
An example of an interesting alternative is the XSLT Response Writer. For instance, we could use the one designed to enable XSLT processing over the XML responses.
- To do this, first of all we define a new core that we will name
paintings_xslt. In its ownsolrconfig.xmlfile, we will add a simple new definition:<queryResponseWriter name="xslt" class="solr.XSLTResponseWriter"> <int name="xsltCacheLifetimeSeconds">0</int> </queryResponseWriter>
- Once we have enabled it, we can use an
XSLTfile. For this, we could use a copy of theluke.xslfile provided in the default Solr examples. - Now we can ask for the Luke analysis:
>> curl -X GET 'http://localhost:8983/solr/paintings_xslt/admin/luke?q=*:*&wt=xslt&tr=luke.xsl' - Obtaining the output shown in the following image:
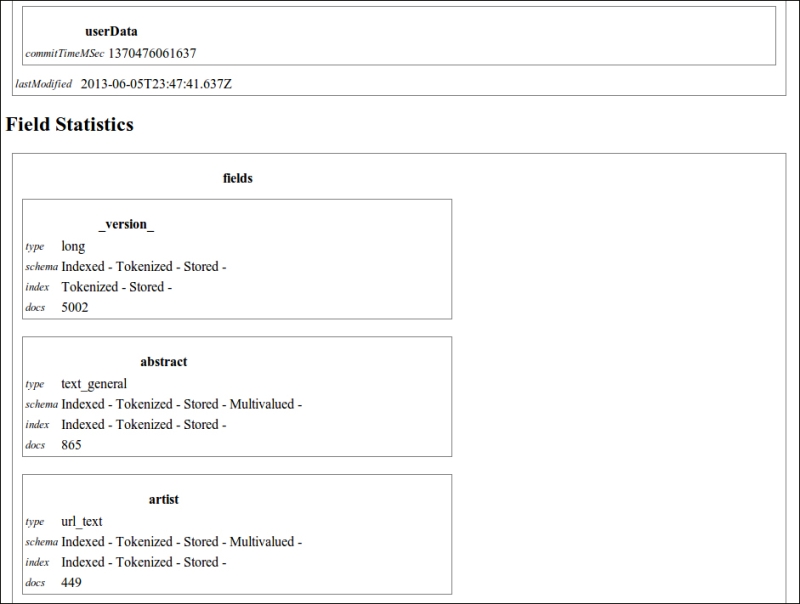
As you see, the output is more readable in this case. It can be used and improved to create a sort of report and help us in the analysis phase. However, the XSLT processor is good for testing, but it's not the best choice for a production environment. It's much more flexible and simple to scale on using JavaScript or other languages from the client-side to consume services.
Now that the Luke Request Handler is enabled, we can easily call it to obtain a simple formatted analysis of the fields in use in our index by using the following command:
>> curl -X GET 'http://localhost:8983/solr/paintings_xslt/admin/luke?q=*:*&wt=xslt&tr=luke.xsl'
Notice that the parameter wt=xslt tells Solr to use this Response Writer, and the tr=luke.xsl parameter is used to retrieve the XSLT file from the conf directory of the core itself.
Tip
Another very good source of information for field analysis can be obtained from the FieldAnalysisRequestHandler, but it is a bit more complex to read. Refer to it at: http://lucene.apache.org/solr/4_5_0/solr-core/org/apache/solr/handler/FieldAnalysisRequestHandler.html.
Sometimes it's useful to obtain a list of the available field, and this is very simple to obtain if we use the CSV output format:
>> curl -X GET 'http://localhost:8983/solr/paintings/schema?wt=csv'
In this way, we obtain a simple plain text result. In this case, it will be a single row text containing a simple list of field names divided by commas.
On the other hand, we can always obtain details about specific fields—not only name but datatypes, specific schema attributes, and others:
>> curl -X GET 'http://localhost:8983/solr/paintings/schema/fieldtypes?wt=json' >> curl -X GET 'http://localhost:8983/solr/paintings/schema/fields' >> curl -X GET 'http://localhost:8983/solr/paintings/schema/dynamicfields' >> curl -X GET 'http://localhost:8983/solr/paintings/schema/copyfields'
I suggest you play with these simple services on your example as they can be useful in the development phase, depending on your needs.
Combining some of the latter options exposed till now, it's very simple to expose our results using two formats that are very useful in the context of Open Data integration.
Reading the widely known definition of Open Data from Wikipedia:
"Open data is the idea that certain data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control".
Note
If you are interested on the Open Data movement, please read more at:
Let's look at two simple recipes that can be used to expose Solr results directly in formats widely adopted in the Open Data context. While it is generally not a good idea to expose Solr results directly, these methods can be useful in some specific context as they are very easy to use.
First of all, we could easily expose the data in CSV format:
>> curl -X GET 'http://localhost:8983/solr/paintings/select?q=*:*&wt=csv&csv.mv.separator=|'
Notice that we have not only specified wt=csv, but also csv.mv.separator=| that stands to define the character | as a separator for values in multivalued fields.
A second, interesting option, will be constructing an RSS feed over our data:
>> curl -X GET 'http://localhost:8983/solr/paintings/select?q=artist:Dal%C3%AC&wt=xslt&tr=rss.xsl'
For example, here we have created a feed for searches of Dalì so that if new document were added to the index, they will be shown in the results. We could also use the timestamp field here if we want.
Notice that in this way we could define several RSS feeds, one for every kind of search we want to define. For the XSLT manipulation, we are using a slightly customized version of the original rss.xsl from the default Solr examples.
Finally, I'd like to strongly suggest you to do some reading on a few good resources to obtain a different point of view of understanding Solr Query Syntax:
Q1. For what are the parameters start, rows used?
- Pagination: request results from
starttostart+rows - Pagination: request results from
starttorows - Selecting results which has an index greater than
startvalue, but no more thanrowstimes
Q2. Is it possible to perform searches over misspelled terms?
- Yes, with fuzzy search
- Yes, with wildcard (
*) search - Yes, with phrase search
Q3. Can we use more than one search handler in Solr?
- Yes
- No
Q4. What is a Boolean query?
- A query which uses only Boolean values
- A query which returns only true/false results
- A query which uses Boolean operators
Q5. Is it possible to perform searches over incomplete terms?
- Yes, with fuzzy search
- Yes, with wildcard (
*) search - Yes, with phrase search
Q6. In what scenarios would it be useful to handle phrase searches?
- When a user wants to search over a specific sequence of terms, including putting it in double quotes
- When a user is searching for an exact phrase match
- When we need to search for multiple words at the same time