
Finally, we can create an example involving more than a single data source. We will use the Open Data of the well-known Tate Gallery (http://www.tate.org.uk/), recently released with GitHub in different formats (https://github.com/tategallery/collection).
- The first thing we will need at the start is the CSV file containing metadata about the artists in the repository: https://github.com/tategallery/collection/blob/master/artist_data.csv.
- We will augment those metadata with information from DBpedia. We will use just the essentials to keep the example simple; but you can easily add more fields for an exercise. We will define a new Tate core (in
/SolrStarterBook/solr-app/chp08/) using the same configuration from the previous examples for theschema.xml and solrconfig.xmlfiles. - In
solrconfig.xml, we can add the usual import using one of the following configurations:<lib dir="../../../solr/dist/" regex="solr-dataimporthandler-.*.jar" /> <lib dir="${SOLR_DIST}/../dist/" regex="solr-dataimporthandler-.*.jar" /> - Then, we can consider adding a
propertyWriterconfiguration to customize the format used to save the last indexing time.<propertyWriter type="SimplePropertiesWriter" dateFormat="yyyy-MM-dd HH:mm:ss" locale="en_US" directory="data" filename="dih_tate.properties" />
- The last step will be writing the specific
DIH.xmlfile for this example:<dataConfig> <script><![CDATA[ function fixCSV(row) { var line_fixed = row.get('rawLine') .replaceAll(",\s+","::::").replaceAll(",",";") .replaceAll("::::",",").replaceAll(""(.*?)"","$1"); row.put('rawLine_fixed', line_fixed); java.lang.System.out.println("#### FIXED: "+line_fixed+" "); return row; } function console(row) { java.lang.System.out.println("#### ROWS: "+row.keySet()+" "); return row; } var id = 1; function GenerateId(row) { row.put('id', (id ++).toFixed()); return row; } ]]></script> <dataSource name="source_url" type="URLDataSource" baseUrl="https://raw.github.com" encoding="UTF-8" connectionTimeout="5000" readTimeout="10000" /> <document> <entity name="artist" processor="LineEntityProcessor" url="/tategallery/collection/master/artist_data.csv" stream="true" dataSource="source_url" onError="skip" newerThan="${dataimporter.last_index_time}" transformer="TemplateTransformer, script:fixCSV, RegexTransformer, script:console"> <field column="rawLine_fixed" regex="^(.*);(.*);(.*);(.*);(.*);(.*);(.*);(.*);(.*)$" groupNames="id,name,gender, dates, yearOfBirth, yearOfDeath, placeOfBirth, placeOfDeath,url" /> <field column="url" name="uri" /> <field column="doc_type" template="artist" /> <entity name="dbpedia_lookup" processor="XPathEntityProcessor" stream="true" forEach="/ArrayOfResult/Result" onError="skip" rootEntity="true" url="http://lookup.dbpedia.org/api/search.asmx/KeywordSearch?QueryString=${artist.name}" transformer="script:console" > <field column="dbpedia_uri" xpath="/ArrayOfResult/Result/URI" commonField="true" /> <field column="dbpedia_description" xpath="/ArrayOfResult/Result/Description" commonField="true" /> <field column="doc_type" template="dbpedia_lookup" /> </entity> </entity> </document> </dataConfig> - Once the core configuration is ready, we can start the data import process directly from the web interface, as in the previous examples. The process will index the metadata for every artist, adding information from DBpedia when they can be retrieved. Looking at the upper part of the following screenshot we can see how the original data looks, and in the lower part we can see how the data will be expanded for this simple example.
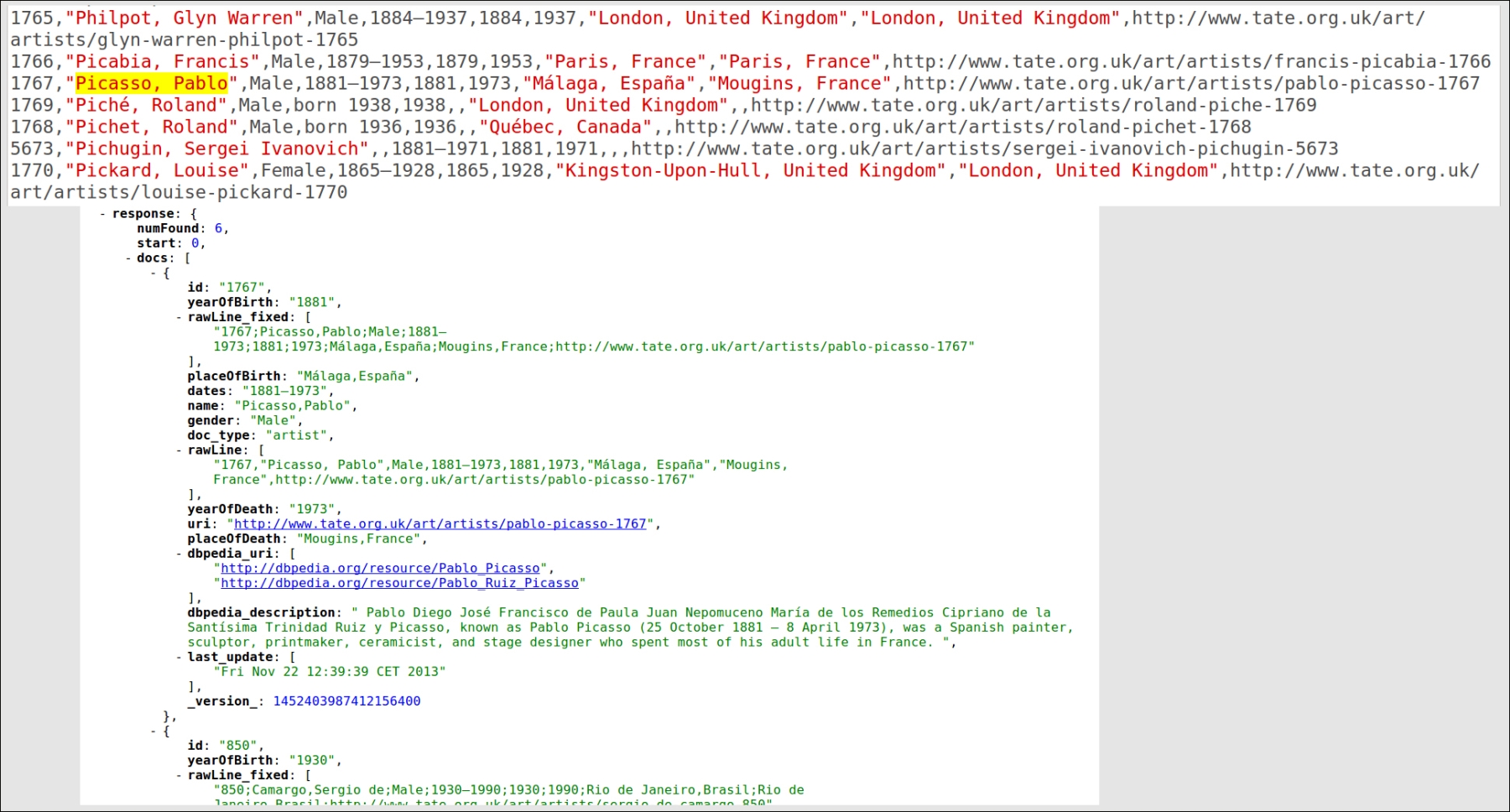
In my case, the full import requires about 10 minutes, but this time can vary depending on your computer and network.
First of all, we will define as usual the import of the library JAR needed. In this case, I will write two different configurations that can be used for this. The ${SOLR_DIST} variable, in particular, acts as the placeholder for the value of a corresponding environment variable passed during the Solr startup just as in Java DSOLR_DIST=$SOLR_DIST -Dsolr.solr.home=/path/to/solr/home/ -jar start.jar.
The propertyWriter configuration is useful because it can be used to customize the format of the temporal mark saved for tracking the last index/update operation. These customizations permit us to define a specific date format of our choice (but I suggest you to adopt the standard format, yyyy-MM-dd HH:mm:ss unless you have very specific motivation), and change the data directory where to update the property file, or simply the name of this file.
As we already saw, the example includes a script part where the JavaScript syntax is encapsulated using the CDATA part in order to avoid breaking the XML validity. In the scripts, we can sanitize the format of a single CSV row; while the other functions are similar to previous examples.
This example will use two entities: the first representing metadata for a resource from the Tate source, the second representing data from DBpedia about a specific resource. While we read data from the first entity, we will be able to look up on DBpedia and finally construct a single Solr document. From this point of view, the entity artist is the primary entity in this example. We will start by reading the CSV file from an URLDataSource data source, then we will index one artist at a time, using a LineEntityProcessor. Note that the data is not stored on the local machine. Using different transformers, we will fix the data format (saving the results in rawLine_fixed), and finally split the single rawLine_fixed parameter into multiple fields. During the indexing phase, it's possible to take the ${artist.name} parameter emitted by the first entity and use the value for a lookup on the DBpedia API. If a corresponding page is found, we will use XPath to extract data and add it to our original document. At the end of this process, we will be able to intercept user queries containing terms that are not in the original metadata, because we would have indexed our examples on the fields added from DBpedia too.
I suggest you to read the following articles that would help you to have a broader idea of the adoptions of the DataImportHandler and the related components for real-world situations:
- Refer to the article at http://solr.pl/en/2010/10/11/data-import-handler-%E2%80%93-how-to-import-data-from-sql-databases-part-1/
- Refer to the article at http://docs.lucidworks.com/display/lweug/Indexing+Binary+Data+Stored+in+a+Database
- Refer to the article at http://searchhub.org/2013/06/27/poor-mans-entity-extraction-with-solr/
Q1. What is the DataImportHandler?
- The DIH is a library of components which can be used to index data from external data sources.
- The DIH is a component which can be used to index data from external data sources.
- The DIH is a library of components which can be used to index data from external Solr installation.
Q2. Is DIH a way to replace a direct HTTP posting of documents?
- Yes, the
DataImportHandleris used to index documents without using the HTTP posting. - No, as the
DataImportHandlerinternally posts the data via HTTP posting.
Q3. What is the relationship between entities in DIH and a Solr index?
- An entity in DIH is used as a collection of fields. These fields can be indexed on a compatible Solr schema. The Solr schema must explicitly define the entities handled by DIH.
- An entity in DIH is the collection of fields defined by the corresponding Solr schema for a core.
- An entity in DIH is used as a collection of fields. These fields can be indexed on a compatible Solr schema. However the Solr schema does not explicitly define the entities handled by DIH.
Q4. What are the data formats emitted by a DIH processor?
- Every DIH emits the same standard Solr format.
- Every DIH emits a single row which is internally handled as an HashMap, where the key/value pairs represent the fields used in the specific core.
- Every DIH emits a stream of rows, one by one, which is internally handled as an HashMap, where the key/value pairs represent the fields used in the specific core.
Q5. Does the DIH provide an internal way to schedule tasks?
- No, at the moment it should be programmed with a specific component, or using a schedule tool invoking the delta-import command.
- Yes, using the delta-import command it's possible to also provide the time for the next start of the indexing process.