
4.2. The Relation Between Uncertainty and Granularity
Uncertainty originates in the lack of knowledge mainly. There are several kinds of uncertainty. All can be treated by quotient space model uniformly.
(1). Measurement Uncertainty
We say, ‘His age is in the twenties’, ‘The length of the rope is about fifty meters’. Neither of the two statements is precise, since ‘twenties’ and ‘about fifty meters’ are not definite numbers. In daily life, we use these kinds of imprecise description widely. Now that much information we deal with is usually imprecise, what is the distinction between certainty (accuracy) and uncertainty (inaccuracy)?
Taking the ‘length of a rope’ as an example, we say, ‘The length of the rope is about fifty meters’. Whether the statement is precise or not depends on the yardstick we use. If the yardstick we use is coarse, for example, taking ‘ten meters’ as a minimal measure unit, then ‘five’ is a precise number in the statement. When the yardstick is refined, for example, taking ‘centimeter’ as a measure unit, the same ‘five’ in ‘five thousand centimeters’ will be imprecise. In other words, as viewed from a low (fine) level, some information is imprecise. While viewed from a high (coarse) level, the same information may be precise. Therefore, whether the information is accurate or not depends on what abstraction level is thought about.
(2). Incomplete Knowledge
In a complex environment, it is hard to get complete information about a world. However, in what condition can sufficient information be obtained? For example, we have a map of nation-wide railway traffic. In the map, Shanghai City is just a point, if viewed for city bus route, there is no information at all. But the map is enough for investigating nation-wide railway transportation. Whether the map is completed or not also depends on the goal and level we are interested in. The information which is incomplete in some fine level may be complete and enough in some coarse level. Conversely, the information which is complete in low level may be redundant in high level. For example, in a map of nation-wide railway traffic, there is no need to depict the details within Shanghai City.
(3). Fuzzy Information
In daily life, people use fuzzy concepts extensively. They are not puzzled by these concepts. We say, ‘Someone is young’, ‘It is cloudy, today’, etc. ‘Young’ and ‘cloudy’, etc. are generally considered to be fuzzy concepts. Are they really fuzzy? It depends on in what abstraction level we use the information. If we use the concepts of ‘young’ and ‘old’ to depict the age of a certain person, certainly, they are ‘fuzzy’. If the concepts are only used for describing the characteristics of different groups of people, they are clear and definite.
Given three concepts, for example youngsters, middle-aged persons and old men, denoted by a, b, and c, respectively. We have a domain 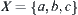 . The order is assumed to be a<b<c. If f(x) is an attribute function on a, b and c, we finally have a problem space (X, f, T).
. The order is assumed to be a<b<c. If f(x) is an attribute function on a, b and c, we finally have a problem space (X, f, T).
In the domain 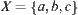 , youngsters, middle-aged persons and old men are clearly distinguishable elements. Each has its own characteristic. For example, f(a)={ardent, full of vim and vigor,…}, f(b)={experienced, mature,…}, etc. The order relation among elements a, b and c, i.e., youngsters < middle-aged persons < old men, is domain-independent. But the relationship between these concepts and age is domain-dependent. For example, a sportsman who is only thirty years old may not be ‘young’, but an old man who is sixty years old is still ‘young’ in a senior citizen community. Conversely, for two sportsmen, so long as one is younger than the other, the age-relation between them, i.e., the former (age) < the latter, remains the same regardless of their real ages. The same is true of two persons in a senior citizen community. It implies that fuzziness occurs only when these concepts are transformed into the fine level-age level.
, youngsters, middle-aged persons and old men are clearly distinguishable elements. Each has its own characteristic. For example, f(a)={ardent, full of vim and vigor,…}, f(b)={experienced, mature,…}, etc. The order relation among elements a, b and c, i.e., youngsters < middle-aged persons < old men, is domain-independent. But the relationship between these concepts and age is domain-dependent. For example, a sportsman who is only thirty years old may not be ‘young’, but an old man who is sixty years old is still ‘young’ in a senior citizen community. Conversely, for two sportsmen, so long as one is younger than the other, the age-relation between them, i.e., the former (age) < the latter, remains the same regardless of their real ages. The same is true of two persons in a senior citizen community. It implies that fuzziness occurs only when these concepts are transformed into the fine level-age level.
Therefore, a fuzzy concept may not necessarily be described by a membership function on its original domain. It can be represented in some quotient space. The same is true of uncertain and incomplete information.
Assume that 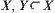 is a domain and for
is a domain and for 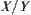 its attribute function
its attribute function 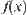 is unknown, i.e., function
is unknown, i.e., function 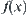 is only defined on Y. Then, for
is only defined on Y. Then, for 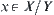 ,
, 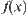 is undefined temporarily, whenever new information is gathered, it might be defined. We can still implement some operation on
is undefined temporarily, whenever new information is gathered, it might be defined. We can still implement some operation on 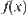 . For example, by the projection operation, we may have attribute function
. For example, by the projection operation, we may have attribute function 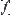 of
of 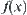 on its quotient space
on its quotient space 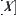 , regardless of whether
, regardless of whether 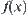 has been defined completely or not. Sometime, in the reasoning process, it’s needed to know the value of
has been defined completely or not. Sometime, in the reasoning process, it’s needed to know the value of 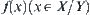 . We may adopt the mean of
. We may adopt the mean of 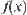 as its default value temporarily. If the default assumption is violated by new observation, then we may make a proper modification. This is just the basis of default reasoning. Thus, our hierarchical model can be used for representing different kinds of uncertainty.
as its default value temporarily. If the default assumption is violated by new observation, then we may make a proper modification. This is just the basis of default reasoning. Thus, our hierarchical model can be used for representing different kinds of uncertainty.
In summary, we make the following assumptions.
Uncertainty Assumption
For some uncertain information A, there exists an abstraction level X1 such that A is certain on that level. Conversely, some information A which is certain on level X1 may be uncertain on a finer grained level X2 to some degree.
From the analysis, it is known that certainty and uncertainty or fuzzy and crisp are relative. They are contrasted with different grain-sizes of the world. So in our reasoning model, uncertain information is represented by different grain-size worlds.
Besides uncertain information, the causal relations may also be uncertain in the reasoning process. We’ll use probabilistic tool for representing these kinds of uncertainty.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.