
In this section, we will introduce lowercase and character normalization during text analysis. Steps for defining he simple schema.xml file are as follows:
- We can now write a basic Solr
schema.xmlfile, introducing a field for tracking versions, and a newfieldTypewith basic analysis:<schema name="dbpedia_start" version="1.1"> <types> <fieldtype name="string" class="solr.StrField" /> <fieldType name="long" class="solr.TrieLongField" /> <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer> <charFilter class="solr.MappingCharFilterFactory"mapping="mapping-ISOLatin1Accent.txt"/> <tokenizer class="solr.StandardTokenizerFactory" /> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> </fieldType> </types> <fields> <field name="uri" type="string" indexed="true"stored="true" multiValued="false" required="true" /> <field name="_version_" type="long" indexed="true" stored="true" multiValued="false" /> <dynamicField name="*" type="string" multiValued="true" indexed="true" stored="true" /> <field name="fullText" type="text_general" indexed="true" stored="false" multiValued="true" /> <copyField source="*" dest="fullText" /> </fields> <defaultSearchField>fullText</defaultSearchField> <solrQueryParser defaultOperator="OR" /> <uniqueKey>uri</uniqueKey> </schema> - Even though this may seem complicated to read at the start, it is a simple schema that simply accepts every field we post to the core using the dynamic fields feature already seen before (http://wiki.apache.org/solr/SchemaXml#Dynamic_fields). We also copy every value into a
fullTextfield, where we have defined a basic text analysis with our new typetext_general.
The only field "statically" defined in this schema is the uri field, which is used to represent the original uri of the resource as a uniqueKey, and the _version_ fields, that we will analyze in a while. Note that in our particular case, every resource will have a specific unique uri, so we can avoid using a numeric id identifier without loosing consistency. For the moment, uri will be a textual value (string), and _version_ should be a numeric one (long) useful for tracking changes (also needed for the real-time get feature).
We have decided to define all the fields as indexed and stored for simplicity; we have explicitly decided that our dynamic fields should be multiValued and fullText, because they will receive all the values from every other field.
For the fullText field, we have defined a new specific type named text_general. Every user will perform searches using a combination of words, and our queries on the fullText field should be able to capture results using a single word or combination of words, and ignoring case for more flexibility. In short, the terms written by a user in the query will generally not be an exact match of the content in our fields, and we must start taking care of this in our fullText field.
If we want to define a customized fieldType, we should define a couple of analyzers in it: one for the indexing phase and the other for the querying phase. However, if we want them to act in the same way, we can simply define a single analyzer, as in our example.
An analyzer can be defined for a type using a specific custom component (such as <analyzer class="my.package.CustomAnalyzer"/>) or by assembling some more fine-grained components into an analyze chain, which is composed using three types of components, generally in the following order:
- Character Filter: There can be one or more character filters, and they are optional. This component is designed to preprocess input characters by adding, changing, or removing characters in their original text position. In our example, we use
MappingCharFilterFactory, which can be used to normalize characters with accents. An equivalent map for characters should be provided by a UTF-8 text file (in our case,mapping-ISOLatin1Accent.txt). - Tokenizer: It is mandatory, and there can be only one. This kind of component is used to split the original text content into several chunks, or tokens, according to a specific strategy. Because every analyze chain must define a tokenizer, the simplest tokenizer that can be used is
KeywordTokenizerFactory, it simply doesn't split the content, and produces only one token containing the original text value. We decided to useStandardTokenizerFactorythat is designed for a wider general use case and is able to produce tokens by splitting text using whitespaces and periods with whitespaces, and it's able to recognize (and not split) URL, email, and so on. - Token Filter: It can be one or more and is optional. Every
TokenFilterwill be applied to the token sequence generated by the precedingTokenizer. In our case, we use a filter designed to ignore the case on tokens. Note that most of the token filters have a correspondingTokenizerwith a similar behavior. The difference is only in where to perform tokenizations; that is, on the complete text value or on a single token. So the choice between choosing aTokenizeror aTokenFiltermostly depends on the other filters to be used in order to obtain the results we imagined for the searches we design.
There are many components that we could use; a nonexhaustive list of components can be consulted when configuring a new field at http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters.
We have defined a _version_ field, which can also take only a single value. This field is used to track changes in our data, adding version information. A version number for a modified document will be unique and greater than an old version. This field will be actually written by Solr itself when <updateLog/> is activated in the solrconfig.xml file. Because we need to obtain the last version values, we also need to have our version field to be stored.
I suggest you start using stored fields for your tests; this way, it's easy to examine them with alternative codecs, such as SimpletextCodec. Even if this will cost you some more space on disk, you can eventually evaluate whether a field needs to be stored during later stages of the incremental development.
Once we have defined the first version of our configuration files, we can index the example Mona Lisa entity we used earlier to think about the fields in our schema. First of all, we will play with the first version of the schema then later we will introduce other field definitions substituting the dynamic ones.
In the following examples, we will use the json format for simplicity. There are some minor changes in the structure between json and XML posts. Note that every cURL command should be written in one line even though I have formatted the json part as multiline for more readability.
Note
SON (http://www.json.org/) is a lightweight format designed for data interchange. The format was initially conceived for JavaScript applications, but it became widely used in substitution of the more verbose XML in several contexts for web applications. Solr supports json not only as the format for the response, but also performs operations such as adding new documents, deleting them, or optimizing the index.
Both XML and json are widely used on Internet applications and mashups, so I suggest you become familiar with both of them. XML is, in most cases, used for rigorous syntactic checks and validation over a schema in case of data exchange. Json is not a real metalanguage as XML, but it is used more, and more often for exposing data from simple web services (think about typical geo search or autocomplete widgets that interact with remote services) as well as for lightweight, fast-linked approach on the data.
Using JSON with cURL in these example can give you a good idea on how to interact with these services from your platform/languages. As an exercise, I suggest you play the same query using XML as the result format, because there are minor differences in the structure that you can easily study yourself:
- Clean the index. It's good, when possible, to have the ability to perform tests on a clear index.
>> curl 'http://localhost:8983/solr/paintings_start/update?commit=true' -H 'Content-type:application/json' -d ' { "delete" : { "query" : "*:*" } }'
- Add the example entity describing a painting.
>> curl 'http://localhost:8983/solr/paintings_start/update?commit=true&wt=json' -H 'Content-type:application/json' -d ' [ { "uri" : "http://en.wikipedia.org/wiki/Mona_Lisa", "title" : "Mona Lisa", "museum" : "unknown" } ]'
- Add the same painting with more fields.
>>curl 'http://localhost:8983/solr/paintings_start/update?commit=true&wt=json' -H 'Content-type:application/json' -d ' [ { "uri" : "http://en.wikipedia.org/wiki/Mona_Lisa", "title" : "Mona Lisa", "artist" : "Leonardo Da Vinci", "museum" : "Louvre" } ]'
- Find out what is on the index.
>>curl 'http://localhost:8983/solr/paintings_start/select?q=*:*&commit=true&wt=json' -H 'Content-type:application/json' - Please observe how the
_version_value changes while you play with the examples.
When Solr performs an update, generally the following steps are followed:
- Identifying the document by its unique key.
- Delete the unique key.
- Add the new version of the full document.
As you may expect, this process could produce a lot of fragmentation on the index structure ("holes" in the index structure) derived from the delete, and the delete and add operations over a very big index could take some time. It's then important to optimize indexes when possible, because an optimized index reduces the redundancy of segments on disk so that the queries on it should perform better.
Generally speaking, the time spent for adding a new document to an index is more than the time taken for its retrieval by a query, and this is especially true for very big indexes.
In particular context, when we want to perform a commit only after a certain number of documents have been added in the index, in order to reduce time for the rewriting or optimization process, we could look at the soft autocommit and near-realtime features. But for the moment, we don't need them.
The
atomic update is a particular kind of update introduced since Solr 4. The basic idea is to be able to perform the modification of a document without necessarily having to rewrite it. For this to be accomplished, we need the addition of a _version_ field, as we have seen before.
When using atomic updates, we need to define our fields to be stored, because the values are explicitly needed for the updates, but with the default update process we don't need this because the full document is deleted and readded with the new values. The copy-field destination, on the other hand, should not necessarily be defined as stored.
If you need some more information and examples, you can look in the official wiki documentation at http://wiki.apache.org/solr/Atomic_Updates.
The following simple schema, however, can help us visualize the process:
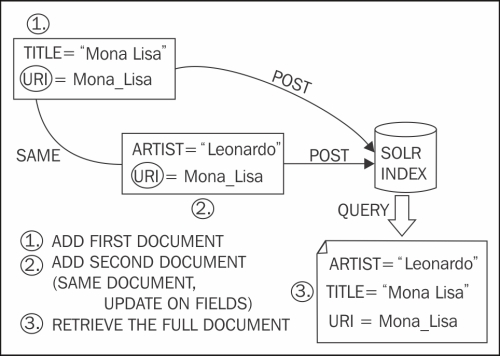
When performing an atomic update, we can also use the special attribute update on a per field basis. For example, in the XML format:
<add overwrite="true">
<doc>
<field name="uri">http://en.wikipedia.org/wiki/Mona_Lisa</field>
<field name="title" update="set">Mona Lisa (modified)</field>
<field name="revision" update="inc">1</field>
<field name="museum" update="set">Another Museum</field>
<field name="_version_" >1</field>
</doc>
</add>The corresponding json format has a slightly different structure:
[
{
"uri" : "http://en.wikipedia.org/wiki/Mona_Lisa",
"title" : {"set":"Mona Lisa (modified)"},
"revision" : {"inc":1},
"museum" : {"set":"Another Museum"},
"_version_" : 1
}
]The values for this attribute define the different actions to be performed over the document:
- set: It is used to set or replace a particular value or remove the value if null is specified as the new value. This is useful when updating a single value field.
- add: It adds an additional value to a list. This is useful for adding a new value to a multivalue field.
- inc: It increments a numeric value by a specific amount. This is a particular attribute useful for some fields defined to act as counters. For example, if we have defined a field for counting the number of times a specific document has been updated.
Tip
If you want to try posting these examples in the usual way (as seen in the previous examples), remember to add a revision field in the schema with the long type. When you have done this, you have to stop and restart the Solr instance; then, I suggest you take some time to play with the examples, changing data and posting it multiple times to Solr in order to see what happens.
The _version_ value is handled by Solr itself and when passed, it generates a different behavior for managing updates, as we will see in the next section.
Another interesting approach to use when updating a document is optimistic concurrency, which is basically an atomic update in which we provide the _version_ value for a field. For this to work, we first need to retrieve the _version_ value for the document we want to update, then if we pass the retrieved version value to the update process, the document will be updated as it exists. For more info please refer:
http://wiki.apache.org/solr/Atomic_Updates
If we provide a nonexistent value, it will be used with the following semantics:
|
_version_ value |
Semantics |
|---|---|
|
>1 |
The document version must match exactly |
|
1 |
The document exists |
|
<0 |
The document does not exist |
If we guess the current _version_ value for performing updates on a certain specific document, we only have to make a query for the document (for example, by uri):
>> curl -X GET 'http://localhost:8983/solr/paintings_start/select?q=uri:http://en.wikipedia.org/wiki/Mona_Lisa&fl=_version_&wt=json&indent=true'
Retrieve the _version_, and then construct the data to be posted. In this example, we have also anticipated the fl (fields list) parameter, which we will see in the next chapter.