
Before talking about the implications of using shards, let's test this approach with two very simple example queries as follows:
- First of all, let's try to simulate a distributed search over a single Solr instance, using the same Solr core twice (if you would like to give a name to the idea, we can name this an
identity shard); in this case, we are executing the query on thearts_paintingscore, and expanding the query with a distributed search over two simulated shards, which actually refers to the same core:>> curl -X GET 'http://localhost:8983/solr/arts_paintings/select?shards=localhost:8983/solr/arts_paintings,localhost:8983/solr/arts_paintings&q=*:*&wt=json&debugQuery=on&fl=[shard],*' - Once this is proven to be working, we will move a step forward from the previous multicore join examples. We will simulate a distributed search over our cores as they were our shards. This time we are introducing other cores as shards, and we are using the pseudo-field
[shard]to explicitly mark a document with its shard membership, as we can see in the screenshot following the command:>> curl -X GET 'http://localhost:8983/solr/arts_paintings/select?shards=localhost:8983/solr/arts_paintings,localhost:8983/solr/arts_museums,localhost:8983/solr/arts_subjects,localhost:8983/solr/arts_artists&q=fullText:1630&start=0&rows=20000&debug=on&wt=json&fl=uri,entity_type,[shard]&debugQuery=on'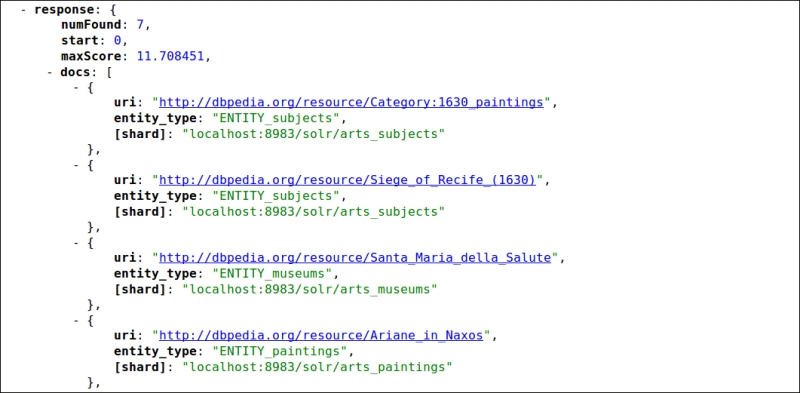
- In the previous screenshot you can see some of the results of the query, with details on the shard where a document is actually found (remember that in our case we have four distinct indexes, so it's easy to verify whether a document is present on a specific core or not).
Note
Note that here we are still executing a single query over a single machine, with a single running Solr instance, even if we are using multiple different cores as shards. This is not what shards are designed for; however, they should be used to distribute a single query over a single, huge index that can be hosted using several machines. You should have noticed that once we have adopted a compatible or identical schema definition, this can turnout to be only a conceptual distinction.
In the previous two examples, we are using parameters, such as shards=host1/core1,host2/core2 to provide the list of shards where the query will be sent. The [shard] pseudo-field is used to mark a document with the explicit information about the shard that actually contains it. Here we need to specify a running Solr instance and a specific core name. There is no limit on using exactly the same schema definition or a slightly different one, as long as the schemas are compatible with each other. Two schemas can be compatible if they declare the same fields of the same data types, or if they only use the same kind of dynamic fields and the same unique key, just to cite two examples. There can be other specific cases, but the point is quite intuitive. Imagine using two shards that contain a year field, but one configured with a numeric type, and the other as a string type. When trying to retrieve values Solr should get an error. A less problematic case is when you will use fields that exist only on one of the two shards, as they will simply produce no match for some of the Solr instances. Moreover, be warned that if you really use different compatible schema definitions, you could even incur problems with different language analysis configuration, so I feel there is no point in using this approach.
Generally speaking, in our example, the query is being served by two Solr shards, which are essentially the same. This is a good start to considering using multiple shards, which have the same schema. When a document is present only on one shard, it can be replicated if needed (using a specific handler to enable one shard to communicate with the others), but it is generally not duplicated in the results.
This should give you the idea that shards are really designed to be used for splitting a large, huge index into more compact and distinct ones, and then being able to query them as if they were a single (logical) one. The maintenance of data on separate shards is up to us, and this has been proven by construction in this case, as we are in fact using exactly the same schema for the four cores, but we have posted the data on that individually, by type.
If you also want some deeper view of how this is working, we have adopted the parameters fl=[shard] to project the information of which shard actually contains a record, and of course debugQuery=on. This way we will see how the query is actually split and suprise! the query is not split at all by itself, but will produce 4 different matching results that will be collected.