
One of the first things to think when configuring a Solr core are the kind of searches we are interested in. It could seem trivial, but is not since every field in our schema definition typically needs a good and specific configuration.
The basic searches we want to perform are probably as follows (consider this just as a start):
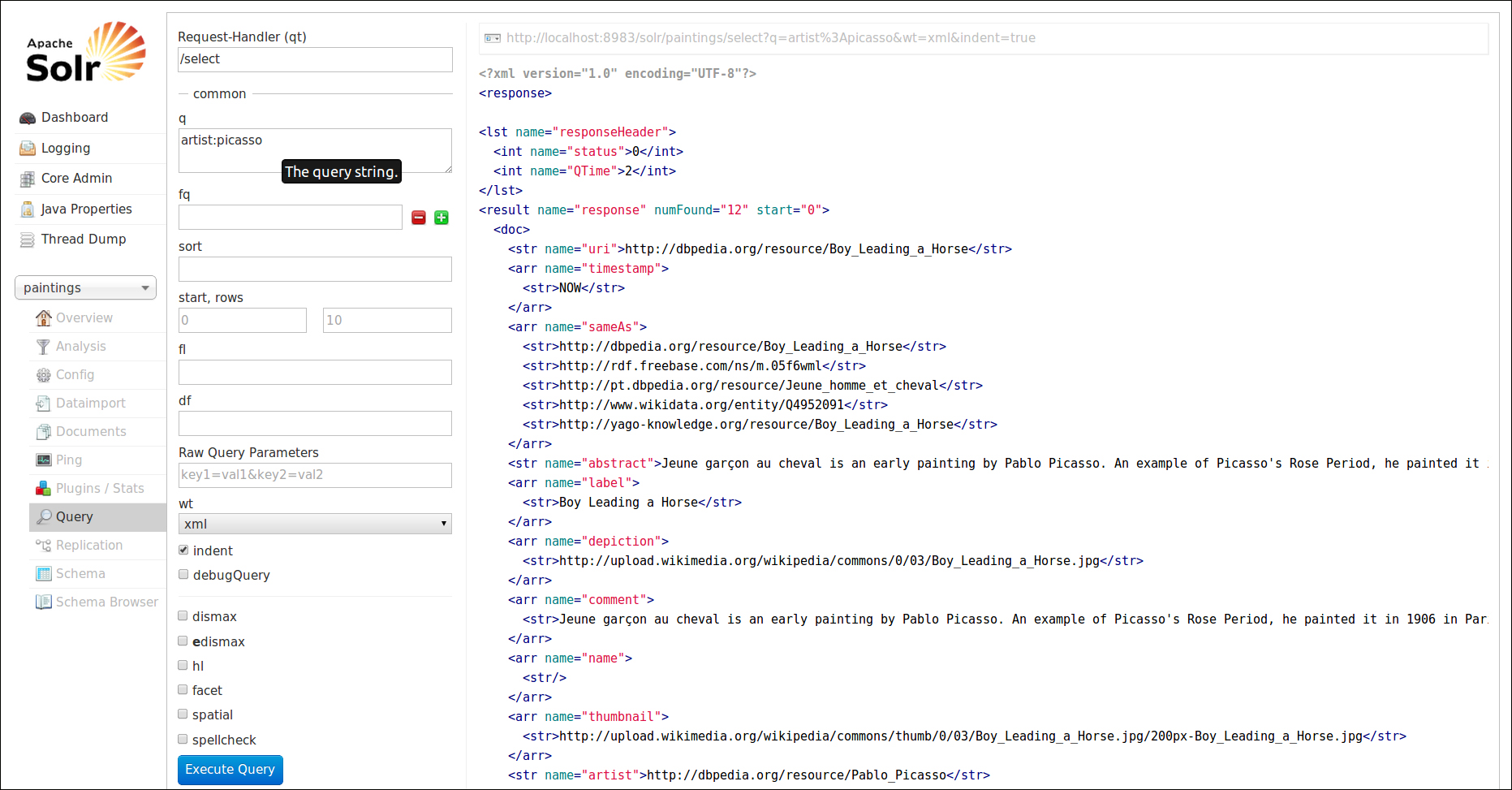
The first search is the most simple one. We only search in the artist field for an artist with a name containing the term picasso. The result format chosen is XML.
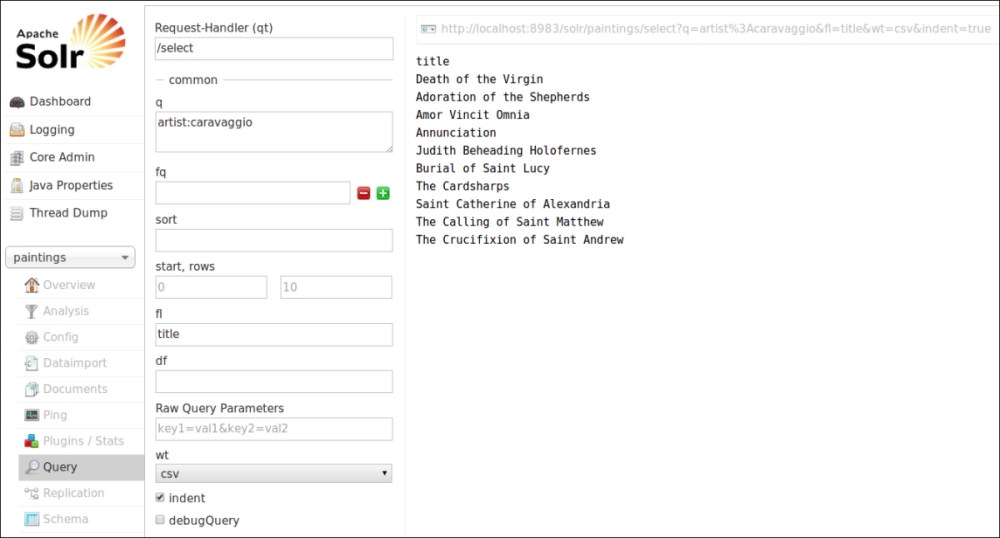
In the second search, we want to use the CSV response format seen before and yet we play with the fields list (fl) parameter, which is designed to choose which fields' projection to include in the results. In our example, we want only a list of titles in plain text, so we use wt="CSV" and fl="title".
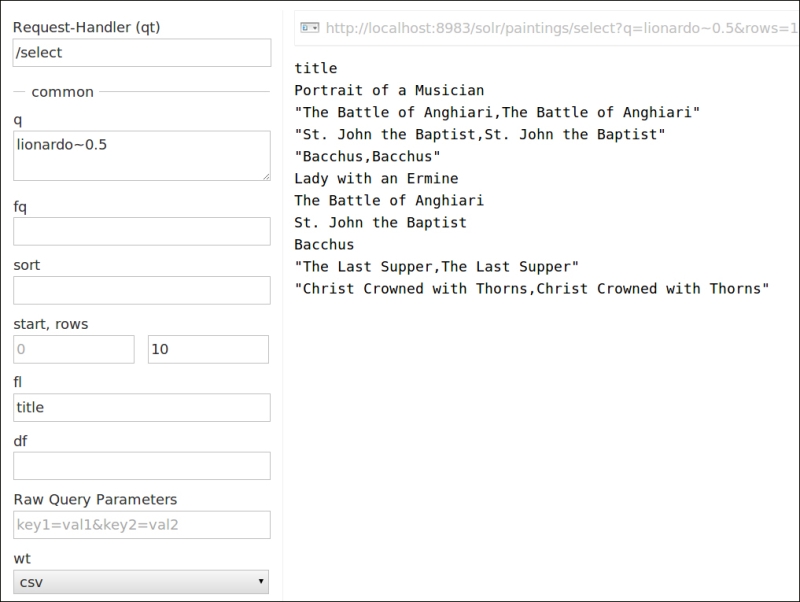
In the last search, we play with a simple anticipation of fuzzy search, which we will see in Chapter 4, Searching the Example Data. The query for artist:lionardo~0.5 permits us to search for a misspelled name, which is a typical case when searching for a name in a foreign language.
At last, it's important to remember that the web interface could be used to have a visual outline of the Solr instances that are now running. In our examples, we are often trying to use some basic command line tool because it permits us to pay attention on what is happening during a particular task. In the web interface, on the other hand, it's quite useful to have a general view of the overall system. For example, the dashboard gives us a visual overview of the memory used, version installed, and so on as shown in the following screenshot:
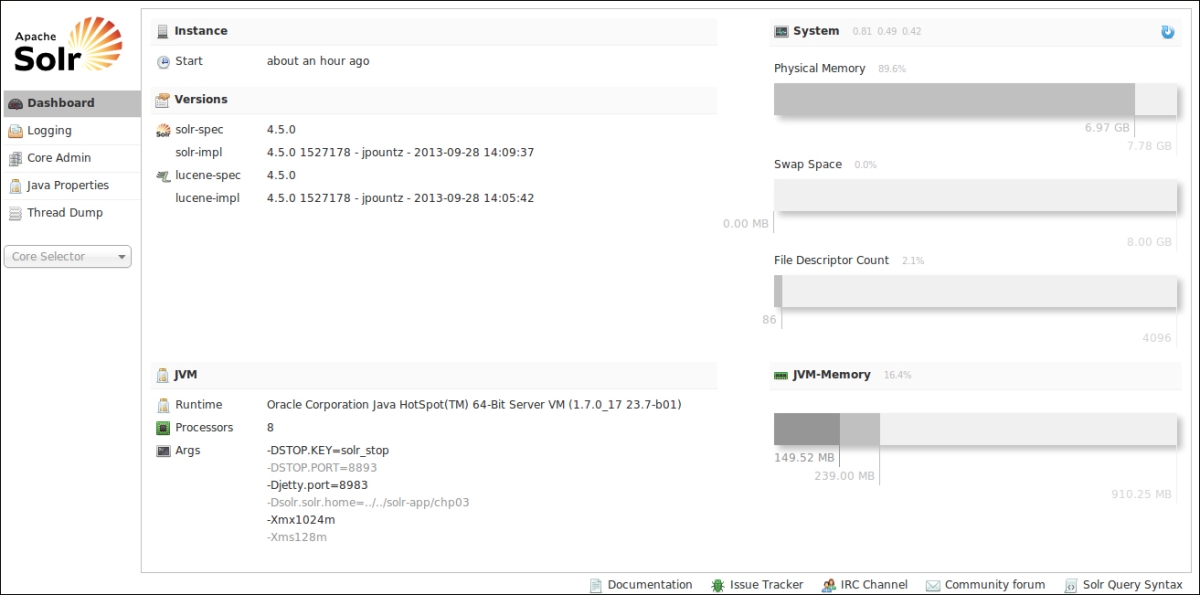
The web interface has greatly evolved from the previous versions. Now, it is much more like a frontend to the services provided by the server; we can use the same directly from our language or tool of choice, for example, with cURL, again.
For example, we could easily perform an optimization by selecting a core on the left, and then just clicking the optimize now button. You can see that there are two icons informing us about the state of the index and whether it needs to be optimized or not.
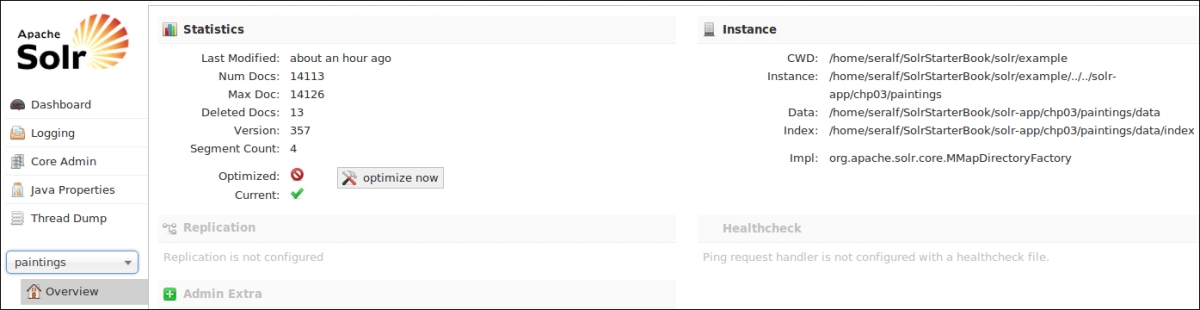
Just to give you an idea, the optimization process is very important when we need to upgrade from the previous Solr index constructed before the version 4.x. This is because Solr 3 indexes are different from the Solr 4 branch but can be loaded from the last distribution if updated with a Solr 3.6 version and, obviously, if the fields defined are compatible. That said, a little trick for such an update process is to update the old Solr instance to the last of the Solr 3 branch, perform an optimization on the indexes (so that they are overwritten with a compatible structure for Solr 4), and then move to Solr 4.
Using the Core Admin menu item on the left in the web interface, we can also see an overview page for every core as shown in the following screenshot:
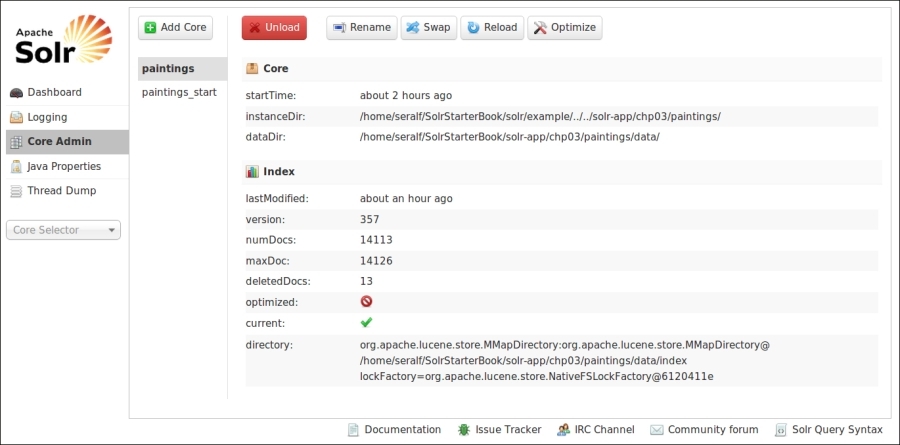
In this case, we could not only request for an optimization, but also for loading/unloading cores or swapping them to perform administration tasks.
We can expect the interface to add more functionality and flexibility in the next version, responding to the requests of the community, so the best option is to follow the updates from version to version.
Q1. What is the purpose of an autoCommit configuration?
- It can be used to post a large amount of documents to a Solr index.
- It can be used to automatically commit the change to a certain amount of documents.
- It can be used to automatically commit changes to documents after a certain amount of time.
Q2. What is the main difference between a char filter and a token filter?
- Using a char filter is mandatory, while using a token filter is not.
- A token filter is used on an entire token (a chunk of text), while a char filter is used on every character.
- There can be more than a single char filter but only a single token filter can be used.
Q3. What does a tokenizer do?
- A tokenizer is used to split text into a sequence of characters.
- A tokenizer is used to split text into a sequence of words.
- A tokenizer is used to split text into a sequence of chunks (tokens).
Q4. In what contexts will an atomic update be useful?
- When we want to perform a single update.
- When we want to update a single document.
- When we want to update a single field for a document.