
A very simple way to play with spellchecking is to define a new request handler to manage this kind of result apart from the common ones. On a real application, you should consider concatenating them directly after the main results, as usual using the appropriate component chain.
- We can start by defining a new
paintings_spellcheckercore, derived from the previous core, and add to itssolrconfig.xmlfile the configuration for a multiple spellchecker using the following code:<searchComponent name="spellcheck" class="solr.SpellCheckComponent"> <str name="queryAnalyzerFieldType">text_auto</str> <lst name="spellchecker"> <str name="name">direct</str> <str name="field">artist_entity</str> <str name="classname">solr.DirectSolrSpellChecker</str> <str name="distanceMeasure">internal</str> <float name="accuracy">0.8</float> <int name="maxEdits">2</int> <int name="minPrefix">1</int> <int name="maxInspections">5</int> <int name="minQueryLength">3</int> <float name="maxQueryFrequency">0.01</float> <str name="spellcheckIndexDir">./spellchecker</str> </lst> <lst name="spellchecker"> <str name="name">wordbreak</str> <str name="field">artist_entity</str> <str name="classname">solr.WordBreakSolrSpellChecker</str> <str name="combineWords">true</str> <str name="breakWords">true</str> <int name="maxChanges">3</int> <str name="spellcheckIndexDir">./spellchecker</str> </lst> </searchComponent> - As you can see, we are operating in a field called
text-auto, which we will define in a while. Moreover we are using two different spellcheckers at the same time, as each one of them simply adds its suggestions to the results section, without causing problems for the other. For every component, we are using different parameters' values. The search component for spellchecking can be easily used by a specific request handler as usual:<requestHandler name="/suggest" class="org.apache.solr.handler.component.SearchHandler"> <lst name="defaults"> <str name="df">artist_entity</str> <str name="spellcheck">on</str> <str name="spellcheck.dictionary">direct</str> <str name="spellcheck.dictionary">wordbreak</str> <str name="spellcheck.extendedResults">true</str> <str name="spellcheck.count">10</str> <str name="spellcheck.alternativeTermCount">5</str> <str name="spellcheck.maxResultsForSuggest">5</str> <str name="spellcheck.collate">true</str> <str name="spellcheck.collateExtendedResults">true</str> <str name="spellcheck.maxCollationTries">10</str> <str name="spellcheck.maxCollations">5</str> </lst> <arr name="components"> <str>spellcheck</str> </arr> </requestHandler> - Note that here we are defining a
/suggestrequest handler that will make use only of the components in the spellcheck chain, and we have put in it several predefined arbitrary values for its parameters. - Let's now define the new type we are going to use for spellchecking in our
schema.xmlfile:<fieldType class="solr.TextField" name="text_auto" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.WhitespaceTokenizerFactory" /> <filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1" /> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> </fieldType> <dynamicField name="*_entity" type="text_auto" multiValued="false" indexed="true" stored="true" /> - Furthermore, for the field that will get this type, we can use
omitTermFreqAndPositions="true"to save a little space and time during indexing. - When everything is configured, we can start Solr in the usual way (don't forget to add the core in the list of the
/SolrStarterBook/solr-app/chp05/solr.xmlfile), and build the spellcheck specific index using the following command:>> curl -X GET 'http://localhost:8983/solr/paintings_spellchecker/suggest?spellcheck.build=true&wt=json' - Then we can play with some example queries; feel free to try several queries on your own. I suggest using a query with a lot of typos. (this has no real meaning), For example purposes you can use
pollok some-text salvator some-text lionardo some-text georgio, as given in the following command:>> curl -X GET 'http://localhost:8983/solr/paintings_spellchecker/suggest?q=artist_entity:pollok%20salvator%20lionardo%20georgio&rows=1&spellcheck=true&wt=json&indent=true'
While playing with our funny example query, we will receive an output similar to the one shown in the following screenshot:
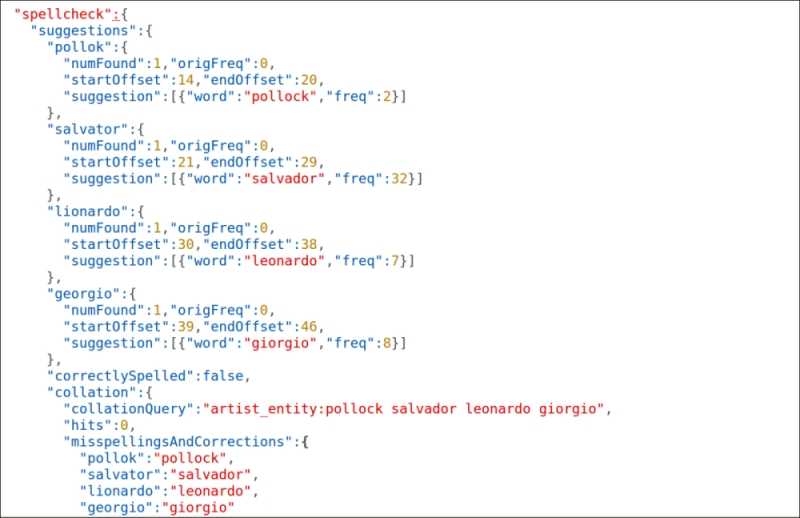
In these results, you can easily recognize one suggestion for each of the misspelled terms pollok, salvator, and lionardo, and two for georgio. Every suggestion also contains the positional information, which is useful to point the suggestion into the actual results when we will play the suggester in conjunction with a normal query.
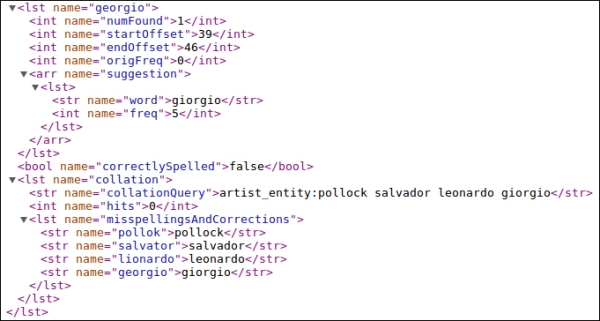
Note that the XML format is slightly different from the JSON one, as it will contain some more information; for example, you will see it in action in the following screenshot, where I have isolated the part for the last suggestion:
As you have seen, we have adopted several arbitrary parameters; I don't want you to think too much about everything now; I prefer suggesting you to play with examples by changing their values and repeat using your query. This way you can start your analysis, and you can find a complete list of the parameters that can be used here: http://wiki.apache.org/solr/SpellCheckComponent#Request_Parameters
The following are the most interesting ones:
queryAnalyzerFieldType: This is the type on which the spellchecker query will be analyzed.field: This is the field used to build spellchecker results.name: This is the name for the chosen spellchecker component. There can be more than one in the same chain.classname: This is the class that implements the spellchecker component interface.maxEdits: This represents the maximum number of changes enumerating a term. At the moment, this value can be1or2. You can think of this value as the quantity of small typos that can be considered for a suggestion.distanceMeasure: This is the algorithm that will be used to calculate term distance; the default one is the well-known algorithm by Levensthein.accuracy: This is the precise value to be achieved for a suggestion to be added as a proper one in the results.spellcheckIndexDir: This is used to define where to save the index specific for spellchecking.
The best way to find good configurations for a spellchecker is ideally to ask real users to give comments on the results, and how they differ from what they expect. In order to do this, we can log users' requests and analyze them to find the uncovered case.
Another very interesting spellchecker can be adopted to perform suggestions starting from a file-based list of controlled words:
<lst name="spellchecker"> <str name="name">file</str> <str name="field">artist_entity</str> <str name="classname">solr.FileBasedSpellChecker</str> <str name="sourceLocation">spellings.txt</str> <str name="characterEncoding">UTF-8</str> ... </lst>
In this example, the spellings.txt file is a simple plain-text file, where every line will contain a word that can be used for spellchecking. This kind of suggestion can be again very crucial when adopted on prototyping, as it is quite simple to add terms in it during an incremental development. For example, you can incorporate log analysis and other user feedback, review them, and then try to add some terms derived from the supervised terms into your spellchecker.
While playing with spellchecking, it's always important to do a good analysis on a specific spellchecker component before putting it in the default chain.
After that, when we will be confident about the accuracy of the results, we can bind the spellchecker component in the standard query handler by using the usual chain parameters in the request handler as follows:
<arr name="last-components">
<str>spellcheck</str>
...
</arr>Moreover, we can explicitly choose which class actually takes the term in the query from the user and maps it to the suggested ones. For example, the standard component will be as follows:
<queryConverter name="queryConverter" class="solr.SpellingQueryConverter" />
This is generally the most obvious choice and you may not need to explicitly write a configuration for it, but you should consider this syntax in case you will have to write your own queryConverter class.
If needed, it is possible to rebuild the index for spellchecking when committed as follows:
<searchComponent name="spellcheck" class="solr.SpellCheckComponent"> <str name="buildOnCommit">true</str> </searchComponent>
This is, however, not a good choice for many applications, since it can become a performance issue, so try to consider this kind of choice carefully.
While talking about the performance of these kinds of components, one has to also reduce the footprint they have in memory, for example, by omitting normalization and by not having them stored.
Furthermore, a good option is decoupling the spellchecked field to the fields used for other purposes. This can be easily done as usual by <copyField>, and this can also be useful to adopt different strategies in the destination field, thus making it more appropriate for the spellchecking process. When we do analysis for the configuration of this component, it's always a good idea to consider removing stemming and similar decomposition of terms from the fields to be used, as they can have a negative influence on the metrics adopted and then on the accuracy. The best will be adopting a word-based n-gram decomposition during the analysis of the field in order to have a good phrase suggestion.
Q1. What is the debug component designed for?
- It is designed to inspect the parsing of a query while it is executed
- It is designed to inspect the results in details, focusing on the values in the documents returned
- It is designed to inspect the results in details, focusing on the values in the documents returned
Q2. What is the context in which we want to adopt spellchecking?
- When we need to be able to perform queries flexible enough to match the same term in different languages
- When we need to be able to perform queries flexible enough to match misspelled words
- When we want to be able to match incomplete words
Q3. What are the main differences between the Lucene query parser and the Dismax one?
- The Lucene parser provides powerful operators for advanced users; it can return more precise results at the cost of queries which are more difficult to write
- The Dismax and Edismax parsers are designed for common users; they can return less precise results, expanding simple user queries
- They are the same, and Dismax and Edismax only introduced some more specific parameters over the Lucene parser
Q4. What are pseudo-fields?
- Pseudo-fields are internal fields that can be used directly in the queries
- Pseudo-fields are a way to call functions, using them with the same syntax used for fields
- Pseudo-fields are a way to call specific components (for example, the
explaincomponent), using the same syntax used for fields
Q5. How can you describe an editorial boosting to a client, during a meeting?
- With editorial boosting, we can promote some specific document at the beginning of our results
- With editorial boosting, users can directly give feedback on the results, changing the ranking of it
- With editorial boosting, the documents in the results are designed by us, and they cannot be changed by queries