
Every Solr instance now also includes an embedded Zookeeper instance, so we can start our experimentation with that, and then move to a more robust configuration with an external Zookeeper server.
- We can start from the default example in the Solr distribution. We can write the following command:
>> cd ~/SolrStarterBook/solr/example - Then we can start the first SolrCore instance using the configuration for the
artscore:>> java -DzkRun -DnumShards=2 -Dbootstrap_confdir=../../solr-app/chp07/arts/conf/ -jar start.jar - We can then start two more instances, with a slightly different choice of parameters:
>> java -Djetty.port=7777 -DzkHost=localhost:9983 -jar start.jar >> java -Djetty.port=8888 -DzkHost=localhost:9983 -jar start.jar
- This specific approach involves a central Zookeper as this approach is simpler to use. On a real, distributed system we will probably need to adopt a multiple instance Zookeeper instead.
- If you post some data to the Solr instance, you will see that the process is transparent. If we want to know from which of the shards a document has been retrieved, we have to use the usual parameter
fl=[shard].
The parameter -DzkRun is the one that actually starts a Solr instance, requiring to start the internal Zookeeper one. The result is that this instance will now act as SolrCloud one.
In the first example we adopt the configuration for arts Solr core using the -Dbootstrap_confdir parameters. Remember that your configuration needs to be specified only the first time you connect the instance to Zookeper, in order to publish it on Zookeeper itself. Another option would be using a specific command-line command (refer to http://wiki.apache.org/solr/SolrCloud#Command_Line_Util), and if we publish an already published configuration again this will be discarded to load the new one.
The parameter -DnumShards=2 needs to be specified only at the beginning. If we want to change the number of available shards later, we will have the chance to do it by using some specific collection API:
/admin/collections?action=<chosen_action>
Here, we can use some self-explicative action, RELOAD, SPLITSHARD, DELETESHARD, DELETE, and others. For example, let's try the following command:
>> curl -X GET 'http://localhost:8983/solr/admin/collections ?action=CREATE&name=newCollection&numShards=3&replicationFactor=4'
This could be used to create a new collection. This is only a brief introduction, but you can find some growing documentation at
http://wiki.apache.org/solr/SolrCloud#Managing_collections_via_the_Collections_API
You will also find more details on using external Zookeeper, configuring files manually, and so on.
When starting the other two instances, we only needed to choose a different port for every jetty instance (-Djetty.port=7777), and finally to point the instance to the same Zookeper running instance (-DzkHost=localhost:9983), in our case it started with the first core. Note that we know the port where our Zookeper is running, because when it is started as an embedded component with Solr, it uses a port value equal to solr_port + 1000 by default. Since we had defined two shards, and started a first core and then two new cores so that we have more running cores than the pre-defined number of shards, the third will be automatically chosen to be used as a replica, using a round-robin selection strategy.
If we want we can verify that by using an almost still evolving web interface:
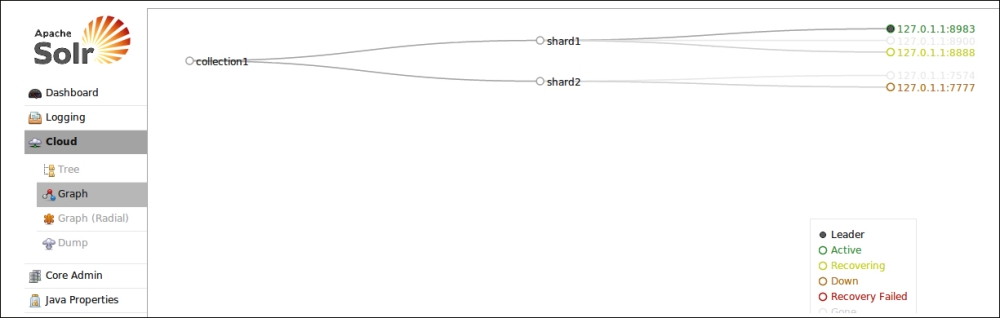
When using SolrCloud we require a unique ID over multiple shards internally, and a version marker field, in order to be able to manage data and eventually store them pretty much as a NoSQL database. All documents will be available quickly, after a soft commit, and can be retrieved in Near Real Time search, so we need to configure some fields and components for this to work properly.
We can introduce a _version_ field in our schema, to track changes in a certain document:
<field name="_version_" type="long" indexed="true" stored="true" multiValued="false"/>
If we want to enable the transaction log, currently used for real-time GET, we can add a configuration, as shown in the following code:
<updateLog>
<str name="dir">${solr.data.dir:}</str>
</updateLog>
[...]
<requestHandler name="/replication" class="solr.ReplicationHandler" startup="lazy" />
[...]
<requestHandler name="/get" class="solr.RealTimeGetHandler">
<lst name="defaults">
<str name="omitHeader">true</str>
</lst>
</requestHandler>Note that we are already using most of these configurations, so the adoption of SolrCloud should not be too complicated. The /get handler is generally suggested to check if a document exists on one of the shards, but it's not strictly needed, and the /replication handler manages replicated data almost transparently.
Since using SolrCloud involves several different aspects of managing Solr, and requires a deep understanding of how the components work and how to use them effectively, I have collected some clear web resources that I suggest for learning more on the topic and starting your own custom experimentation, when you feel you are ready:
- http://wiki.apache.org/solr/SolrCloud
- https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
- http://architects.dzone.com/articles/solr-43-shard-splitting-quick
- https://cwiki.apache.org/confluence/display/solr/Shards+and+Indexing+Data+in+SolrCloud
- https://cwiki.apache.org/confluence/display/solr/Getting+Started+with+SolrCloud
- https://cwiki.apache.org/confluence/display/solr/Command+Line+Utilities
- https://cwiki.apache.org/confluence/display/solr/Collections+API
- http://www.youtube.com/watch?v=IJk8Hyo6nv0
Q1. What is Zookeeper? Why do we have to use it with Solr?
- Zookeeper is a standalone server that can be used to maintain synchronized configurations between distributed services.
- Zookeeper is a component of SolrCloud that can be used to maintain synchronized configurations between distributed services.
- Zookeeper is a standalone server that can be used to synchronize data between distributed Solr instances.
Q2. What are the differences between a distributed search and index replication?
- A replicated index is a copy of an original index, which can be used as a shard for serving more users at the same time. A distributed search is a search over different shards, generally different Solr instances.
- A replicated index uses a master and one or more slaves to replicate data of a single index multiple times, providing the capability of serving more users at the same time. A distributed search is a search over different shards, generally different Solr cores.
- A replicated index is a collection of shards, which are actually replicas of the same original index. A distributed search is a search over different shards.
Q3. Is it possible to use shards over different schema definitions?
- Yes, we can use shards with different schemas as long as long as their configurations are compatible.
- No, we cannot use use shards with different schema as we must use the same configuration for every core.
Q4. What is Carrot2 document clustering?
- Carrot2 is a Solr component that can be used to add a specific similarity algorithm to Solr.
- Carrot2 is an engine that can be used for document clustering from the Solr results.
- Carrot2 is a web application that can be used to visualize clusters of Solr documents.
Q5. What differences exists between using multicores and shards?
- A shard is a single Solr core that can be used inside a distributed search involving all the cores from the same Solr instance (multicore).
- A shard is a self-sufficient Solr multicore installation, whose cores can be used inside a distributed search, while with multicore we refer to more than a single core inside the same Solr instance.
- A shard is a self-sufficient Solr core that can be used inside a distributed search, while with multicore we refer to more than a single core inside the same Solr instance.