
A very simple way to start playing directly with terms is to configure a small auto-suggester (the third now), this time directly based on term enumeration and somewhat similar to the facet-based suggester seen at the beginning of this chapter.
- For simplicity, we will define a new core named
paintings_terms. We need not post new data here, so we will point it to the index at/SolrStarterBook/solr-app/chp06/paintings/data. We will copy the sameschema.xmlconfiguration, but we need to modify oursolrconfig.xmlfile a little in order to enable a search handler specific for handling terms, as shown in the following code:<searchComponent name="terms" class="solr.TermsComponent" /> <requestHandler name="/terms" class="solr.SearchHandler" startup="lazy"> <lst name="defaults"> <bool name="terms">true</bool> <bool name="distrib">false</bool> </lst> <arr name="components"> <str>terms</str> </arr> </requestHandler> - With this simple configuration, we are enabling the terms component and linking it to a new search component. Once we have restarted the core, we will be able to make queries.
- For example, we want to make a request similar to the auto-suggester with the facets seen at the beginning of this chapter. It is useful when playing with a suggest-as-you-type approach. Suppose we have typed the term
hen; the command will be as follows:>> curl -X GET 'http://localhost:8983/solr/paintings_terms/terms?terms.fl=artist_entity&terms.prefix=hen'
- Another way to obtain a similar result is using a regular-expression-based approach, as shown in the following command:
>> curl -X GET 'http://localhost:8983/solr/paintings_terms/terms?terms.fl=artist_entity&terms.regex=pa.*&terms.regex.flag=case_insensitive&wt=json&json.nl=map&omitHeader=true'In both the cases, we are asking for results using the
artist_entityfield for simplicity.
The TermsComponent is a search component, which iterates over the full terms dictionary and returns the frequencies of every term in the documents' collection for the entire index without being influenced by the current or filter query.
In short, this functionally is very similar to what we already saw using faceting for autosuggestion as this component is actually faceting over the entire terms' collection for the current index, but there are a couple of differences. This is very fast (it uses low-level Lucene functions) and provides term-level suggestions that are independent from the current search and restrictions. However, there is a drawback: Documents that have been marked for deletion but have not been deleted yet are also returned.
The first example needs no further explanation as it is based on the use of a prefix in the same way as with facets.
In the second example, we are looking for results that start with pa using regex (regular expression). We have also decided to ignore case with regex, and can omit the header to simplify the way to consume results from the HTML frontend.
Tip
If you want to study more about regular expression, start with a simple tutorial, which can be found at
http://net.tutsplus.com/tutorials/javascript-ajax/you-dont-know-anything-about-regular-expressions/.
Then move on to something more specific to Java (remember, Solr is written in Java), such as the following link:
http://www.vogella.com/articles/JavaRegularExpressions/article.html
For the second example, we will obtain the following result:
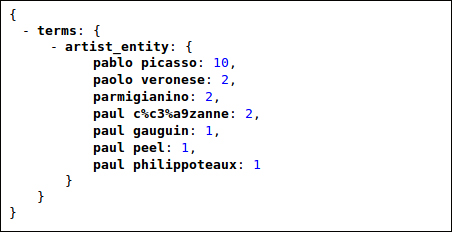
Note that the presence of an escaping HTTP entity is not an error here. It is needed to correctly handle special characters. In most cases, you have to manage these characters by decoding them during the construction of the HTML counterpart.
Tip
When using terms, there are a lot of options that can be used. For example, terms.mincount and terms.sort act the same as the analogous options seen before for facets. On the other hand, terms.raw designates a specific behavior on terms, and will give us the chance to see the actual format of the data (that could mean very low readability, in particular, for dates and numbers). For more understanding, we can refer to the official wiki page:
Using regular expressions, we can also achieve matching in the middle of the keyword. By searching the artist_entity field, which is keyword-based, we want to obtain results that contain the substring mar:
>> curl -X GET 'http://localhost:8983/solr/paintings_terms/terms?terms.fl=artist_entity&terms.regex=.*mar.*&terms.regex.flag=case_insensitive&wt=json&json.nl=map&omitHeader=true'
The following code will not necessarily be at the beginning:
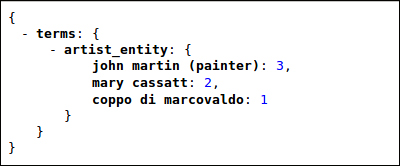
Here, we have used terms.regex=.*mar.*, which roughly remembers the usage of the LIKE syntax in SQL. (Let's imagine writing something similar to LIKE '%mar%'.) Note that the regex expressions in Solr are based on Java with some minor changes. If you want to check them in detail, I suggest you look directly at the JavaDocs pages, for example, http://lucene.apache.org/core/4_4_0/queryparser/org/apache/lucene/queryparser/classic/package-summary.html#Regexp_Searches. This, however, is not needed for handling facets.
When adopting Solr, you probably want to introduce an advanced full-text search and a faceted navigation support on your site or application. In many cases, you don't want to go any further on deeper theoretical study and only want to learn how to manage an efficient tool. On the other hand, Solr is built on top of Lucene, that uses a term's or document's multidimensional sparse matrix for its internal representation. It is important to remember that we are actually handling vectors of terms as these are the internal data structures that give us the fast and flexible lookup capabilities we are starting to manage. Please do not get scared of some reading involving a bit of math theory, which will be proposed for taking you to the next step in your journey on Solr, when you have played enough with the basic functions.
When playing with the examples and developing your own, I hope you are more and more cognizant of the fact that our attention should shift from the need for a search engine to the actual management of a match engine. The text queries give us results based on internal metrics, so that the calculation of a match score is crucial. This approach is based on the widely adopted "bag of words" hypothesis, which suggests to approximate the relevance of the document to a query by calculating the frequencies of words for the documents in the collection. In other words, if we see queries as pseudo-documents, and if they have similar vectors for a specific term, we will assume that they tend to have similar meaning.
This is a strong hypothesis, and yet is functioning in most cases, introducing us to the concept of similarity of vectors. Use a mathematical function to find out what vectors (and then what terms, since every term has its own vector) are mostly related to each other. This kind of term-vector-based matching is used in Lucene for highlighting, implementation of partial updates, and suggesting other terms in a "more like this" fashion, as we will see in while at the end of this chapter.
Moreover, the concepts behind similarity involve some studies about vector space models (http://en.wikipedia.org/wiki/Vector_space_model) and move us to think about semantics. This is far beyond the scope of this book, and involves advanced concepts, but if you are interested in reading something about this, I suggest you read From Frequency to Meaning: Vector Space Models of Semantics, by Turney and Pantel (http://www.jair.org/media/2934/live-2934-4846-jair.pdf), where the authors talk about the different kinds of semantic similarities.
The point here being when we approach similarity between entire documents or a group of fields, it may be possible to define other kinds of document similarities when exploring the context in which the terms live. This can be done using latent (implicit) relations or explicit dictionaries, frames, and models. In this direction, there are a growing number of libraries that can be integrated with Solr for machine learning or clusterization (for example, Carrot2, Mahout, Weka, and so on) and for the integration of natural language processing features on the Solr workflow (for example, UIMA or OpenNLP).
The Solr workflow permits us to write custom wrapper components at every stage for integrating external libraries, even when they need to use precomputed models, for example, using the Stanford NER component, which we will see in action in Chapter 9, Introducing Customizations.
Moreover, in Chapter 8, Indexing External Data Sources, we will look at the Data Import Handler library, which will be probably refactorized in the near future using a document processing pipeline framework. This will be another good start for the introduction of external component's integration.
An important progress with Solr 4 is the possibility to choose among different similarity implementations. For every implementation, a factory is provided and all the concrete classes will inherit the default similarity Java class:
The default implementation, based on the vector space model, is the TFIDFSimilarity one:
http://lucene.apache.org/core/4_3_1/core/org/apache/lucene/search/similarities/TFIDFSimilarity.html
From this point, it's possible to implement custom similarities with a class (and its own factory) in the same way as with all the provided classes, which are still experimental, for most, at the time of writing: BM25Similarity, MultiSimilarity, PerFieldSimilarityWrapper, SimilarityBase, and TFIDFSimilarity.
Just to give you an idea, we could choose a different similarity implementation; for example, our hypothetical custom one by putting:
<similarity class="some.package.MySimilarityFactory"> <str name="parameter1_name">a-string-value</str> <float name="parameter2_name">a-numeric-value</float> ... </similarity>
An interesting fact is that from Solr 4.0, there are also similarity factories that support specifying specific implementations on individual field types.
We could, for example, have adopted cosine similarity, which is very widely used. It is a measure of the angle between two term vectors, the smaller the angle, the more similar the two terms. This is simple to calculate, and will work very well in most cases, but could eventually fail on some simple peculiar cases, which can be found at http://www.p-value.info/2013/02/when-tfidf-and-cosine-similarity-fail.html. We can have the need for some even more specific and customized measure. If you are a Java programmer and need some theory to define your own customized score, a good place to start is the classic book on Information Retrieval (http://nlp.stanford.edu/IR-book/pdf/irbookprint.pdf). However, it's important to note that similarity calculations generally involve offline computations as a document will have a value computed over the whole collection.