
One of the more recently added features is the so-called pseudo-join . This functionality permits us to explore queries that contain constraints on values between different fields. The term join is partially misleading, but makes sense if we consider the possibility of using this feature on fields from two different indexes.
Let's look at a simple example, using the paintings_geo and cities examples from Chapter 5, Extending Search.
- Let's start with the examples from Chapter 5, Extending Search by executing
>> cd /your-path-to/SolrStarterBook/test/ >> ./start.sh chp05 (*NIX) >> start.bat chp05 (win)
Please always remember to populate the cores with your data, for example, using the provided scripts in the path
/SolrStarterBook/test/chp05for each core. - Once the cores are running, we can search for cities where we will find some
Caravaggioart:>> curl -X GET 'http://localhost:8983/solr/paintings_geo/select?q=artist:caravaggio+AND+{!join+from=city+to=city+fromIndex=cities}city:*&fl=city,score&wt=json&json.nl=map&indent=on&debugQuery=on - A similar and more efficient query could be rewritten by using the following filters:
>> curl -X GET 'http://localhost:8983/solr/paintings_geo/select?fq=artist:caravaggio&q={!join+from=city+to=city+fromIndex=cities}city:*&fl=city,score&wt=json&json.nl=map&indent=on&debugQuery=on' - Now we will try an almost opposite example:
>> curl -X GET 'http://localhost:8983/solr/cities/select?q={!join+from=city_entity+to=city+fromIndex=paintings_geo}abstract:caravaggio+AND+city:*&fl=city,display_name,score&df=fullText&wt=json&indent=true&debugQuery=on' - In this case, we are searching the cities and we could expect to obtain the same results using a relation-like thinking. Wrong! We didn't obtain just four results as expected, but 48 results, because we are actually obtaining several false positives! In the following screenshot the first and second results are displayed to the left, and the first part of the results from the last example are displayed to the right:
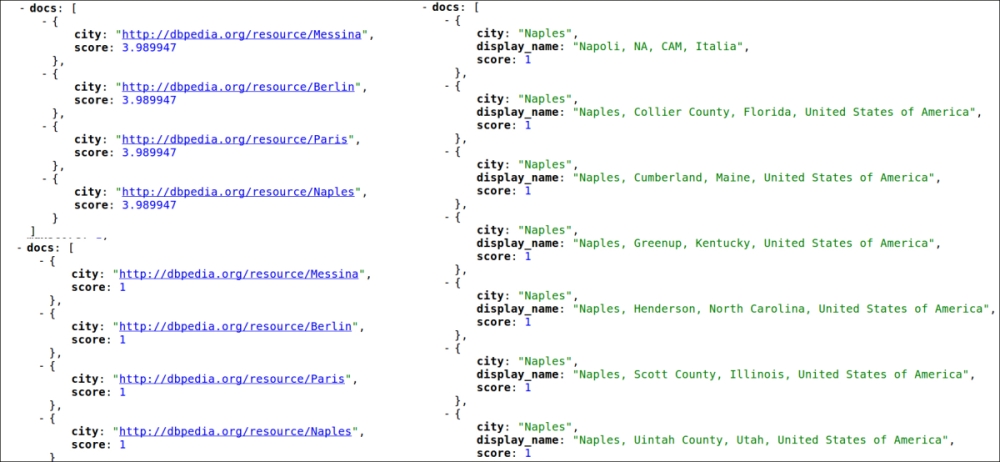
- It's easy to note that the last result also includes false positives, which matches the name of a city (for example, Naples), but actually does not really refer to one of the paintings we are interested in. We searched for a reference on the Italian painter Caravaggio, but we also found cities in the United States!
In these examples we are using two cores with very different schema and configurations, each defining a city field, which can be used in our join queries. In the first query we are searching for documents on the cities core that contain values for the city fields (city:*); then we will match the results with documents in the paintings_geo core that have the same value. At the same time we want to apply the criteria abstract:caravaggio to our painting's results. We can obtain a similar result by using a filter query, as in the second example. In the second example using the debugQuery=on&fl*,score parameters it is simple to see how the score will differ. In particular, in the second example we will obtain the same results, but all the documents here have a score value 1, while in the first example they have a greater value. The reason for this difference is that in the second case the filter query restricts the collection on which we are searching for caravaggio references. Also remember that score values are not normalized, so in the first case the results should have a score value greater than other documents in the collection.
Executing the last query, which is somewhat in the opposite direction (first search on paintings_geo, then match on cities), we saw that the results do not fit our expectations.
In order to understand what is happening, an option is to ask for the complete list of the city names for paintings matching our chosen criteria:
>> curl -X GET 'http://localhost:8983/solr/paintings_geo/select?q=abstract:caravaggio+AND+city:*&rows=100&wt=json&debugQuery=on&fl=city'
We found 8 matching documents, referring to cities: Messina, Valletta, Siracuse, Paris, Naples, Marseille, Berlin, and Toronto. Note that, without excluding documents with the city field empty by using the city:* condition, we would instead obtain 38 results. If we simulate the matching process by executing individual queries on the cities core, we find 48 matching results, obtained by the following piece of code:
matching documents (48) = Messina (2) + Valletta (3) + Siracuse (0) + Paris (10) + Naples (10) + Marseille (3) + Berlin (10) + Toronto (10)
This is very interesting, as we are producing results that may not match the abstract:caravaggio criteria clearly. Our misuse of the join has increased our recall, and the system is guessing some cities with the same name, loosing the initial criteria and also some precision. If you have some experience with a relational database, you may point out that this could be seen similar to what happened with cartesian product, but remember that we are not using actual relations here, but only fields matching between documents.
It's useful to provide a couple of examples to think about how to shape our entities, including pros and cons, starting from multicore to denormalization into a single core, but first of all we need to download some more example data.
We will use a slightly rewritten version of the same script used to download data examples from DBpedia in Chapter 3, Indexing Example Data from DBpedia – Paintings. As long as the data collected grows there are chances that they could contain errors and problems of formatting. We can skip the problematic records when needed. I always suggest starting by isolating and skipping the tricky records from your prototypes, to remain focused, and later adjusting the process incrementally. In our case the RDF/XML serialization downloaded sometimes contains unwanted characters/tags, and we have to strip them off or ignore them in order to have our process running for most of the data collected. Then let's focus on acquiring as many data we can for our test examples, and don't worry if we miss something.
The first thing we need for populating our examples is a good data collection, which contains data to be used for different entities. If you are not interested in details about the downloaded data and creating the corresponding XML files for Solr, please skip directly to the Playing with joins on multicores (a core for every entity) section.
Following a similar approach to the one we used when we started with the first example on paintings data, we could easily start by downloading data for paintings using the following commands:
>> cd [path-to-SolrStarterBook]/test/chp07/arts >> downloadPaintingsData.sh
If you have already done this or if you are not interested in this part, you could easily skip it and start using the already downloaded XML files you will find at /SolrStarterBook/resources/dbpedia_paintings/downloaded.
Once we have downloaded the files for paintings, we can easily download other data using the reference contained in the XML files we have downloaded so far. Every resource from DBpedia contains links to other resources that can be used to create a good playground of data.
In order to download data for artists, museums, and subjects, we will use another simple Scala shell script:
>> downloadMoreEntities.sh
The script (at /SolrStarterBook/test/chp07/arts) does nothing more than search for (in a painting resource) references of a certain type, and then download the corresponding representations. You don't need to use this script if you don't want to, as you will find some pre-downloaded files at /SolrStarterBook/resources/, divided into different dbpedia_paintings, dbpedia_artists, dbpedia_musems, and dbpedia_subjects folders.
Once we have collected the XML/RDF representation for our data, it's time to produce the corresponding Solr XML representation, needed for populating the index. In my case I have collected about 5130 files in a few minutes, but be warned that these numbers could change if you execute the process by yourselves, as they depend on queries over a remote repository.
Here we can follow the same approach used before. We will use the simple dbpediaToPost.sh Scala script that transforms the XML sources into the Solr format using a specific dbpediaToPost.xslt transformation style sheet. All we have to do is call the script:
>> createSolrDocs.sh
This script will produce the corresponding entity_name/solr_docs field for every entity_name/downloaded directory.
The script is rather simple, containing a line for every resource type. For example, for creating Solr documents for artists:
>>./dbpediaToPost.sh ../../../resources/dbpedia_artists/downloaded/ ../../../resources/dbpedia_artists/solr_docs/dbpediaToPost.xslt 'artists'
I don't want you to spend too much time on the programming details at the moment, but still I want you to notice that we are passing a parameter to the XSLT transformation sheet, that will be internally used by it to produce an entity_type field. For example, in the case of an artist the Solr document will contain:
<field name="entity_type">artists</field>
This will be very useful later, and please keep this field in mind while you start playing with the examples.
The most simple approach can be creating a separate index for every entity. First of all we need to create a core for every entity (I call them arts_paintings, arts_artists, arts_museums, and arts_subjects), using a default configuration. In this case we will use one for every core, more or less a copy of the configuration previously used in Chapter 6, Using Faceted Search – from Searching to Finding, so I will omit the details here, and I invite you to look at the provided source in details.
After we have Solr running (using the start.sh file at /SolrStarterBook/test/chp07/arts/), we will post the Solr documents to the cores with the script postCores.sh. Once the cores are populated, the first thing we want to test is a very simple multicore join query, similar to the example discussed in Chapter 5, Extending Search:
>> curl -X GET 'http://localhost:8983/solr/arts_paintings/select?q={!join%20from=city+to=city+fromIndex=arts_museums}dali&wt=json'
You don't need to expect very good performances when the index sizes increase, so I suggest you use it only when it's not possible to use another approach.