
Before we move to have a look at the main SolrCloud feature, I feel some more consideration of denormalization and the advantages of this approach will be useful when using Solr and similar tools. As we already pointed out, with distributed search we can obtain results even from a different shard. We could have, if needed, represented the data of different entities posted to different cores with compatible schema, and still the system should work. From this perspective, there seems to be no point in indexing data on different cores using an entity-relationship normalization approach. I tried to synthesize this simple idea in the following schema:
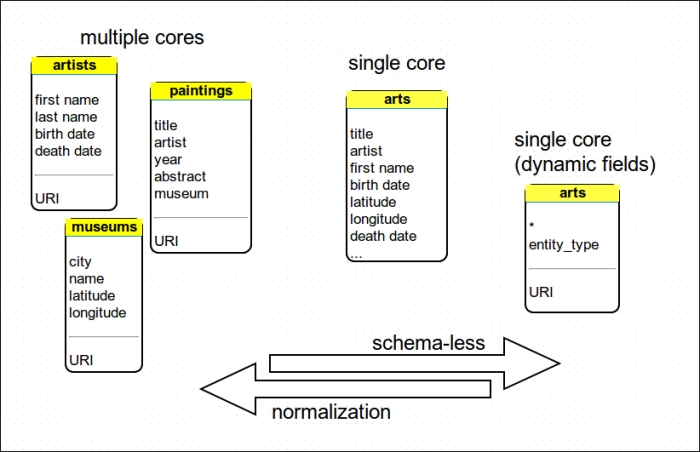
In the left part of this schema, we can find some suggested relationships between the different entities that could be used for joins if we were using a relational database. Note that Solr doesn't have a join functionality in the relational perspective as we have seen before, and it permits us to link together records representing different entity individuals by matching them on some criteria at runtime.
Looking at this schema I simply want you to remember again that Solr isn't a relational database, and even if we have some previous experience with those and it could be helpful to look at some analogies, we need to start thinking differently.
Although we are introducing some features from SolrCloud we are moving to adopt Solr not only as a search engine (and match engine, let's say), but as an effective NoSQL solution, and we should not be tempted to think too much in a relational way. I hope you will remember this simple fact. You can think about our schema in case of multiple entities as if we are creating a very long, huge vector with optional fields for every field of every entity. We will put only the values we have from time to time without harming the inverted index (there will be no "holes"). Thus we will ideally have no memory loss and duplications of fields to avoid by normalizing using a more rigid pre-defined schema.
In this chapter I am intentionally not describing the configuration we are adopting, since it's basically the same as in the previous chapters, and it's not so important for us to test.
You probably have not missed the adoption of an entity_field in the single core represented when reading our schema from left to right. This is the typical scenario in every model that adopts normalization. At the same point you will need a field or a property to keep track of the entity the data is referred to. We had given a specific value to this field with the XSLT used to produce our Solr documents. I suggest you to always adopt such a field when using different data representing different entities in your single core definition. You will be able to track that data from the beginning, or optimize your querying filtering them by type with fq parameters (remember that this can be appended on every request, if configured in solrconfig.xml), even if at some point you change some schema configuration.
Moreover, you can easily use faceting on this field to have a fast overview of the different data inserted, and even try to represent some hierarchy, but this is up to you.
In order to post the data on the single core definition, we will use the script (/SolrStarterBook/test/chp07/postAll.sh):
>> java -Dcommit=yes -Durl=http://localhost:8983/solr/arts/update -jar post.jar ../../../resources/dbpedia_paintings/solr_docs/*.xml
I strongly suggest adopting this approach in the first stage of a project, in order to proceed with rapid prototyping and to be able to produce something testable in a couple of hours of work. But when you have this single melting-pot index running, you could start seeing it from different perspectives that will be specific to your project, from better shaping your domain, to starting to consider what kind of architecture should be used to expose the services.
Even if we are often using a schemaless approach for our prototypes, we still need to analyze our domain deeply, which is important to fully understand what kind of searches we need and how we can configure a correct text analysis for every field.
I suggest you to refer to: http://www.infoq.com/resource/minibooks/domain-driven-design-quickly/en/pdf/DomainDrivenDesignQuicklyOnline.pdf. This book can give you some insights into how to manage the domain analysis as a central part of our design.
If we have a unique big index containing data from different entities we could perform advanced analysis on it, which can give us a very interesting perspective of our data based on advanced metrics of similarity.
Once we have a single arts core running (you can find the details of the configuration in /SolrStarterBook/solr-app/chp07/arts), we can then define an arts_clustering twin core, which can be used with the same data and configuration, but exposing them to document clustering analysis. Solr 4 includes integration with the very good tool Carrot2, which you can download following the instructions on the site http://download.carrot2.org/head/manual/index.html.
Once you unzip the Carrot2 Web App, add the configurations for our examples; for your convenience I have placed in the path /SolrStartedBook/carrot.
Note
Carrot2 is an Open Source Search Results Clustering Engine, which can automatically organize collections of documents into thematic categories.
You can find all the references and the manual of the project on the official site:
It can fetch data from various sources, including wikipedia, results from search engines, and Solr itself. It can also be used with other data collections, adopting its XML format; so I suggest you to take a look at its API.
Note that we are interested in exposing data from Solr to Carrot2, but it's also possible to use Solr for indexing on the Carrot2 data itself, so the process can be customized in different ways, depending on your needs.
Once you have Carrot2 running, it's simple to define what we need to expose for Solr to talk to carrot:
<searchComponent name="clustering" enable="true" class="solr.clustering.ClusteringComponent"> <lst name="engine"> <str name="name">default</str> <str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str> <str name="LingoClusteringAlgorithm.desiredClusterCountBase">4</str> <str name="MultilingualClustering.defaultLanguage">ENGLISH</str> </lst> <lst name="engine"> <str name="name">stc</str> <str name="carrot.algorithm">org.carrot2.clustering.stc.STCClusteringAlgorithm</str> </lst> </searchComponent> <requestHandler name="/clustering" class="solr.SearchHandler"> <lst name="defaults"> <bool name="clustering">on</bool> <bool name="clustering.results">true</bool> <str name="clustering.engine">default</str> <!-- Solr-to-Carrot2 field mapping. --> <str name="carrot.url">uri</str> <str name="carrot.title">uri</str> <str name="carrot.snippet">fullText</str> </lst> <arr name="last-components"> <str>clustering</str> </arr> </requestHandler>
As you can see this is as simple as defining a new request and search handler couple of components, and put some (initial!) configuration for choosing algorithms and fields to be used from Carrot2.
The next step will be configuring Carrot2 to acquire data from Solr. We need to edit the source-solr-attributes.xml file at /SolrStarterBook/carrot/webapp/WEB-INF/suites/:
<attribute-sets default="overridden-attributes">
<attribute-set id="overridden-attributes">
<value-set>
<label>overridden-attributes</label>
<attribute key="SolrDocumentSource.serviceUrlBase">
<value value="http://localhost:8983/solr/arts_clustering/clustering"/>
</attribute>
<attribute key="SolrDocumentSource.solrSummaryFieldName">
<value value="fullText"/>
</attribute>
<attribute key="SolrDocumentSource.solrTitleFieldName">
<value value="uri"/>
</attribute>
<attribute key="SolrDocumentSource.solrUrlFieldName">
<value value="uri"/>
</attribute>
</value-set>
</attribute-set>
</attribute-sets>Finally we need to add our new Solr source in the suite-webapp.xml file at /SolrStarterBook/carrot/webapp/WEB-INF/suites/ (we can add as many instances as we want):
<source component-class="org.carrot2.source.solr.SolrDocumentSource" id="solr" attribute-sets-resource="source-solr-attributes.xml">
<label>arts (Solr)</label>
<title>Solr Search Engine</title>
<icon-path>icons/solr.png</icon-path>
<mnemonic>s</mnemonic>
<description>our Solr instance.</description>
</source>When we have both arts_clustering and Carrot running, we will have the chance to use the carrot algorithms and visualizations. For example, by adopting Lingo, we could obtain some very suggestive visual synthesis for our analysis, which can really help us in refactoring the domain configuration, or in presenting the actual context in which our data exists to the clients. The documents in a cluster are considered to be similar by an emergent theme or topic, connected to the same concepts, it does not matter if they are actually representing an artist or paintings. Imagine the possibility of reviewing your domain with your clients, planning refactorization of facets, or configuring a topic-specific text analysis.
In the following screenshot we can see different kinds of visual representations of document clustering, for example, searching for oil painting:
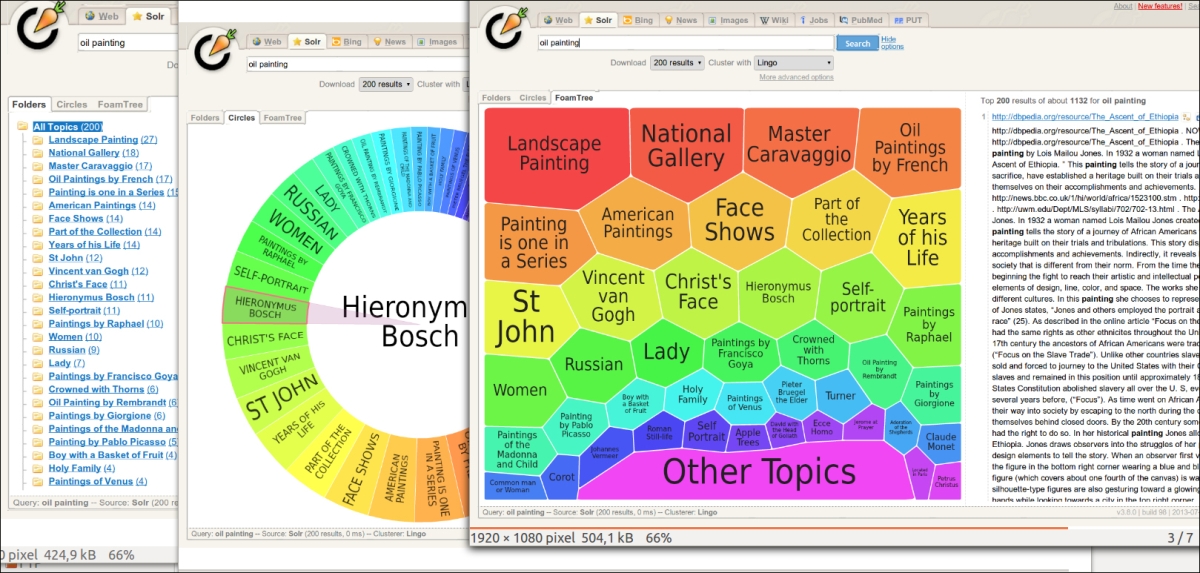
As you can see these kinds of tools can be very useful and can help us to avoid losing time, so I hope you will spend some time going in this direction for your experiments, when you have some more experience in using Solr by itself. The presentation at http://2011.berlinbuzzwords.de/sites/2011.berlinbuzzwords.de/files/solr-clustering-visualization.pdf will give you a clearer idea.
Looking from left to right you will probably think about faceting, but remember that in this case the aggregation is done by similarity and adopting specific algorithms for clustering such as Lingo or Suffix Tree, not by simple direct terms matching. This way it's possible to see emerging latent themes, which we can't imagine by simply searching for the same textual content over the data.
On a more technical side, we need to be able to scale up our indexes when needed (especially if we chose to use a single schema), and we will see that this can be done by using replications by hand, or as a feature of SolrCloud. A replicated index is generally adopted when high traffic on our site will require the capability to serve more contemporary clients. In this case we can define a master core and a slave core. The master will contain the original version of the index, and the slave will be synchronized on its changes, so that we can produce lots of replicas to serve a huge query traffic. The indexing process should have a noncritical impact on the searching experience, at the cost of some overhead in network activities, which can become intensive.
A typical scenario will require the detailed configurations and tuning, but the main elements will be the definitions of two specific request handlers to let the different Solr cores communicate with each other.
A master core will typically require a definition similar to this:
<requestHandler name="/replication" class="solr.ReplicationHandler" > <lst name="master"> <str name="replicateAfter">commit</str> <str name="confFiles">schema.xml,mapping-ISOLatin1Accent.txt,protwords.txt,stopwords.txt,synonyms.txt,elevate.xml</str> </lst> </requestHandler>
However, a slave core will have to specify the name of the master core to which it is connecting:
<requestHandler name="/replication" class="solr.ReplicationHandler" > <lst name="slave"> <str name="masterUrl">http://${MASTER_CORE_URL}/${solr.core.name}</str> <str name="pollInterval">${POLL_TIME}</str> </lst> </requestHandler>
You will find more detailed instructions on how to define and use replicas on the official wiki page:
http://wiki.apache.org/solr/SolrReplication
Note that this peculiar communication system is hierarchical and exposes a single point of failure in the master. If this goes offline the system might suffer from problems. It is a more resilient and self-reconfiguring approach. It is used for SolrCloud, by combining and managing the sharding and replication capability via the Zookeper server.
Since Solr 4, every Solr instance is also a SolrCloud instance. All the capabilities we need to use are already included, and it's up to us whether to start Solr with Zookeper (and the basic configurations for it) or not. In fact when started with Zookeper, Solr will act as a SolrCloud instance, so that it can create, destroy, split, or replicate shards in a way transparent to us.
Starting from a single index on a single core, we saw that we can split a single logical index into multiple indexes by using multiple cores. If we see this as a vertical-logical subdivision, as we described earlier talking about denormalization, we can also adopt a horizontal subdivision for a logical index, introducing the concept of shards.
But we saw that sharding must be done manually, and this usually means using some specific programming in SolrJ or similar libraries. Queries are sent to multiple shards and then the results are assembled, so this is useful when we have to handle very big indexes. Let's say there is a distributed search but no distributed indexing; this has to be managed by our custom programs that need to know the specific schema.
Replication is good for managing distributed indexing and scales well on increasing traffic requests, but it has to be manually configured and managed, too. Moreover, it introduces some network traffic overhead and delays for synchronization, and it's not so simple to recover after some bad failure.
With SolrCloud we are adopting both sharding and replication, but hiding the complexity so that we can to manage a single logical index that can be composed by multiple cores on different machines. A collection is in short a single logical index, which can be composed by many cores on many nodes, obtaining redundancy and a scalable and resilient index. We can of course think about adopting multiple collections that can be managed independently from each other.
Internally, every collection will be divided into logical parts called slices. Every slice will have several materialization of its own data (physical copies), which is what we usually call a shard. Finally, there always is a leader shard, from which updates are distributed, and in the same way there will always be some node that acts as a master for others. The concept of nodes here is important because they tell us that this environment does not have a single point of failure, and every node or shard could be promoted when needed if any one node fails, this is why we can define it as a resilient network. This way recovery and backup could be done automatically using the shards/replica functions.
The main orchestrators in this network are the Zookeeper companion instances for the active Solr, and they need to be studied specifically to understand their technical configuration details and behavior.
Zookeeper is a standalone server that is able to maintain configuration information and synchronization between distributed services, by using a shared hierarchical name space of data registers. You can think about these kind of namespaces as analogous to how a filesystem normally manages files. The main difference is that here the namespace is designed to manage shared distributed service endpoints, and let them communicate with each other, possibly sharing their data.
This kind of coordination service can improve availability of the endpoints they manage (they can track problems and eventually perform updates and request balancing), and a series of Zookeper instances that communicate with each other will effectively design a fault tolerant environment. Internally, some nodes are used as overseers for others and, when launching multiple Zookeeper instances, an ensemble of instances is considered to be running if more than half of the server instances are up (this is what is called a quorum).
ZooKeeper actually serves as a repository for cluster states.