
Solr is a very powerful, flexible, mature technology, and it offers not only powerful full-text search capabilities but also autosuggestion, advanced filtering, geocoded search, highlighting in text, faceted search, and much more. The following are the most interesting ones from our perspective:
- Advanced full-text search: This is the most obvious option. If we need to create some kind of an internal search engine on our site or application, or if we want to have more flexibility than the internal search capabilities of our database, Solr is the best choice. Solr is designed to perform fast searches and also to give us some flexibility on terms that are useful to intercept a natural user search, as we will see later. We can also combine our search with out of the box functionalities to perform searches over value intervals (imagine a search for a certain period in time), or by using geocoding functions.
- Suggestions: Solr has components for creating autosuggestion results using internal similarity algorithms. This is useful because autosuggestion is one of the most intuitive user interface patterns; for example, think about the well-known Google search box that is shown in the following screenshot:
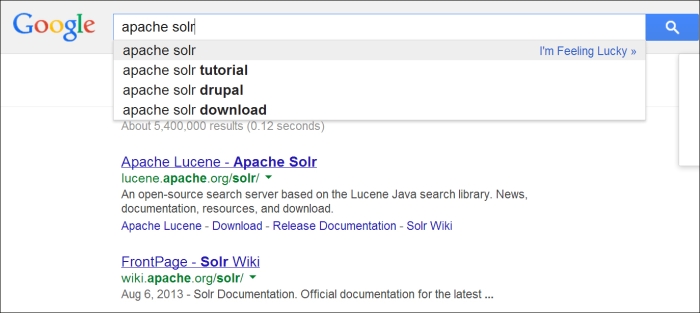
This simple Google search box performs queries on a remote server while we are typing, and automatically shows us some alternative term sequence that can be used for a query and has a chance to be relevant for us; it uses recurring terms and similarity algorithms over the data for this purpose. In the example, the
tutorialkeyword is suggested before thedrupalone as it is judged more relevant from the system. With Solr, we can provide the backend service for developing our own autosuggestion component, inspired by this example. - Language analysis: Solr permits us to configure different types of language analysis even on a per-field basis, with the possibility to configure them specifically for a certain language. Moreover, integrations with tools such as Apache UIMA for metadata extraction already exist; and in general, you might have more new components so that you will be able to plug in to the architecture in the future, covering advanced language processing, information extraction capabilities, and other specific tasks.
- Faceted search: This is a particular type of search based on classification. With Solr, we can perform faceted search automatically over our fields to gain information such as how many documents have the value
Londonfor thecityfield. This is useful to construct some kind of faceted navigation. This is another very familiar pattern in user experience that you probably know from having used it on e-commerce site such as Amazon. To see an example of faceted navigation, imagine a search on the Amazon site where we are typingapache s, as shown in the following screenshot: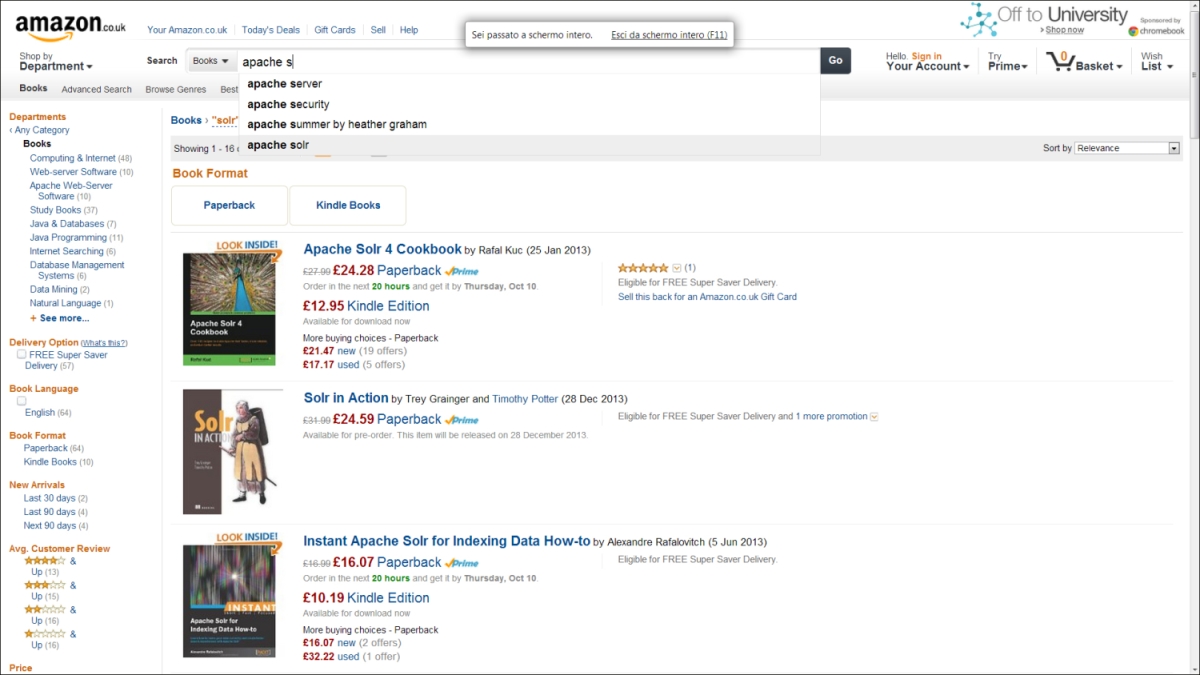
- In the previous screenshot you can clearly recognize some facets on the top-left corner, which is suggesting that we will find a certain number of items under a certain specific "book category". For example, we know in advance that we will find 11 items for the facet "Books: Java Programming". Then, we can decide from this information whether to narrow our search or not. In case we click on the facet, a new query will be performed, adding a filter based on the choice we implicitly made. This is exactly the way a Solr faceted search will perform a similar query. The term category here is somewhat misleading, as it seems to suggest a predefined taxonomy. But with Solr we can also obtain facets on our fields without explicitly classifying the document under a certain category. It's indeed Solr that automatically returns the faceted result using the current search keywords and criteria and shows us how many documents have the same value for a certain field. You may note that we have used an example of a user interface to give an introductory explanation for the service behind. This is true, and we can use faceted results in many different ways, as we will see later in the book. But I feel the example should help you to fix the first idea; we will explore this in Chapter 6, Using Faceted Search – from Searching to Finding.
It's easy to index data using Solr: for example, we can send data using a POST over HTTP, or we can index the text and metadata over a collection of rich documents (such as PDF, Word, or HTML) without too much effort, using the Apache Tika component. We can also read data from a database or another external data source, and configure an internal workflow to directly index them if needed—using the
DataImportHandlercomponents.Solr also exposes its own search services that are REST-like on standard open formats such as JSON and XML, and it's then very simple to consume the data from JavaScript on HTTP.
Note
Representational State Transfer (REST) is a software architecture style that is largely used nowadays for exposing web services.
Refer to: http://en.wikipedia.org/wiki/Representational_state_transfer
- The services are designed to be paginated, and to expose parameters for sorting and filtering results; so it's easy to consume the results from the frontend.
- Note that other serialization formats can be used; which are designed for specific languages, such as Ruby or PHP, or to directly return the serialization of a Java object. There are already some third-party wrappers developed over these services to provide integration on existing applications, from Content Management Systems (CMS) such as Drupal, WordPress, to e-commerce platforms such as Magento. In a similar way, there are integrations that use the Java APIs, such as Alfresco and Broadleaf, directly (if you prefer you can see this as a type of "embedded" example).
It's possible to start Solr with a very small configuration, adopting an almost schemaless approach; but the internal schema is written in XML, and it is simple to read and write. The Solr application gives us a default web interface for administration, simple monitoring of the used resources, and direct testing of our queries.
This list is far from being exhaustive, and it had the purpose of only introducing you to some of the topics that we will see in the next chapters. If you visit the official site at http://lucene.apache.org/solr/features.html, you will find the complete list of features.