
In this chapter, we are going to collect some example data from DBpedia, create new indexes for searches, and start familiarizing you with analyzers.
We decided to use a small collection of paintings' data because it offers intuitive metadata and permits us to focus on some different aspects of data, which are open to different improvements seen in the next few chapters.
First of all we need to have some example resources. Let's say data describing paintings, collected from real data freely available on the Internet.
A good source for free data available on the Internet is Wikipedia
, so one of the options is to simply index Wikipedia as an exercise. This can be done as a very good exercise but it requires some resources (Wikipedia dumps have a huge size), and we may need to spend time on setting up a database and the needed Solr internal components. Since this example uses the DataImportHandler component, which we will see later, I suggest you follow it when we will talk about importing data from external sources:
http://wiki.apache.org/solr/DataImportHandler#Example:_Indexing_wikipedia
Because we want to start with a simpler process, it's best to focus on a specific domain for our data. First, we retrieve Wikipedia pages on some famous paintings. This will reduce some complexity in understanding how the data is made. The data collection will be big enough to analyze, simulating different use cases, and small enough to use again and again different configuration choices by completely cleaning up the indexes every time. To simplify the process more, also using well-structured data, we will use the DBpedia project as our data source, because it contains data collected from Wikipedia and is exposed in a more structured and easy-to-query way.
Tip
From day-to-day processes, such as web scraping of interesting external data or Named Entity Recognition, processes to annotate the content in some CMS are beginning to be very common. Solr also gives us the possibility to index some content we might not be interested in saving anywhere; we may only want to use it for some kind of query expansion, designed to make our search experience more accurate or wide.
Suppose, as an example, we are a small publisher, and want to produce e-books for schools, we would want to add an extended search system on our platform. We want the users to be able to find the information they need and expand them with free resources on the web. For example, the History of Art book could cite the Mona Lisa, and we would want the users to find the book in the catalog even when they digit the original Italian name Gioconda. If we index our own data and also the alternative names of the painting in other languages without storing them, we will be able to guarantee this kind of flexibility in the user searches.
Nowadays, Solr is used in several projects involved in the so-called "web of data" movement. You will probably expect to have multiple sources for your data in the future—not only your central database—as some of them will be used to "augment" your data—or to expand their metadata descriptions—as well as your own queries, as a common user.
Just to give you an example of what data is available on DBpedia, let's look at the metadata page for the resource Mona Lisa at http://dbpedia.org/page/Mona_Lisa, as shown in the following screenshot:
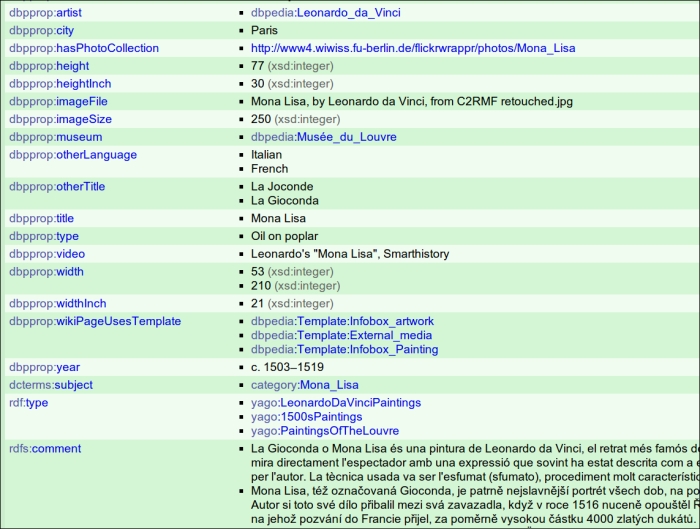
We will see later how to collect a list of paintings from DBpedia, and then download the metadata describing every resource, Mona Lisa included. For the moment, let's simply start by analyzing the description page in the previous screenshot to gain suggestions for designing a simple schema for our example index.