
Another good place to start writing custom code can be thinking about the integration of a Named Entity Recognizer. For this task, we can adopt the well-known Stanford NER (http://nlp.stanford.edu/software/CRF-NER.shtml). We need to write code to wrap the functionality of this library, and decide it will run at what stage in the internal workflow.
Tip
A simple and working idea on how to handle this library with Scala can be found in a good example by Gary Sieling at http://www.garysieling.com/blog/entity-recognition-with-scala-and-stanford-nlp-named-entity-recognizer.
One good choice is to implement it as an update processor or as a language analyzer, and then use it as well as the other standard components.
- First of all, let's write a simple test case in Scala, inspired by the default behavior of the NER (note that it loads a model from an external file):
@Test def testNERFilterNoXML() = { val tokenizer_stream = new KeywordAnalyzer().tokenStream("TEST_FIELD", new StringReader("Leonardo da Vinci was the italian painter who painted the Mona Lisa.")) assertTokenStreamContents(new NERFilter(tokenizer_stream, false, "ner/english.all.3class.distsim.crf.ser.gz"), List("Leonardo/PERSON da/PERSON Vinci/PERSON was/O the/O italian/O painter/O who/O painted/O the/O Mona/PERSON Lisa/PERSON./O").toArray) } - The actual plugin will require some attention, but it's not as complex as we may expect:
final class NERFilterFactory(args: Map[String, String]) extends TokenFilterFactory(args) with ResourceLoaderAware { val useXML: Boolean = getBoolean(args, "useXMLAnnotations", false) val model: String = new File(this.require(args, "model")).getCanonicalPath() override def create(input: TokenStream): TokenStream = { new NERFilter(input, useXML, model) } override def inform(loader: ResourceLoader) = { // TODO } } final class NERFilter(input: TokenStream, useXML: Boolean, classifierModel: String) extends TokenFilter(input) { val ner = new NER(classifierModel) this.clearAttributes() override final def incrementToken(): Boolean = { if (input.incrementToken()) { val term = input.getAttribute(classOf[CharTermAttribute]) val text = term.buffer().toList.mkString("").trim term.setEmpty() val annotatedText = ner.getAnnotatedText(text, useXML) term.append(annotatedText) true } else { false } } }
- While developing a new plugin, it should be made available to the Solr instance we'd like to use for testing. This can be done in the following ways:
- Place the JAR files in the lib directory of the
instanceDirobject of the current SolrCore, which is used for test. - Write a lib directive in
solrconfig.xml, as we already did for Tika or SolrCell earlier. - Using Maven or similar tools for testing. In this case, the tool will assemble your WAR file directly with the new JAR file, or give you the chance to manage the classpath.
- Place the JAR files in the lib directory of the
- After we finish developing and testing our new plugin, we can load it to our Solr core by adding the following lines to
solrconfig.xml:<lib dir="${solr.core.instanceDir}/lib/" regex="solrbook-components-scala.jar" /> <lib dir="${solr.core.instanceDir}/lib/" regex="scala-.*.jar" /> <lib dir="${solr.core.instanceDir}/lib/" regex="stanford-corenlp-.*.jar" /> - In this case,
solrbook-components-scala.jaris the compiled library containing our new custom components, and then we will also add the Scala library and the Stanford core. Then, ourschema.xmlfile will be updated as follows:<fieldType name="text_annotated" class="solr.TextField"> <analyzer> <tokenizer class="solr.KeywordTokenizerFactory" /> <filter class="it.seralf.solrbook.filters.ner.NERFilterFactory" useXMLAnnotations="false" model="${solr.core.instanceDir}conf/ner/english.all.3class.distsim.crf.ser.gz" /> </analyzer> </fieldType> [...] <field name="abstract" type="text_annotated" indexed="true" stored="true" multiValued="false" /> - And the last thing to do is perform a query to see how the data returned will be annotated, as the Unit Test suggests. You will find the complete code for this at
/SolrStarterBook/projects/solr-maven/solr-plugins-scala.
This is a simple query that will return an annotated version of the original text data. So, if we index on the text Leonardo da Vinci was the italian painter who painted the Mona Lisa., we will obtain the resultant data as an alternate, which is an annotated version of the same data in XML: <PERSON>Leonardo da Vinci</PERSON> was the italian painter who painted the <PERSON>Mona Lisa</PERSON>. or as a plain annotated text file: Leonardo/PERSON da/PERSON Vinci/PERSON was/O the/O italian/O painter/O who/O painted/O the/O Mona/PERSON Lisa/PERSON./O. The annotated text will be a bit less readable for us, but this way it's easy to recognize the entities.
Note
Apache UIMA is a powerful framework providing not only NER components, but also annotations based on rules, dictionaries, and part of speech tagging. The adoption of UIMA requires to go far beyond the scope of this book, but you can find a simple trace of configuration at /SolrStarterBook/solr-app/chp09/arts_uima. You can use this draft to start your experiments with this framework. Follow the instructions provided on the official wiki: http://wiki.apache.org/solr/SolrUIMA.
The BaseTokenStreamTestCase plays a central role here, because it provides facility methods to simplify testing. Looking at the example, we will see that we have adopted a KeywordAnalyzer class to emit a phrase without splitting it on terms. We can then pass its output to our new NERFilter, and then verify whether the original phrase has been correctly annotated as we expected.
The most interesting part is on the actual code for NERFilter. The class will be a subclass of TokenFilter (extends TokenFilter), so that it can be used inside a normal chain of analysis. In order for this to work, we generally need to create a specific implementation of the incrementToken() method where we perform our analysis. In our case, we will simply put all the logic instantiating the NER class wrapper, and then execute an entire phrase annotation. Remember this code is just an example. It is not meant to be fully functional. However, you will find the complete source (including the source for NER wrapper) in the it.seralf.solrbook.filters.ner package in the /SolrStarterBook/projects/solr-maven/solr-plugins-scala project.
Once we have written our filter, we have to make it available through a specific NERFilterFactory class (a subclass of TokenFilterFactory). The create() method of this class will take a TokenStream object as input, and will also emit the output as a TokenStream. As you can see, we need to pass a couple of configurations to the filter (one of them being the name of the file from which to load the model). The parameters will be available as an args map for our factory. A typical implementation will also implement the ResourceLoaderAware interface to load the resources by the internal components.
When all seems to work correctly we can finally put our new component into a Solr core. You'll find /SolrStarterBook/solr-app/chp09/arts_ner, including a lib folder that will contain the JAR files for our plugins and the Standford libraries. Note that we decided to write our draft with the Scala language. So, in order to obtain a reference to the standard library of the language, we can also simply put the Scala core libraries in the same directory (if you have not yet put it on the classpath earlier).
Remember we can put our JAR files into a lib directory local to the Solr core, or into a lib directory shared between Solr cores, or anywhere else on the filesystem. The choice really depends on how we'd like to manage our configurations, because it's possible to use any of the options seen before to point a relative or absolute path to a lib directory containing third-party JAR files from a solrconfig.xml or a solr.xml file, or even by adding it to classpath from the command line.
The first thing to remember while thinking about Solr customization is the most obvious one. We have to ask ourselves what we really need, and if this is really not yet covered by some existing (sometimes not yet well documented) components. I know that from a beginner's point of view, reading about too complex components may seem contradictory; but I feel that after reaching the end of the book, you should have a last chance to look at different concepts and components in perspective:
- Low-level customization involves writing new components such as
Analyzers,Tokenizers,TokenFilters,FieldTypesfor handling Terms, Fields, and Language Analysis. - In this context, we can also override the default similarity implementation
<similarity class="my.package.CustomSimilarity"/>. - The codec choice is strictly related to the Terms internal format. From Lucene 4, it is possible to adopt different codecs (for example, the
SimpleTextCodecused for some examples). It's even possible to write our own examples when needed. In the same way, we can change thedirectoryFactoryused, for example, introducing an HDFS compliant one:<directoryFactory name="DirectoryFactory" class="solr.HdfsDirectoryFactory">, or we can adopt different SolrCache strategies. - From Solr 4 onwards, it's also possible to provide preanalyzed fields: http://wiki.apache.org/solr/PreAnalyzedField. These particular fields are useful in the direction of a NoSQL usage of Solr, since they act as a common tokenized field on certain terms. They also give the option of storing data directly into the Solr index without analyzing it, for example, in the JSON format. On the other hand, there are chances to save field values on some external files as well: http://docs.lucidworks.com/display/solr/Working+with+External+Files+and+Processes. In both the cases, searching on these fields is not supported for obvious reasons. But these implementations can be extended to store more structured data.
- While handling queries, we can implement a new
ValueSourceParserto expand the set of available functions queries with new, customized ones:<valueSourceParser name="a-new-function" class="some.package.CustomValueSourceParser" />. We can even change the query parsing by itself by using subclasses ofQparserPlugin:<queryParser name="a-new-queryparser" class="some.package.CustomQueryParserPlugin" />. In the latter case, we have the chance to use the brand new parser as usual, with the adoption of a parameterqtor by a specific configuration insolrconfig.xml.
In this list, there are elements that you should now be able to recognize; and others that require some more study of Solr and its internals. The UpdateHandler and DataImportHandler are the most interesting ones for customizations, because they offer access to the indexing workflow. In addition to these, we can use some specific SolrEventListener to trigger customized actions or command-line tools when a certain event occurs (for example a document is deleted or updated).
In order to define the logic for every request, we can create a new request handler, as we already saw <requestHandler name="a-new-handler" class="some.package.CustomHandler"> that can re-use new SearchComponent.
Finally, a useful possibility is to define a different formatting for outputting the results of a certain query: <queryResponseWriter name="a-new-responseWriter" class="some.package.CustomResponseWriter" />.
Remember that these are only some of the possibilities in the path for customizations. I hope that this recap will be useful to you to reorder your ideas and decide where you want to move next with your experimentations and studies, prototyping the frontend with an embedded Solr using VelocityResponseWriter. There is also a good VelocityResponseWriter plugin, with which you can play. It is available with the standard example. Please refer to http://wiki.apache.org/solr/VelocityResponseWriter for an introduction on that.
We did not use it in detail as this requires knowledge about a specific dialect in order to be used. But it is interesting to look at the following component source in detail because it internally uses classes such as QueryResponse:
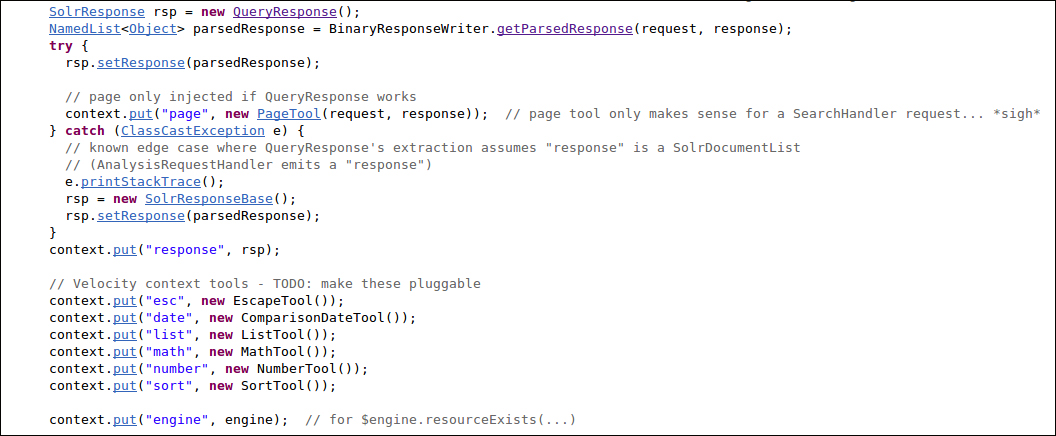
This class is related to an "embedded" Solr instance. Indeed it exists as an EmbeddedSolr wrapper object too: http://wiki.apache.org/solr/Solrj#EmbeddedSolrServer. As we said in the beginning of this book, we focused on using Solr as a standalone application; but it can easily be used as a library embedded into other Java (or JVM) applications. In order to do this it's necessary to adopt a convenient named called SolrJ, which contains some useful classes to handle a remote, local, or even an embedded instance of Solr. The point here is that, from the SolrJ perspective, we are interacting with Solr as a client. And if you think about the fact that the QueryResponse class that is used as a wrapper in the VelocityResponseWriter class is available in this library, the distinction between a client library and a facility component becomes very fuzzy. We will have a chance to introduce the existing clients for Solr in the appendix of this book, where we will be reading about more specific Solr customizations.
When you'll want to work on your own customizations, there are many resources that can be used as a reference. I suggest that you start with the following list:
- Solr Reference Guide: This is the official reference guide, recently donated to the the community by Lucid Works: https://cwiki.apache.org/confluence/display/solr/Apache+Solr+Reference+Guide.
- Writing new plugins: Starting from the official wiki page, it's possible to look for the usage of Unit Test and Mock objects at http://wiki.apache.org/solr/SolrPlugins#Building_Plugins.
- A WikipediaTokenizer: This is available at http://lucene.apache.org/core/4_5_0/analyzers-common/org/apache/lucene/analysis/wikipedia/WikipediaTokenizer.html.
- Third-party components: There are also many third-party components that can adopt very different approaches, and can be integrated with Solr if/when needed. A good option is, for example, the stemmer based on the WordNet dictionary at http://tipsandtricks.runicsoft.com/Other/JavaStemmer.html.
Note
Wordnet is a lexical dictionary for English, which aims to collect (almost) all English words and group them by their stem: http://wordnet.princeton.edu/wordnet/.
- Similarity algorithm based on singular value decompositions is available at http://www.ling.ohio-state.edu/~kbaker/pubs/Singular_Value_Decomposition_Tutorial.pdf.
- Text categorization with Solr: http://raimonb.wordpress.com/2013/01/02/text-categorization-with-k-nearest-neighbors-using-lucene/.
- NLP with UIMA and Solr: http://www.slideshare.net/teofili/natural-language-search-in-solr.
- Sentiment Analysis and Visualization using UIMA and Solr: http://ceur-ws.org/Vol-1038/paper_5.pdf.
This is obviously just a small selection, but I hope they can give you some suggestions to move further with the introduction of natural language capabilities, the improvement of language analysis, and the integration of information retrieval tools.
If and when you'll develop new components, please remember to share them with the community if possible.
Q1. What is a stem?
- A stem is a synonym for a certain word.
- A stem is a Term which can be used as a root for constructing compound words.
- A stem is the base root for a group of words.
Q2. What is a Named Entity Recognizer?
- It is a component designed to recognize/annotate textual entities.
- It is a component designed to give a name to textual entities.
- It is a component designed to recognize the correct name of a textual entity.
Q3. What are the purposes of the ResourceLoadedAware and SolrCoreAware interfaces?
- They can be implemented from the components that need to load the resources and specific cores.
- They can be implemented from the components that need to obtain references to the resources and core configurations.
- They can be implemented from the components to write new resources to the disk and change the core configuration values.
Q4. What is the correct order in which plugins are evaluated?
- First the classes implementing
ResourceLoaderAware, and then the classes implementingSolrCoreAware. - The order is not relevant.
- First the classes implementing
SolrCoreAware, and then the classes implementingResourceLoaderAware.