
When performing a query, we need to remember we are potentially asking for a huge number of documents. Let's observe how to manage partial results using pagination:
- For example, think about the
q=*:*query that we saw in previous examples. it was used for asking all the documents, without a specific criteria. In a case like this, in order to avoid problems with resources, Solr will actually send us only the first results, as defined by a parameter in the configuration. The default number of returned results will be10. So, we need to be able to ask for a second group of results, a third, and so on and on. This is what is generally called a pagination of results, similarly as for scenarios involving SQL. - The command is executed as follows:
>> curl -X GET "http://localhost:8983/solr/paintings/select?q=*:*&start=0&rows=0&wt=json&indent=true" - We should obtain a result similar to the following screenshot. The number of documents
numFoundand the time spent for processing queryQTimecould vary, depending on your data and the system you are using: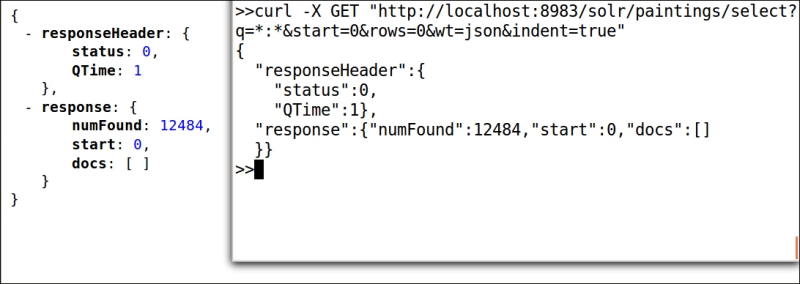
In the previous screenshot, we see the same results in two different ways: on the right-hand side you'll recognize the output from cURL, and on the left-hand side of the browser you see how the results appear in the browser window.
Tip
In the first example, we had the Json View plugin installed in the browser. This gave a very helpful visualization of json with indentation and colors. You can install it for Chrome if you want by using the following link:
https://chrome.google.com/webstore/detail/jsonview/chklaanhfefbnpoihckbnefhakgolnmc
For Firefox, the plugin can be installed from:
Notice how even if we have found 12,484 documents, we are currently seeing none of them in the results!
In the previous example, we already use two very useful parameters: start and rows. We should always think of them as a couple, even if we may be using only one of them explicitly. We could change the default values for these parameters from the solrconfig.xml file, but this is generally not needed. The following takes place in the previous example:
- From the documents matching our search criteria, the start value defines the original index of the first document returned in the response, starting from the value 0. The default value will again start at 0.
- The rows parameter is used to define how many documents we want in the results. The default value will be 10 for rows.
So, for example, if we only want the second and third document from the results, we can obtain them using the query:
>> curl -X GET "http://localhost:8983/solr/paintings/select?q=*:*&start=1&rows=2&wt=json&indent=true'
In order to obtain the second document in the results, we need to remember that the enumeration starts from 0 (so the second will be at 1); while to see the next group of documents (if present), we will send a new query with values such as start=10 and rows=10. We are still using wt and indent parameters only to have results formatted in a clear way.
This process of segmenting the output to be able to read it in group or pages of results is usually named pagination , and it is generally handled by some programming code. You should know this mechanism so that you can play with your test even on a small segment of data, without any loss of generalization. I strongly suggest you always add these two parameters explicitly in your examples.