costs of special equipment, these suggestions did not lead to applications that are used for serious purposes. But in the future, further developments of the ideas presented in this paper, as well as new ideas, could spread practical applications of visual cryptography.
Bibliography
[1] Sebastian Beschke. Implementierung der Cardano-TAN (cTAN), 2009. Studienarbeit.
[2] B. Borchert. Segment-based visual cryptography. Technical Report WSI–2007–04, Universität Tübingen (Germany), Wilhelm-Schickard-Institut für Informatik, 2007.
[3] B. Borchert and K. Reinhardt. Abhör- und manipulationssichere Verschlüsselung für Online Accounts mittels Visueller Krytographie an der Bildschirmoberfläche, 2007. Patent application DE-10-2007-018802.3 (approved 2008).
[4] B. Borchert and K. Reinhardt. Lichtbrechungs-Kryptographie, 2010. Patent application DE-10-2010-031 960.0.
[5] David Chaum. Untraceable electronic mail, return addresses, and digital pseudonyms. Commun. ACM, 24((2):84–88, 1981.
[6] David Chaum. Secret-ballot receipts: True voter-verifiable elections. IEEE Security & Privacy, 2((1):38–47, 2004.
[7] Marcin Gomulkiewicz, Marek Klonowski, and Miroslaw Kutylowski. Rapid mixing and security of chaum’s visual electronic voting. In Einar Snekkenes and Dieter Gollmann, editors, ESORICS, volume 2808 of Lecture Notes in Computer Science, pages 132–145. Springer, 2003.
[8] Ulrich Greveler. VTANs Eine Anwendung visueller Kryptographie in der Online-sicherheit. In 2. Workshop “Kryptologie in Theorie und Praxis,” Bremen, Lecture Notes in Informatics (LNT), pages 210–214, 2007.
[9] Christian Hogl. Verfahren und System zum bertragen von Daten, 2005. Patent application DE-10-2010-031 960.0.
[10] Frank Hunszinger. Implementierung und Untersuchung eines Verfahrens zur visuellen Kryptographie, 2010. Diplomathesis.
[11] Andreas Klein. Eine Einführung in die visuelle Kryptographie. In DMV Mitteilungen 1/2005, 2005, 54–57.
[12] Andreas Klein. Visuelle Kryptographie. Springer, Berlin Heidelberg New York, 2007.
[13] Moni Naor and Benny Pinkas. Visual authentication and identification. In Lecture Notes in Computer Science, pages 322–336. Springer-Verlag, 1997.
[14] Moni Naor and Adi Shamir. Visual cryptography. In EUROCRYPT, pages 1–12, 1994.
[15] Moni Naor and Adi Shamir. Visual cryptography ii: Improving the contrast via the cover base. In Proceedings of the International Workshop on Security Protocols, pages 197–202, London, UK, 1997. Springer-Verlag.