
In this chapter, we will have the chance to play with the DataImportHandler facility. We will provide an introduction to the most interesting directions where it's possible to use it.
We will see how it's possible to use a Solr instance to index all different sources without necessarily resorting to a lot of programming, focusing on how to define a simple indexing workflow with XML configuration. This can be interesting; for example, for acquiring data for preliminary prototyping and analysis, in order to provide integrations for existing legacy sites. It can also be used to implement a central service for searching data we want to access over our applications, e-commerce sites, or OPAC.
Since the beginning of this book, we have decided to focus on making example data available quickly, just to have the opportunity of learning how to manage the basic elements in Solr and how to combine them. Most of the indexing and searching examples have been designed to give an idea about how to do the same in a way agnostic from a specific programming language. We used cURL just to fix the idea, but we could have used other tools as well. However, generally you don't want to expose your Solr data directly. On most of the projects, you will have a Solr machine available for the other components, similar to what we usually have in other services like DBMS, Single Sign-On, and so on.
There are many ways in which Solr can be integrated in your application. It can be used as a remote service that is external to your site or application but not publicly exposed, and this will be the most common use case. It can even be exposed directly by using a ResponseWriter, to provide results in other formats (think about the examples we made using XSLT and RSS). Or else, we can even provide a direct navigation over the data, as for the VelocityResponseWriter. As a last option, you can of course write your own components that can be used on every step in this workflow.
Note
There is an interesting presentation by Brian Doll, describing a case study for e-commerce, in which you will find a lot of important aspects at http://www.slideshare.net/briandoll/ecommerce-4000378, for example good language stemmers, faceting, avoiding the one-size-fits-all strategy, and others.
Solr can be used in many ways, and it can be used to speed up the procedure of finding the reference to data records that are stored in many different ways. From this point of view, it can be seen as a basic component for writing your own deduplication and fast master data management processes, obtaining an index which is really decoupled from the actual data. From this perspective, we want to play a little with the "automatic" indexing from external sources, which is provided from DataImportHandler. But don't worry, we don't have plans to use Solr as a general purpose tool: we only want to have overview on DataImportHandler.
In this scenario, the DataImportHandler is one of the most interesting and useful family of components. This component permits us to read data from external data sources, and index them directly and incrementally. From the configuration, we can define how to handle the records of data while reading them, in order to create at runtime a new Solr document for each one and indexing it directly. This is basically an implicit definition of an indexing workflow, and it is designed to be easily chained with the maintenance tool (using an event handler) or called as a scheduled task.
This kind of process will generally start by calling a specific handler, passing to it one of the following possible commands: full-import, delta-import, status, reload-config, abort. We will see these commands from the web UI interface in a while, but they can be called from the command line as well. In that case, abort, reload-config, and status will help us to monitor the process. With delta-import, we will be able to start a new indexing phase for new records. Also, full-import will be the most-used command as it will start a complete reading and indexing activity on our data.
The complete import in particular will support extra parameters. Some of them are quite intuitive (clean, commit, optimize, debug) and refer to the operations that we were able to perform on other handlers in previous examples. But there is also an interesting entity parameter that offers us a good starting point for learning how the process will work.
The process is described in the following diagram:
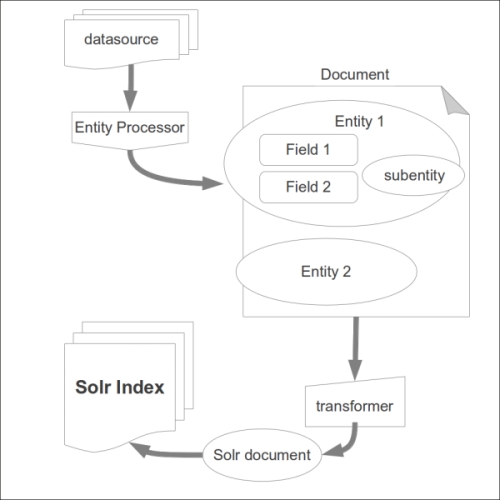
As you can see in the diagram, an entity is basically a collection of fields. We can have more than one entity for the same document, and we can even collect sub-entities. As you can imagine, the role of such entities is to collect fields into a logical container (it's similar to the logical denormalization seen before in Chapter 7, Working with Multiple Entities, Multicores, and Distributed Search). This is important when we are posting data on a single index, and we need to construct our document assembling data that can be read from different sources in different ways.
The main element will then be the entity itself. It should have the pk attribute to identify its instances uniquely during the indexing process, a name to be able to reuse its field's value later when needed, and a reference to one or more transformers. These components are useful to manipulate data during the workflow, just before indexing it.
From this point of view, it's simple to imagine that an entity will be always handled by a specific type of processor, to know how to handle a certain specific data type available from the data source connected to the entity. Every processor will emit a specific predefined field for the data it processes, and we can manipulate them before posting them to Solr, using the transformers.
A processor can be designed to handle a stream of data, a single line of data (a record), or collections of data. This turns out to be useful because we can collect, for example, a list of filenames with an entity, and then manipulate the content of a single file with a subentity that will use a specific processor.
When we handle the data emitted from some kind of Entity Processor, we have predefined fields. They can be indexed directly into an appropriate Solr schema, or we can manipulate their values and add more customized ones. Note that during prototyping, you can add almost every field, and spend time later to shape the schema.xml and DataImportHandler configuration in a more specific way.
There are many more interesting details on the DataImportHandler in the official wiki page: http://wiki.apache.org/solr/DataImportHandler. I encourage you to play with our examples while reading them, in order to become more familiar with the tool. Now, we will have a look at a simple DataImportHandler configuration
An initial configuration for a DataImportHandler is really simple, although it's intuitive to understand that complex processes on heterogeneous and structured data can be very complex depending on the schema and data manipulations. We will start our example with a simple configuration in order to fix the idea on the basic elements.
In order to define a schema.xml file, we don't need a lot. So, I suggest to start with a minimal one (using dynamic fields, mostly). Then, we can define a /SolrStarterBook/solr-app/chp08/solr.xml file as usual for handling the examples in this chapter.
What we really need to configure here is a new request handler in solrconfig.xml that will trigger the process. This handler will also use a library that we have to import, and most important of all, it will reference one (or more, but keep it simple) external file where we will put all the configuration specific to the DataImportHandler:
<lib dir="../../../solr/dist/" regex="solr-dataimporthandler-.*.jar" />
<lib dir="${solr.solr.home}/${solr.core.name}/conf/lib/" regex="sqlite-jdbc-.*.jar" />
...
<requestHandler name="/dih" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="update.chain">data-extraction</str>
<str name="config">DIH.xml</str>
</lst>
...
<updateRequestProcessorChain name="data-extraction">
<processor class="solr.StatelessScriptUpdateProcessorFactory">
<str name="script">extract_fields.js</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>In this example, DIH.xml is the name of your specific configuration (you can find it under /SolrStarterBook/test/chp08/wgarts/conf/DIH.xml), and you can also define multiple request handlers, as well as add multiple different configurations for the same handler. I suggest you to separate the different configurations for different sources whenever it's possible, but sometimes you need to put all of them at one place. There is no general rule for this, and it really depends on the need.
As we will see, it's possible to define a script inside the DataImportHandler configuration file directly. This is useful to do manipulation on the data. However, we can also bind an update chain to the DataImportHandler process. In the example, I have created an external extract_fields.js script to parse some of the data and save them into specific fields.
By using <lib dir="${solr.solr.home}/${solr.core.name}/conf/lib/" regex="sqlite-jdbc-.*.jar" />, we will be able to add to the Java classpath to a local lib folder, which contains the library that we need to access the specific JDBC driver we will use. This is needed by Solr to be able to load the library and use it. Every JDBC implementation will expose a common standard interface, but we need to download the actual implementations we are going to use. So, it's very common to put here more than once.
Instead, the ${variable} syntax is used to acquire the data that is already defined at some point in memory. In this case, they simply refer to the current Solr home and core name.
The ${some.variable.name} format is widely used within many Java libraries and frameworks (it is also supported as a language feature in Scala). It's worth noting that Solr uses the usual convention of variable names divided with points to represent a sort of namespace. For example, by reading ${solr.core.name} we can understand the meaning of the variable, and we can imagine to find other variables with names, such as ${solr.core.dataDir}, ${solr.core.config}, and ${solr.core.schema} for other core-specific configurations. While the core configurations usually also require the restarting of a core when their values are changed, a change on entity in the DIH context does not require to reload the core.
At this point, we need sample data to and we need it to be from sources other than the one from where we downloaded data before. In particular, we want to approach using the DataImportHandler by one of the most recurring use case: indexing the data that are actually stored on a relational database, such as Oracle, MySql, or Postgres.
In order to have data, and keep the process simple, I decided to download a free copy of the very good art database provided by the project Web Gallery of Art.
Note
The Web Gallery of Art is a project created by Emil Krén and Daniel Marx. The site is a kind of virtual museum for European fine arts from 11th to 19th century. You can find details on the project at http://www.wga.hu.
The original database is available in various formats, including MySQL; but in order to avoid installing other things and to keep the process simple, I converted it into the SQLite format. You can find the actual SQLite file database in the SolrStarterBook/resources/db directory.
Tip
SQLite is a library that implements a self-contained SQL database engine, which is used by browsers such as Firefox or Chrome to save bookmarks and navigation data. We will use a SQLite Java implementation. You can find more information on the project at: http://www.sqlite.org/.
As we want to simulate the basic operation of a real-world use case here, I have changed the original database schema slightly, introducing a shallow normalization on the tables. You will find the final tables on the right-hand side of the following screenshot:
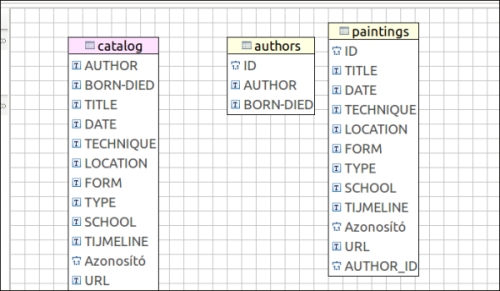
Basically, I have moved the authors information to a separate table, introduced an ID for every table in the right as a primary key (this is the commonly used situation), and introduced an AUTHOR_ID parameter on the paintings table to be able to perform joins between tables. In order to have the chance to play a little with the data, I decided to maintain the original names and values of the columns, so that we can manage normalization or manipulation on both of them directly during the import phase.
These little changes give us the chance to play with more than a single table at once, without introducing too much complexity. But the general approach we use on this is basically the same we can use, for instance, over data from an e-commerce sites (with far more complex schema), such as Magento or Broadleaf, or similar ones.
When using DataImportHandler for indexing data on a relational database, we are decoupling the search and navigation capabilities offered by Solr services from the maintenance of the actual data. This is good, because we can still perform the usual CRUD operation on the database, for example, using our CMS or backend and putting in place a parallel service to explore our data, making them easy to search.
An interesting point here is that if the navigation on the site frontend is deeply integrated on Solr services (this is possible when using Drupal, for example) that contain references to content pages, we obtain the chance of using Solr as a sort of "hot caching" the navigation to our data.
A good point to start is the QuickStart at http://wiki.apache.org/solr/DIHQuickStart, and we will follow a similar approach to construct our simple example.