
Chapter 11
Distribution System Reliability
Mind moves matter.
Virgil
What is mind? No matter. What is matter? Never mind.
Thomas H. Key
If a man said ‘all mean are liars’, would you believe him?
Author Unknown
11.1 Basic Definitions
Most of the following definitions of terms for reporting and analyzing outages of electrical distribution facilities and interruptions are taken from Ref. [1,15] and included here by permission of the Institute of Electrical and Electronics Engineers, Inc.
Outage: Describes the state of a component when it is not available to perform its intended function due to some event directly associated with that component. An outage may or may not cause an interruption of service to consumers depending on system configuration.
Forced outage: An outage caused by emergency conditions directly associated with a component that require the component to be taken out of service immediately, either automatically or as soon as switching operations can be performed, or an outage caused by improper operation of equipment or human error.
Scheduled outage: An outage that results when a component is deliberately taken out of service at a selected time, usually for purposes of construction, preventive maintenance, or repair. The key test to determine if an outage should be classified as forced or scheduled is as follows. If it is possible to defer the outage when such deferment is desirable, the outage is a scheduled outage; otherwise, the outage is a forced outage. Deferring an outage may be desirable, for example, to prevent overload of facilities or an interruption of service to consumers.
Partial outage: “Describes a component state where the capacity of the component to perform its function is reduced but not completely eliminated” [2].
Transient forced outage: A component outage whose cause is immediately self-clearing so that the affected component can be restored to service either automatically or as soon as a switch or circuit breaker can be reclosed or a fuse replaced. An example of a transient forced outage is a lightning flashover that does not permanently disable the flashed component.
Persistent forced outage: A component outage whose cause is not immediately self-clearing but must be corrected by eliminating the hazard or by repairing or replacing the affected component before it can be returned to service. An example of a persistent forced outage is a lightning flashover that shatters an insulator, thereby disabling the component until repair or replacement can be made.
Interruption: The loss of service to one or more consumers or other facilities and is the result of one or more component outages, depending on system configuration.
Forced interruption: An interruption caused by a forced outage.
Scheduled interruption: An interruption caused by a scheduled outage.
Momentary interruption: It has a duration limited to the period required to restore service by automatic or supervisor-controlled switching operations or by manual switching at locations where an operator is immediately available. Such switching operations are typically completed in a few minutes.
Temporary interruption: “It has a duration limited to the period required to restore service by manual switching at locations where an operator is not immediately available. Such switching operations are typically completed within 1–2 h” [2].
Sustained interruption: “It is any interruption not classified as momentary or temporary” [2].
At the present time, there are no industry-wide standard outage reporting procedures. More or less, each electric utility company has its own standards for each type of customer and its own methods of outage reporting and compilation of statistics. A unified scheme for the reporting of outages and the computation of reliability indices would be very useful but is not generally practical due to the differences in service areas, load characteristics, number of customers, and expected service quality.
System interruption frequency index: “The average number of interruptions per customer served per time unit. It is estimated by dividing the accumulated number of customer interruptions in a year by the number of customers served” [3].
Customer interruption frequency index: “The average number of interruptions experienced per customer affected per time unit. It is estimated by dividing the number of customer interruptions observed in a year by the number of customers affected” [3].
Load interruption index: “The average kVA of connected load interrupted per unit time per unit of connected load served. It is formed by dividing the annual load interruption by the connected load” [3].
Customer curtailment index: “The kVA-minutes of connected load interrupted per affected customer per year. It is the ratio of the total annual curtailment to the number of customers affected per year” [3].
Customer interruption duration index: “The interruption duration for customers interrupted during a specific time period. It is determined by dividing the sum of all customer-sustained interruption durations during the specified period by the number of sustained customer interruptions during that period” [3].
Momentary interruption: The complete loss of voltage (<0.1 pu) on one or more phase conductors for a period between 30 cycles and 3 s.
Sustained interruption: The complete loss of voltage (<0.1 pu) on one or more phase conductors for a time greater than 1 min.
According to an IEEE committee report [4], the following basic information should be included in an equipment outage report:
- Type, design, manufacturer, and other descriptions for classification purposes
- Date of installation, location on system, length in the case of a line
- Mode of failure (short-circuit, false operation, etc.)
- Cause of failure (lightning, tree, etc.)
- Times (both out of service and back in service, rather than outage duration alone), date, meteorological conditions when the failure occurred
- Type of outage, forced or scheduled, transient or permanent
Furthermore, the committee has suggested that the total number of similar components in service should also be reported in order to determine outage rate per component per service year. It is also suggested that every component failure, regardless of service interruption, that is, whether it caused a service interruption to a customer or not, should be reported in order to determine component-failure rates properly [4]. Failure reports provide very valuable information for preventive maintenance programs and equipment replacements.
There are various types of probabilistic modeling of components to predict component-failure rates, which include (1) fitting a modified time-varying Weibull distribution to component-failure cases and (2) component survival rate studies. However, in general, there may be some differences between the predicted failure rates and observed failure rates due to the following factors [5]:
- Definition of failure
- Actual environment compared with prediction environment
- Maintainability, support, testing equipment, and special personnel
- Composition of components and component-failure rates assumed in making the prediction
- Manufacturing processes including inspection and quality control
- Distributions of times to failure
- Independence of component failures
11.2 National Electric Reliability Council
In 1968, a national organization, the National Electric Reliability Council (NERC), was established to increase the reliability and adequacy of bulk power supply in the electric utility systems of North America. It is a form of nine regional reliability councils and covers all the power systems of the United States and some of the power systems in Canada, including Ontario, British Columbia, Manitoba, New Brunswick, and Alberta, as shown in Figure 11.1.

Regional Electric Reliability Councils.
(From The National Electric ReliabiUty Study, Technical Study Reports, U.S. Department of Energy DOE/EP-0005, April 1981.)
Here, the terms of reliability and adequacy define two separate but interdependent concepts. The term reliability describes the security of the system and the avoidance of power outages, whereas the term adequacy refers to having sufficient system capacity to supply the electric energy requirements of the customers.
In general, regional and nationwide annual load forecasts and capability reports are prepared by the NERC. Guidelines to member utilities for system planning and operations are prepared by the regional reliability councils to improve reliability and reduce costs.
Also shown in Figure 11.1 are the total number of bulk power outages reported and the ratio of the number of bulk outages to electric sales for each regional electric reliability council area to provide a meaningful comparison.
Table 11.1 gives the generic and specific causes for outages based upon the National Electric Reliability Study [6]. Figure 11.2 shows three different classifications of the reported outage events by (a) types of events, (b) generic subsystems, and (c) generic causes. The cumulative duration to restore customer outages is shown in Figure 11.3, which indicates that 50% of the reported bulk power system customer outages are restored in 60 min or less and 90% of the bulk outages are restored in 7 h or less.
Classification of Generic and Specific Causes of Outages
Weather |
Miscellaneous |
System Components |
System Operation |
|---|---|---|---|
Blizzard/snow |
Airplane/helicopter |
Electric and mechanical: |
System conditions: |
Cold |
Animal/bird/snake |
Fuel supply |
Stability |
Flood |
Vehicle: |
Generating unit failure |
High/low voltage |
Heat |
Automobile/truck |
Transformer failure |
High/low frequency |
Hurricane |
Crane |
Switchgear failure |
Line overload/transformer |
Ice |
Dig-in |
Conductor failure |
overload |
Lightning |
Fire/explosion |
Tower, pole attachment |
Unbalanced load |
Rain |
Sabotage/vandalism |
Insulation failure: |
Neighboring power system |
Tornado |
Tree |
Transmission line |
Public appeal: |
Wind |
Unknown |
Substation |
Commercial and industrial |
Other |
Other |
Surge arrestor |
|
Cable failure |
All customers |
||
Voltage control equipment: |
Voltage reduction: 0%–2% voltage reduction |
||
Voltage regulator |
Greater than 2–8 voltage reduction |
||
Automatic tap changer |
Rotating blackout |
||
Capacitor |
Utility personnel: |
||
Reactor |
System operator error |
||
Protection and control: |
Powerplant operator error |
||
Relay failure |
Field operator error |
||
Communication signal error |
Maintenance error |
||
Supervisory control error |
Other |
Source: The National Electric Reliability Study: Technical Study Reports, U.S. Department of Energy DOE/EP-0005, April 1981.

Classification of reported outage events in the National Electric Reliability Study for the period July 1970–June 1979: (a) types of events, (b) generic subsystems, and (c) generic causes.
(From The National Electric Reliability Study, Technical Study Reports, U.S. Department of Energy DOE/EP-0005, April 1981.)

Cumulative duration in minutes to restore reported customer outages.
(From The National Electric Reliability Study, Technical Study Reports, U.S. Department of Energy DOE/EP-0005, April 1981.)
A casual glance at Figure 11.2b may be misleading. Because, in general, utilities do not report their distribution system outages, the 7% figure for the distribution system outages is not realistic. According to The National Electric Reliability Study [7], approximately 80% of all interruptions occur due to failures in the distribution system.
The National Electric Reliability Study [7] gives the following conclusions:
- Although there are adequate methods for evaluating distribution system reliability, there are insufficient data on reliability performance to identify the most cost-effective distribution investments.
- Most distribution interruptions are initiated by severe weather-related interruptions with a major contributor being inadequate maintenance.
- Distribution system reliability can be improved by the timely identification and response to failures.
11.3 Appropriate Levels of Distribution Reliability
The electric utilities are expected to provide continuous and quality electric service to their customers at a reasonable rate by making economical use of available system and apparatus. Here, the term continuous electric service has customarily meant meeting the customers’ electric energy requirements as demanded, consistent with the safety of personnel and equipment. Quality electric service involves meeting the customer demand within specified voltage and frequency limits.
To maintain reliable service to customers, a utility has to have adequate redundancy in its system to prevent a component outage becoming a service interruption to the customers, causing loss of goods, services, or benefits. To calculate the cost of reliability, the cost of an outage must be determined. Table 11.2 gives an example for calculating industrial service interruption cost. Presently, there is at least one public utility commission that requires utilities to pay for damages caused by service interruptions [6].
Detailed Industrial Service Interruption Cost Examplea
Industry |
Overlapped Duration (h) |
Downtime (h) |
Normal Production (h/year) |
Fraction of Annual Production Loss |
Value-Added Losta |
Payroll Losta |
Cleanup and Spoil Productiona |
Standby Power Costa |
Interruption Cost |
|||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Lowera |
Uppera |
Lower ($/kWh) |
Upper ($/kWh) |
|||||||||
Food |
4 |
6.00 |
2,016 |
0.00298 |
4,260 |
1,812 |
279 |
0.00 |
2,091 |
4,539 |
2.38 |
5.17 |
Tobacco |
4 |
6.00 |
2,016 |
0.00298 |
0 |
0 |
0 |
0.00 |
0 |
0 |
0.00 |
0.00 |
Textiles |
4 |
76.00 |
8,544 |
0.00890 |
10,172 |
5,262 |
150 |
0.00 |
5,413 |
10,323 |
10.35 |
19.74 |
Apparel |
4 |
6.00 |
2,016 |
0.00298 |
25,309 |
1,358 |
83 |
0.00 |
1,441 |
25,391 |
5.54 |
97.69 |
Lumber |
4 |
5.25 |
2,016 |
0.00260 |
1,133 |
617 |
248 |
0.08 |
865 |
1,381 |
3.83 |
6.12 |
Furniture |
4 |
6.00 |
2,016 |
0.00298 |
1,074 |
527 |
52 |
0.00 |
579 |
1,127 |
3.51 |
6.83 |
Paper |
4 |
14.00 |
8,544 |
0.00164 |
3,006 |
1,363 |
144 |
0.57 |
1,508 |
3,151 |
0.98 |
2.05 |
Printing |
4 |
6.00 |
8,544 |
0.00070 |
1,146 |
569 |
127 |
0.00 |
696 |
1,273 |
1.74 |
3.19 |
Chemicals |
4 |
24.00 |
8,544 |
0.00281 |
3,899 |
1,102 |
27 |
0.16 |
1,129 |
3,925 |
2.63 |
9.13 |
Petroleum refining |
4 |
6.00 |
8,544 |
0.00070 |
888 |
439 |
32 |
0.00 |
471 |
919 |
6.48 |
6.74 |
Rubber and plastics |
4 |
6.00 |
8,544 |
0.00070 |
592 |
325 |
38 |
0.00 |
363 |
630 |
2.11 |
4.12 |
Leather |
4 |
5.25 |
2,016 |
0.00260 |
1,765 |
757 |
563 |
0.19 |
1,321 |
2,328 |
3.05 |
5.29 |
Stone, clay, glass |
4 |
7.75 |
8,544 |
0.00091 |
925 |
562 |
380 |
0.20 |
942 |
1,306 |
2.58 |
4.54 |
Primary metal |
4 |
5.25 |
2,016 |
0.00061 |
1,731 |
818 |
688 |
0.23 |
1,507 |
2,419 |
1.71 |
2.37 |
Nonelectric machinery |
4 |
5.25 |
4,864 |
0.00108 |
4,851 |
2,192 |
944 |
0.32 |
3,137 |
5,795 |
2.41 |
3.86 |
Electric machinery |
4 |
6.00 |
8,544 |
0.00070 |
2,322 |
1,069 |
246 |
0.29 |
1,315 |
2,568 |
3.65 |
6.75 |
Transportation equipment |
4 |
5.25 |
8,544 |
0.00061 |
1,739 |
1,005 |
858 |
0.88 |
1,864 |
2,598 |
1.68 |
3.20 |
Measuring equipment |
4 |
6.00 |
4,864 |
0.00123 |
2,565 |
1,112 |
104 |
0.00 |
1,215 |
2,669 |
2.34 |
3.26 |
Miscellaneous manufacturing |
4 |
6.00 |
4,864 |
0.00123 |
1,817 |
794 |
97 |
0.11 |
891 |
1,914 |
3.72 |
8.17 |
Agriculture |
21 |
21 |
2.90 |
7.79 |
||||||||
69,293 |
21,779 |
5,059 |
3.07 |
26,861 |
74,375 |
2.81 |
7.79 |
|||||
Source: The National Electric Reliability Study: Technical Study Reports, U.S. Department of Energy DOE/EP-0005, April 1981.
a In thousands of dollars.
Reliability costs are used for rate reviews and requests for rate increases. The economic analysis of system reliability can also be a very useful planning tool in determining the capital expenditures required to improve service reliability by providing the real value of additional (and incremental) investments into the system.
As the National Electric Reliability Study [6] points out, “it is neither possible nor desirable to avoid all component failures or combinations of component failures that result in service interruptions. The level of reliability can be considered to be ‘appropriate’ when the cost of avoiding additional interruptions exceeds the consequences of those interruptions to consumers.
Thus the appropriate level of reliability from the consumer perspective may be defined as “that level of reliability when the sum of the supply costs plus the cost of interruptions which occur are at a minimum”. Figure 11.4 illustrates this theoretical concept. Note that the system’s reliability improvement and investment are not linearly related, and that the optimal (or appropriate) reliability level of the system corresponds to the optimal cost, that is, the minimum total cost. However, Billinton [8] points out that “the most improper parameter is perhaps not the actual level of reliability though this cannot be ignored but the incremental reliability cost. What is the increase in reliability per dollar invested? Where should the next dollar be placed within the system to achieve the maximum reliability benefit?”

In general, other than “for possible sectionalizing or reconfiguration to minimize either the number of customers affected by an equipment failure or the interruption duration, the only operating option available to the utility to enhance reliability is to minimize the duration of the interruption by the timely repair of the failed equipment(s)” [6].
Experience indicates that most distribution system service interruptions are the result of damage from natural elements, such as lightning, wind, rain, ice, and animals. Other interruptions are attributable to defective materials, equipment failures, and human actions such as vehicles hitting poles, cranes contacting overhead wires, felling of trees, vandalism, and excavation equipment damaging buried cable or apparatus.
Some of the most damaging and extensive service interruptions on distribution systems result from snow or ice storms that cause breaking of overhanging trees, which in turn damage distribution circuits. Hurricanes also cause widespread damage, and tornadoes are even more intensely destructive, though usually very localized. In such severe cases, restoration of service is hindered by the conditions causing the damage, and most utilities do not have a sufficient number of crews with mobile and mechanized equipment to quickly restore all service when a large geographic area is involved.
The coordination of preventive maintenance scheduling with reliability analysis can be very effective. Most utilities design their systems to a specific contingency level, for example, single contingency, so that, due to existing sufficient redundancy and switching alternatives, the failure of a single component will not cause any customer outages. Therefore, contingency analysis helps to determine the weakest spots of the distribution system.
The special form of contingency analysis in which the probability of a given contingency is clearly and precisely expressed is known as the risk analysis. The risk analysis is performed only for important segments of the system and/or customers. The resultant information is used in determining whether to build the system to a specific contingency level or to risk a service interruption. Figure 11.5 shows the flowchart of a reliability planning procedure.

A reliability planning procedure.
(From Smith, C.O., Introduction to Reliability in Design, McGraw-Hill, New York, 1976; Albrect, P.F., Overview of power system reliability, Workshop Proceedings: Power System Reliability-Research Needs and Priorities, EPRI Report WS-77-60, Palo Alto, CA, October 1978.)
11.4 Basic Reliability Concepts and Mathematics
Endrenyi [2] gives the classical definition of reliability as “the probability of a device or system performing its function adequately, for the period of time intended, under the operating conditions intended.” In this sense, not only the probability of failure but also its magnitude, duration, and frequency are important.
11.4.1 General Reliability Function
It is possible to define the probability of failure of a given component (or system) as a function of time as
where
T is a random variable representing the failure time
F(t) is the probability that component will fail by time t
Here, F(t) is the failure distribution function, which is also known as the unreliability function. Therefore, the probability that the component will not fail in performing its intended function at a given time t is defined as the reliability of the component. Thus, the reliability function can be expressed as
where
R(t) is the reliability function
F(t) is the unreliability function
Note that the R(t) reliability function represents the probability that the component will survive at time t.
If the time-to-failure random variable T has a density function f(t), from Equation 11.2,
Therefore, the probability of failure of a given system in a particular time interval (t1, t2) can be given either in terms of the unreliability function, as
or in terms of the reliability function, as
Here, the rate at which failures happen in a given time interval (t1, t2) is defined as the hazard rate, or failure rate, during that interval. It is the probability that a failure per unit time happens in the interval, provided that a failure has not happened before the time t1, that is, at the beginning of the time interval. Therefore,
If the time interval is redefined so that
or
then since the hazard rate is the instantaneous failure rate, it can be defined as
or
where f(t) is the probability density function
Also, by substituting Equation 11.3 into Equation 11.8,
Therefore,
or
Hence,
or
Taking derivatives of Equation 11.13 or substituting Equation 11.13 into Equation 11.9,
Also, substituting Equation 11.3 into Equation 11.13,
where
Let
hence Equation 11.16 becomes
Equation 11.18 is known as the general reliability function. Note that in Equation 11.18 both the reliability function and the hazard (or failure) rate are functions of time.
Assume that the hazard or failure function is independent of time, that is,
From Equation 11.14, the failure density function is
Therefore, from Equation 11.8, the reliability function can be expressed as
which is independent of time. Thus, a constant failure rate causes the time-to-failure random variable to be an exponential density function.
Figure 11.6 shows a typical hazard function known as the bathtub curve. The curve illustrates that the failure rate is a function of time. The first period represents the infant mortality period, which is the period of decreasing failure rate. This initial period is also known as the debugging period, break-in period, burn-in period, or early life period. In general, during this period, failures occur due to design or manufacturing errors.

The second period is known as the useful life period, or normal operating period. The failure rates of this period are Constant, and the failures are known as chance failures, random failures, or catastrophic failures since they occur randomly and unpredictably.
The third period is known as the wear-out period. Here, the hazard rate increases as equipment deteriorates because of aging or wear as the components approach their “rated lives.” If the time t2 could be predicted with certainty, then equipment could be replaced before this wear-out phase begins.
In summary, since the probability density function is given as
it can be shown that
and by integrating Equation 11.22,
However,
From Equation 11.24,
Therefore, from Equations 11.23 and 11.25, reliability can be expressed as
However,
Thus, the unreliability can be expressed as
or
Therefore, the relationship between reliability and unreliability can be illustrated graphically, as shown in Figure 11.7.

11.4.2 Basic Single-Component Concepts
Theoretically, the expected life, that is, the expected time during which a component will survive and perform successfully, can be expressed as
Substituting Equation 11.21 into Equation 11.29,
Integrating by parts,
since
and
the first term of Equation 11.31 equals zero, and therefore, the expected life can be expressed as
or
The special case of useful life can be expressed, when there is a constant failure rate, by substituting Equation 11.20 into Equation 11.34a, as
Note that if the system in question is not renewed through maintenance and repairs but simply replaced by a good system, then the E(T) useful life is also defined as the mean time to failure and denoted as
where λ is the constant failure rate.
Similarly, if the system in question is renewed through maintenance and repairs, then the E(T) useful life is also defined as the mean time between failures and denoted as
where
is the mean cycle time
is the mean time to failure
is the mean time to repair
Note that the mean time to repair is defined as the reciprocal of the average (or mean) repair rate and denoted as
where μ is the mean repair rate.
Consider the two-state model shown in Figure 11.8a. Assume that the system is either in the up (or in) state or in the down (or out) state at a given time, as shown in Figure 11.8b. Therefore, the mean time to failure can be reasonably estimated as

where
is the mean time to failure
mi is the observed time to failure for ith cycle
n is the total number of cycles
Similarly, the mean time to repair can be reasonably estimated as
where
is the mean time to repair
ri is the time to repair for ith cycle
n is the total number of cycles
Therefore, Equation 11.37 can be reexpressed as
The assumption that the behaviors of a repaired system and a new system are identical from a failure standpoint constitutes the base for much of renewal theory. In general, however, perfect renewal is not possible, and in such cases, terms such as the mean time to the first failure or the mean time to the second failure become appropriate.
Note that the term mean cycle time defines the average time that it takes for the component to complete one cycle of operation, that is, failure, repair, and restart. Therefore,
Substituting Equations 11.36 and 11.38 into Equation 11.42,
The reciprocal of the mean cycle time is defined as the mean failure frequency and denoted as
When the states of a given component, over a period to time, can be characterized by the two-state model, as shown in Figure 11.8, then it can be assumed that the component is either up (i.e., available for service) or down (i.e., unavailable for service). Therefore, it can be shown that
where
A is the availability of component, that is, the fraction of time component is up
is the unavailability of component, that is, the fraction of time component is down
Therefore, on the average, as time t goes to infinity, it can be shown that the availability is
or
or
Thus, the unavailability can be expressed as
Substituting Equation 11.46 into Equation 11.49,
or
or
Consider Equation 11.47 for a given system’s availability, that is,
when the total number of components involved in the system is quite large and
then the division process becomes considerably tedious. However, it is possible to use an approximation form. Therefore, from Equation 11.47,
or
or, approximately,
It is somewhat unfortunate, but it has become customary in certain applications, for example, nuclear power plant reliability studies, to employ the MTBF for both unrepairable components and repairable equipment and systems. In any event, however, it represents the same statistical concept of the mean time at which failures occur. Therefore, using this concept, for example, the availability is
and the unavailability is
11.5 Series Systems
11.5.1 Unrepairable Components in Series
Figure 11.9 shows a block diagram for a series system that has two components connected in series. Assume that the two components are independent. Therefore, to have the system operate and perform its designated function, both components (or subsystems) must operate successfully. Thus,

and since it is assumed that the components are independent,
or
or
where
Ei is the event that component i (or subsystem i) operates successfully
Ri = P(Ei) is the reliability of component i (or subsystem i)
Rsys is the reliability of system (or system reliability index)
To generalize this concept, consider a series system with n independent components, as shown in Figure 11.10. Therefore, the system reliability can be expressed as
and since the n components are independent,
or
or
Note that Equation 11.63 is known as the product rule or the chain rule of reliability. System reliability will always be less than or equal to the least-reliable component, that is,
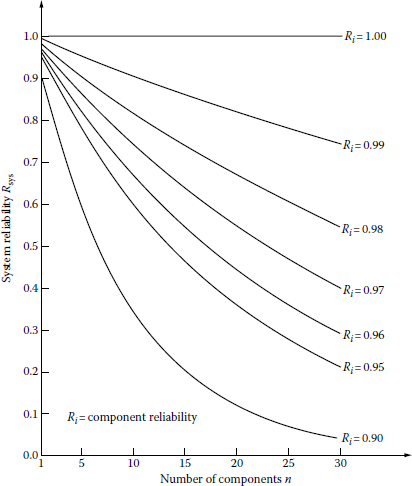
Therefore, the system reliability, due to the characteristic of the series system, is the function of the number of series components and the component reliability level. Thus, the reliability of a series system can be improved by (1) decreasing the number of series components or (2) increasing the component reliabilities. This concept has been illustrated in Figure 11.11.
Assume that the probability that a component will fail is q and it is the same for all components for a given series system. Therefore, the system reliability can be expressed as
or, according to the binomial theorem,
If the probability of the component failure q is small, an approximate form for the system reliability, from Equation 11.66, can be expressed as
where
n is the total number of components connected in series in the system
q is the probability of component failure
If the probabilities of component failures, that is, qi’s, are different for each component, then the approximate form of the system reliability can be expressed as
Example 11.1
Assume that 15 identical components are going to be connected in series in a given system. If the minimum acceptable system reliability is 0.99, determine the approximate value of the component reliability.
Solution
From Equation 11.67,
and
Therefore, the approximate value of the component reliability required to meet the particular system reliability can be found as
11.5.2 Repairable Components in Series*
Consider a series system with two components, as shown in Figure 11.9. Assume that the components are independent and repairable. Therefore, the availability or the steady-state probability of success (i.e., operation) of the system can be expressed as
where
Asys is the availability of system
A1 is the availability of component 1
A2 is the availability of component 2
Since
and
substituting Equations 11.70 and 11.71 into Equation 11.69 gives
or
where
is the mean time to failure of component 1
is the mean time to failure of component 2
is the mean time to failure of system
is the mean time to repair of component 1
is the mean time to repair of component 2
is the mean time to repair of system
The average frequency of the system failure is the sum of the average frequency of component 1 failing, given that component 2 is operable, plus the average frequency of component 2 failing while component 1 is operable. Thus,
where
is the average frequency of system failure
is the average frequency of failure of component i
Ai is the availability of component i
Since
and
substituting Equations 11.75 and 11.76 into Equation 11.74 gives
Note that Equation 11.73 can be expressed as
Thus, the mean time to failure for a given series system with two components can be expressed as
Hence, the mean time to failure of a given series system with n components can be expressed as
Since the reciprocal of the mean time to failure is defined as the failure rate, for the two-component system,
and for the n-component system,
Similarly, it can be shown that the mean time to repair for the given two-component series system is
or, approximately,*
Therefore, the mean time to repair for an n-component series system is
11.6 Parallel Systems
11.6.1 Unrepairable Components in Parallel
Figure 11.12 shows a block diagram for a system that has two components connected in parallel. Assume that the two components are independent. Therefore, to have the system fail and not be able to perform its designated function, both components must fail simultaneously. Thus, the system unreliability is

and since it is assumed that the components are independent,
or
where
is the event that component i fails
= is the unreliability of component i
Qsys is the unreliability of system (or system unreliability index)
Then the system reliability is given by the complementary probability as
for this two-unit redundant system.
To generalize this concept, consider a parallel system with m independent components, as shown in Figure 11.13. Therefore, the system unreliability can be expressed as
and since the m components are independent, or
or
Therefore, the system reliability is
or
Note that there is an implied assumption that all units are operating simultaneously and that failures do not influence the reliability of the surviving subsystems.
The instantaneous failure rate of a parallel system is a variable function of the operating time, even though the failure rates and mean times between failures of the particular components are constant. Therefore, the system reliability is the joint function of the mean time between failures of each path and the number of parallel paths. As can be seen in Figure 11.14, for a given component reliability, the marginal gain in the system reliability due to the addition of parallel paths decreases rapidly.

Thus, the greatest gain in system reliability occurs when a second path is added to a single path. The reliability of a parallel system is not a simple exponential but a sum of exponentials. Therefore, the system reliability for a two-component parallel system is
where
λ1 is the failure rate of component 1
λ2 is the failure rate of component 2
11.6.2 Repairable Components in Parallel*
Consider a parallel system with two components as shown in Figure 11.12. Assume that the components are independent and repairable. Therefore, the unavailability or the steady-state probability of failure of the system can be expressed as
where
Usys is the unavailability of system
U1 is the unavailability of component 1
U2 is the unavailability of component 2
Since
and
substituting Equations 11.96 and 11.97 into Equation 11.95 gives
However, the average frequency of the system failure is
where
is the average frequency of system failure
is the average frequency of failure of component i
Ui is the unavailability of component i
Since
and
substituting equation sets (11.96), (11.97) and (11.100), (11.101) into Equation 11.99 and simplifying gives
From Equation 11.50, the system unavailability can be expressed as
or
so that
Therefore, substituting Equations 11.98 and 11.102 into Equation 11.105, the average repair time (or downtime) of the two-component parallel system can be expressed as*
or
Similarly, from Equation 11.51, the system unavailability can be expressed as
from which
Substituting Equations 11.98 and 11.106 into Equation 11.109, the average time to failure (or operation time, or uptime) of the parallel system can be expressed as
The failure rate of the parallel system is
or
When more than two identical units are in parallel and/or when the system is not purely redundant, that is, parallel, the probabilities of the states or modes of the system can be calculated by using the binomial distribution or conditional probabilities.
Example 11.2
Figure 11.15 shows a 4 mi long distribution express feeder that is used to provide electric energy to a load center located in the downtown area of Ghost City from the Ghost River Substation. Approximately 1 mi of the feeder has been built underground due to aesthetic considerations in the vicinity of the downtown area, while the rest of the feeder is overhead. The underground feeder has two termination points. On the average, two faults per circuit-mile for the overhead section and one fault per circuit-mile for the underground section of the feeder have been recorded in the last 10 years.

The annual cable termination fault rate is given as 0.3% per cable termination. Furthermore, based on past experience, it is known that, on the average, the repair times for the overhead section, underground section, and each cable termination are 3, 28, and 3 h, respectively. Using the given information, determine the following:
- Total annual fault rate of the feeder
- Average annual fault restoration time of the feeder in hours
- Unavailability of the feeder
- Availability of the feeder
Solution
- Total annual fault rate of the feeder is
where
λOH is the total annual fault rate of overhead section of feeder
λUG is the total annual fault rate of underground section of feeder
λCT is the total annual fault rate of cable terminations
Therefore,
- Average fault restoration time of the feeder per fault is
where
is the average repair time for overhead section of feeder, h
is the average repair time for underground section of feeder, h
is the average repair time per cable termination, h
Thus,
However, the average annual fault restoration time of the feeder is
or
- Unavailability of the feeder is
where
Therefore,
- Availability of the feeder is
Example 11.3
Assume that the primary main feeder shown in Figure 11.16 is manually sectionalized and that presently only the first three feeder sections exist and serve customers A, B, and C. The annual average fault rates for primary main and laterals are 0.08 and 0.2 fault/circuit-mile, respectively. The average repair times for each primary main section and for each primary lateral are 3.5 and 1.5 h, respectively. The average time for manual sectionalizing of each feeder section is 0.75 h. Assume that at the time of having one of the feeder sections in fault, the other feeder section(s) are sectionalized manually as long as they are not in the mainstream of the fault current, that is, not in between the faulted section and the circuit breaker. Otherwise, they have to be repaired also.

Based on the given information, prepare an interruption analysis study for the first contingency only, that is, ignore the possibility of simultaneous outages, and determine the following:
- The total annual sustained interruption rates for customers A, B, and C.
- The average annual repair times, that is, downtimes, for customers A, B, and C.
- Write the necessary codes to solve the problem in MATLAB.
Solution
- Total annual sustained interruption rates for customers A, B, and C are
- Average annual repair time, that is, downtime (or restoration time), for customer A is
where
average repair time for customer A
is the total fault rate for feeder section i per year
is the average repair time for faulted primary main section
is the average repair time for faulted primary lateral
is the average time for manual sectionalizing per section
λlat. A is the total fault rate for lateral A per year
Therefore,
Similarly, for customer B,
and for customer C,
- Here is the MATLAB script:
clcclear% System parameters% failure rateslambda_sec1 = 1*0.08;lambda_sec2 = lambda_sec1;lambda_sec3 = lambda_sec1;lambda_sec4 = lambda_sec1;lambda_latA = 2*0.2;lambda_latB = 1.5*0.2;lambda_latC = 1.5*0.2;lambda_latD = 1*0.2;lambda_latE = 1.5*0.2;lambda_latF = 2*0.2;% repair timesr_sec = 3.5;r_lat = 1.5;r_MS = 0.75;% manual sectionalizing% Solution to part a% Total annual sustained interruption rates for customers A, B and ClambdaA = lambda_sec1 + lambda_sec2 + lambda_sec3 + lambda_latAlambdaB = lambda_sec1 + lambda_sec2 + lambda_sec3 + lambda_latBlambdaC = lambdaB% Solution to part b% Average annual repair time for customers A, B and CrA = (lambda_sec1*r_sec + lambda_sec2*r_MS + lambda_sec3*r_MS + lambda_latA*r_lat)/lambdaArB = (lambda_sec1*r_sec + lambda_sec2*r_sec + lambda_sec3*r_MS + lambda_latB*r_lat)/lambdaBrC = (lambda_sec1*r_sec + lambda_sec2*r_sec + lambda_sec3*r_sec + lambda_latC*r_lat)/lambda