
CHAPTER 59
DISASTER RECOVERY
Michael Miora
59.2 IDENTIFYING THREATS AND DISASTER SCENARIOS
59.2.2 Disaster Recovery Scenarios
59.3 DEVELOPING RECOVERY STRATEGIES
59.3.3 Data Backup Scenarios and Their Meanings
59.5 IMPLEMENTATION AND READINESS
59.1 INTRODUCTION.
In Chapter 58 in this Handbook, the importance of a business impact analysis (BIA) and the method of preparing one were described. Once the preliminary groundwork is finished and the BIA analysis is complete, the next step is to design specific strategies for recovery and the tasks for applying those strategies. In this chapter, we discuss the specific strategies to recover the Category I functions, the most time-critical functions identified during the BIA, as well as the remaining lower-priority functions. We examine the traditional strategies of hot sites, warm sites, and cold sites as well as a more modern technique we call reserve systems. We describe how to make good use of Internet and client/server technologies, and of high-speed connections for data backup, for making electronic journals and for data vaulting. We develop the recovery tasks representing the specific activities that must take place to continue functioning, and to resume full operations. These tasks begin with the realization that there is, or may be, a disaster in progress, continue through to full business resumption, and end with normalization, which is the return to normal operations. We examine a set of tasks taken from a real-world disaster recovery plan to illustrate how each task fits into an overall plan, accounting for anticipated contingencies while providing flexibility to handle unforeseen circumstances.
59.2 IDENTIFYING THREATS AND DISASTER SCENARIOS.
Threat assessment is the foundation for discovery of threats and their possible levels of impact. Threat assessments can vary from rigorous analyses of natural events and the probabilities associated with them, to informal surveys of recent disasters and their regional characteristics. The rigorous analysis will yield detailed results but will require significant effort to perform the required research and to interpret the results. The informal survey can yield sufficient information for the disaster recovery planner, and it requires significantly less effort.
59.2.1 Threats.
Local fire, police, and other emergency response services can provide the data needed for an informal survey. Flood district management agencies can provide data regarding floods of all types, whether caused by storms, draining, or other factors. Police departments can provide information about building or neighborhood closures due to man-made catastrophes, whereas city and county governments can provide information about emergency declarations over a period of years.
Compiling this list of threats accomplishes two objectives: It helps define the different levels of impact, and it helps to develop a risk mitigation plan. The mitigation techniques outlined in the plan are intended to lower the damage caused by the likeliest disasters. For example, an area prone to seasonal flooding can reduce the risk of computer outages by placing computer installations and important equipment above the flood level. Facilities located in areas prone to power failures can install UPS (uninterruptible power supply) equipment with higher capacities than usual for the type of equipment being protected.
Many threats can have important consequences to information-processing systems. Physical security risks stand out among them as the highest-profile disasters. These are also the most highly dependent on geography and include events such as fire, flood, and earthquake.
Exhibit 59.1 lists a large number of threats to help the disaster recovery planner begin the process of listing threats that apply to specific facilities.
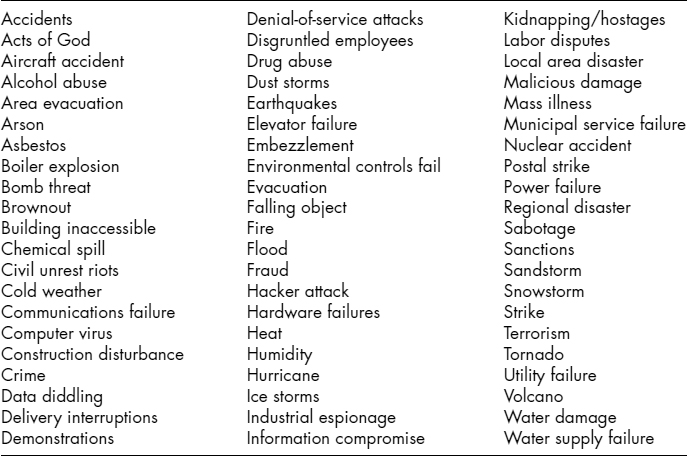
EXHIBIT 59.1 List of Threats
59.2.2 Disaster Recovery Scenarios.
Each of the threats described in Exhibit 59.1 causes specific damage, with the scope of damage and damage characteristics well known and predefined. Once the characteristics of specific threats are known, then mitigation measures can be applied. One of the important mitigation techniques is the application of survivable technologies to mission-critical functions. Survivable technologies applied to the most critical of the functions (Category I) can prevent outages or at least significantly lower the probability and duration of the outage. For example, client/server and distributed architectures can be implemented with geographic data distribution, so that the loss of a single data center will not disrupt operations but may only degrade them. One such strategy is the geographically dispersed placement of two computers operating on a single main network with functionality shared between them. If backup data are regularly logged from one machine to another, then both systems maintain current databases. If one system is disrupted, then the other can assume full functions; the response times may degrade, but the functionality will not be lost. Replicated architectures with automatic failover are an even better alternative. The desirability of such measures was amply demonstrated by the catastrophe of September 11, 2001, again by Hurricane Katrina, and yet again in the Southern California fires of 2007.
Escalation scenarios are mechanisms that map the expected duration of failures against the requirements for operational continuity. With well-known threats as described, and the ensuing and defined outage durations that can be characterized, disaster declaration and escalation points can be calculated and presented. Timelines must be carefully constructed to leave little room for doubt.
Exhibit 59.2 provides an example of an escalation timeline. Note that the figure is based on data from Chapter 58, and from Exhibit 58.17 in particular. In this exhibit, the top, horizontal row of boxes corresponds to recovery time estimates. For each column, specific initiation parameters are established. The operators and engineers can, at a glance, determine whether this particular situation requires a disaster declaration. For example, an estimated downtime of less than one day requires no recovery since in Exhibit 58.17, there are no functions requiring recovery in less than one day. The key factors are that the operations personnel must be trained in the use of the procedures and must have ready access to contact information for disaster recovery declaration authorities.
Disaster recovery scenarios and activities are dependent on the scope of the damage. Therefore, it is necessary to group specific events according to a classification of the damage they inflict on a facility. Once this is accomplished, the disaster recovery planner can identify declaration, escalation, and recovery activities based on the specific threats and their resulting disaster scenarios. Classifications of damage include the duration of an outage and the scope of its effects.
Exhibit 59.3 summarizes some threat durations and provides some sample classifications of damage. The first column of the exhibit lists a sampling of threats, and the second column classifies each threat according to the possible scope of its effect. The set of possibilities contains systems only, partial or full building, local area, and regional area.
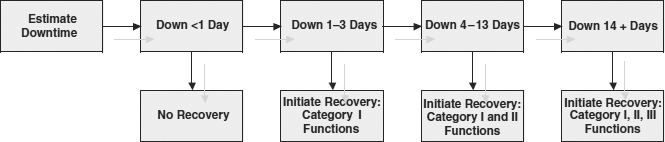
EXHIBIT 59.2 Escalation Timeline
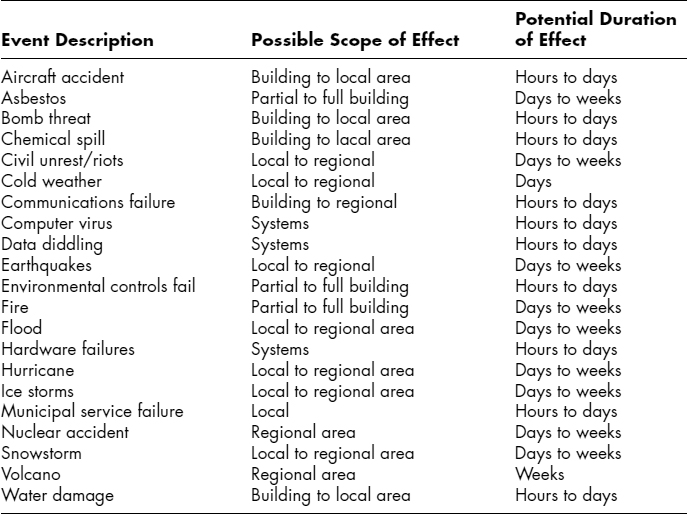
EXHIBIT 59.3 Sample Classifications of Damage
A systems-only disaster leaves the facility unaffected but partially or fully disables the system's operations. Breaches of logical security usually affect only systems, as do hardware failures. The exhibit does not attempt to differentiate between types of systems and number of systems affected, but the disaster recovery planner must do that classification for each facility and for the interactions of facilities. A characteristic of systems-only disasters is that sometimes they can travel across physical boundaries, such as when the incident involves a security breach, a connectivity disruption, or a software failure.
As an example of a system disaster, in 2007, one major company experienced just such a failure during the testing of a dry pipe sprinkler system. When the system was pressurized, the pipes burst. The data center was not serviced by the sprinkler system; it had its own system in place. However, one pipe crossed over the data center, a fact thereto unknown to the systems management personnel. When that pipe burst, the entire data center, which included a raised floor, was quickly flooded, making all the equipment wet from top and bottom. Fortunately, this company had prepared for the loss of any one of its data centers by building a load-balanced system, so that the loss of any one data center would cause only minimally reduced response times.
Partial- or full-building disasters consist of events that cause physical damage to a building. Fires usually affect only one building at a time. Even detection of asbestos, which most often occurs during building maintenance or improvement, is seldom a multibuilding affair. Local and regional area disasters are difficult to distinguish from each other. Generally, a disaster that affects a single geographic area, such as a city or neighborhood, is a local area disaster, whereas a disaster affecting more than one geographic entity is a regional disaster. The importance of this demarcation is that local area disasters at a company site may affect some of the employees personally, although most will be unaffected, except as it relates to company business. A regional disaster usually affects most employees' homes and families as well as the organizations that employ them. A municipal services failure clearly affects a single geographic entity, and employees living outside of that municipality are unlikely to be affected. Conversely, a major storm resulting in floods, or a large earthquake, will affect residents and businesses over a wide area, probably leaving employees at work concerned with the health and safety of their families and homes. The availability of employees to handle a disaster is much greater when the disaster is local, or of smaller scope, than during a regional disaster.
The third column in Exhibit 59.3 estimates the duration of the effect, ranging from hours to days to weeks. These are inexact and somewhat vague guidelines only. Although fire is listed as having a duration ranging from days to weeks, a very small fire may be managed and the building reoccupied in only a few hours. Similarly, an earthquake is listed as having a duration of days to weeks, yet a major earthquake may have large impacts lasting many months. After the 1994 Northridge earthquake in Southern California, for example, major highway arteries were closed for many months, requiring employees to telecommute or spend hours per day traveling. This affected the operations of many companies, forcing them to redesign their workflows. The Seattle earthquake of February 2001, however, had no such long-term effects. Many companies initiated disaster recovery procedures to handle the commuting problem, even when there had been no physical damage to the corporate facilities. The terrorist destruction of the World Trade Center twin towers in New York on September 11, 2001, is perhaps the most obvious example of how the destruction or closure of major roads and other transportation means affected operations of companies not otherwise affected by the terrorist act itself.
The disaster recovery planner must analyze enough specific threats against the corporate operations and physical plant to build a series of disaster scenarios, which become the guiding forces of the recovery activity definitions. Some planners design disaster recovery scenarios to suit each disaster threat. Floods call for one set of activities, fires another. This can result in an extensive set of scenarios, each requiring training, testing, and maintenance. This technique may be too complex. Another similar approach uses active scenarios chosen from a set of only five possible levels of disasters: systems only, partial building, full building, local, and regional. Each organization should try to reduce the number of disaster scenarios, generally to no more than three, and many can handle emergencies adequately using only two scenarios. For most organizations, a systems-only disaster is not restricted to computer systems, but may include phone systems and telecommunications systems. Systems-only cases must be defined in the context of the organization's unique structure.
For example, a manufacturing facility may require three scenarios: systems only, partial building, and full building. Perhaps for the manufacturer, a loss of systems can be handled with a hot site for computers and a fast, high-bandwidth connection to the shop floor. A partial building disaster, affecting only office space, can be handled similarly, but with additional office space for support functions. A full-building disaster that damages or destroys manufacturing capability requires a completely different set of continuation and recovery procedures. As another example, a corporate office facility may require just two scenarios—systems only and building disaster—where the building disaster is a combined building, local, and regional scenario. The systems hot site can handle the systems-only disaster. The building disaster scenario will require that all functions be restored at a hot site that provides full office functions from phone to fax to desks and copiers in addition to computer systems and networks.
The planner defines the sets of disasters and develops recovery scenarios for those sets. This defines the number of scenarios required; then the disaster recovery activities can be designed.
59.3 DEVELOPING RECOVERY STRATEGIES.
The BIA defines the timeline for recovery for each category of functions. The recovery strategies depend on factors such as: the complexity of the functions, the amount of information required to carry them out, the number of people involved in performing the function, and the amount of interaction between this function and other functions. The strategy of choice for each function is based on the timeline and the specific factors relating to it. The tasks required to activate the function immediately after a disaster follow directly from the BIA timeline and from the various factors that have been described.
Recovery strategies are defined differently from continuation strategies. The recovery strategy is the overall plan for resuming a function, or set of functions, in a near-normal work mode. The continuation strategy is the plan for immediate or nearly immediate operations of a key function, even if it results in significantly degraded performance or limited capability. The continuation strategy is most often applied to a small set of functions rather than to a more complete set, and it is often only temporary. Although the recovery strategy may be used for several weeks or longer, the continuation strategy typically survives for hours or days.
Traditional recovery strategies include hot sites, warm sites, and cold sites. The most common recovery strategy uses a commercial service provider to maintain an on-demand operating capability for well-defined systems. There are a variety of such companies, some of which provide a standby mainframe or midrange system, along with selected peripherals and telecommunications facilities on a first-come, first-served basis. Others guarantee availability by providing a dedicated facility.
The operating capability required is defined at the outset. Processor type is specified down to the model level. Required disk space, hard drives, tape drives, ports, connectivity, and all other required elements must be specified explicitly. Timeline requirements must be stated precisely, with rehearsal, practice, and drill times negotiated in advance. Geographic location of the backup systems is often determined at the time of disaster declaration, and connectivity is usually provided to corporate fixed facilities. The obvious advantage of this strategy is ready access to maintained systems and environments. The principal disadvantage is cost.
A continuation strategy usually depends on internal resources rather than on commercially available providers. Continuation strategy requires that equipment be available instantly, with current data. “Instant availability” means that the systems must be local, or at least connected, yet survivable. The continuation strategy is becoming more common as microcomputer-based systems assume greater roles in corporate computing structures. The continuation strategy often relies on reserve systems, a concept pioneered over the past five years. This strategy, described in Section 59.3.2.8, uses high-performance microcomputers residing off site at homes, branch offices, and other locations easily accessible to employees.
The reserve system provides immediate, but limited, functionality so that operations can be continued after a disaster while awaiting full restoration or recovery.
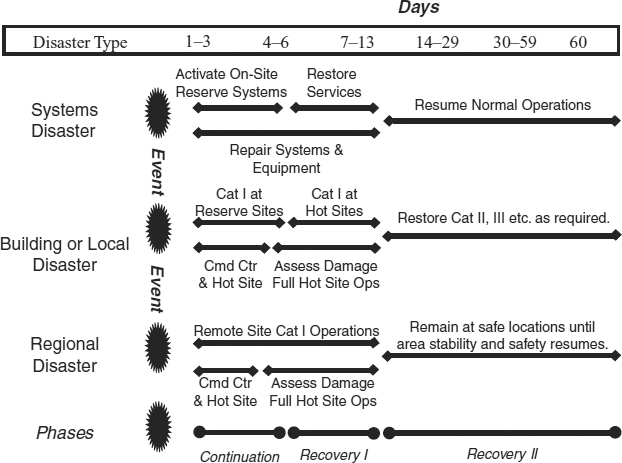
EXHIBIT 59.4 Recovery Phases
59.3.1 Recovery Phases.
Orderly recovery requires organized processes and procedures. The BIA uncovers the time sensitivity and criticality of functions, so that continuation and recovery strategies can be designed. Activation of these strategies is performed systematically in time-phased increments.
Exhibit 59.4 shows an example of such phasing. The figure is based on Exhibit 58.17, and illustrates a common schema that consists of three scenarios. Each scenario represents a collection of disasters according to their effects on the company. The first, a systems disaster, represents an effect that has interrupted computer and related systems but has left basic services such as heating and air conditioning, water, power, and life safety intact. The second scenario is the building or local disaster. In this case, a major portion of the building, the entire building, or even several surrounding buildings are rendered unfit for occupancy. This may be due to a problem with the building or with the local area, including fire, toxic spills, minor flooding of surrounding areas, terrorist action, and other such events. The third scenario is the regional disaster, in which some calamitous event affects a wider geographic area. Examples of such catastrophes are earthquakes, hurricanes, floods, large fires or firestorms, and heavy ice and snowstorms.
Each of these scenarios requires different recovery strategies and tasks. However, the overall recovery phases remain similar. The exhibit shows that there are three basic phases: continuation of critical (Category I) functions, recovery of critical functions, and recovery of other functions. These are labeled near the bottom of the figure as “Continuation,” “Recovery I,” and “Recovery II.”
The Continuation phase begins at the time of the disaster. For each scenario, the goal of the continuation phase is to support the Category I functions as best as possible, and within the time frames defined by the BIA. In this example, the BIA timeline for Category I functions is one to three days. For the systems disaster and the building or local disaster scenarios, the Continuation phase depends on the local or on-site reserve systems. For the regional disaster, where local functioning may be impossible, the Category I functions must be supported by remote sites.
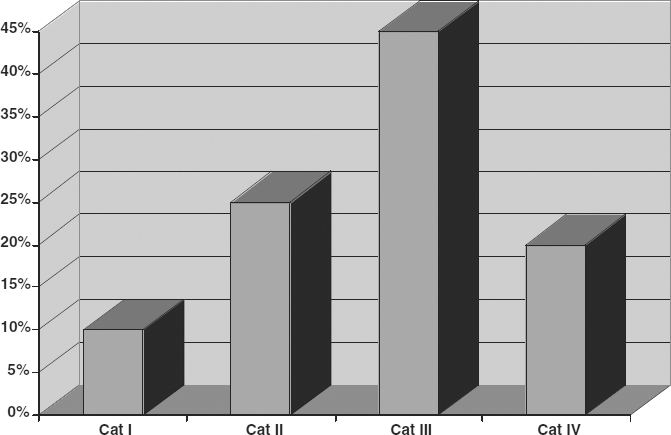
EXHIBIT 59.5 Spread of Functions across Categories
The recovery phase is further divided into two subphases. Recovery I phase restores full or nearly full functionality to the Category I functions that were partially supported by the reserve systems. In the example, the Recovery I phase begins after all continuation functions have been stabilized. In practice, it is more common for the Recovery I phase to begin shortly after the disaster event in order to minimize the duration during which the Category I functions must operate in a degraded fashion. The Recovery II phase is used to recover other functions in the order they are needed, as defined by the BIA. Exhibit 59.5 shows the typical spread of functions across categories. Typically, Category I functions constitute approximately 10 to 15 percent of the functions performed in a facility or campus. The Category II functions consist of functions that are very important and time critical but can be delayed for a short time. These functions significantly outnumber the Category I functions, sometimes reaching 20 to 35 percent of facility functions. Category III and, if applicable, Category IV functions are much greater in number, often comprising more than half of the facility functions performed.
The BIA process assessed the cost contribution of each category of functions to the total losses the company would sustain after a disaster without a plan. Exhibit 59.6 compares the number of functions per category to the total impact of the functions in each category on operations in a typical organization. Although Category I functions number the fewest of all categories, their impact is the greatest. The Category III functions typically rank second in contributions to losses, with Category II third in rank. The critical functions that constitute Category I are ranked first precisely because of their high impact and time criticality. Category III is typically the largest group, so that even though the impact of each function may be small, the large number of functions increases the total effect of that group. Category IV tends to be a fairly small set of functions, so typically it is small in number and last in impact.
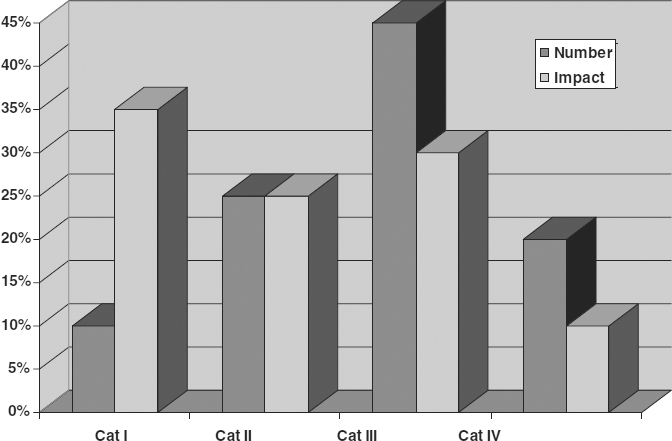
EXHIBIT 59.6 Number versus Impact of Functions
In the example, the systems disaster phases reflect certain assumptions. The Continuation phase begins at the time of the disaster and continues for up to three days. The Recovery phase is scheduled to begin no later than the fourth day, with full recovery by the seventh day, at which time a return to normal operations is expected. The underlying assumption is that the off-site reserve systems have been replicated on site. This is shown by the caption “Activate On-Site Reserve Systems” on Exhibit 59.4. An additional assumption in this example is that the system can be recovered in less than seven days. Some analysis would have been performed to show that new equipment or equipment repairs could be obtained fairly early during the first seven days, leaving enough time for service restoration, including data recovery, to be completed by the seventh day. In this example, it is also clear that the Category II functions are required beginning on the seventh day. This is illustrated by the building or system disaster Recovery II phase, which begins on the seventh day and is labeled as restoring Category II, III, and other functions.
59.3.2 Range of Strategies.
Three general areas of traditional recovery strategies address the needs of mainframes, midrange systems, and PC LAN systems. There is a rich history and many years of experience in providing recovery for large, mainframe systems, with strategies that include hot sites, cold sites, reciprocal or mutual aid agreements, and commercial recovery facilities, as will be described.
Strategies for recovery of midrange systems, including distributed systems, minicomputers, and workstations, include all the same strategies as those used for mainframe systems, along with mobile data centers, internal redundancy, failover arrangements, and agreements with manufacturers for priority shipping of replacement equipment.
PC LAN system recovery strategies are the newest of the three areas. They typically make use of combinations of capabilities, including quick replacement, off-site equipment storage (equipment sparing), and hot sites.
59.3.2.1 Cold Sites.
A cold site is a room or set of rooms in a “ready-conditioned” environment. It is a fully functional computer room with all of the required facilities, including electrical power, air conditioning, raised floors, and telecommunications, all in operating condition and ready for occupancy. Missing from this fully functional room, because of high costs, is the computer equipment, including the processors and all required peripherals. Cold sites can be owned by one company or shared by several companies.
The major advantage of a dedicated cold site, somewhat diminished in the shared case, is simply that for a relatively low acquisition or leasing cost, the site is guaranteed to be available over the long term to the owner or lessee of the site. To be effective, a cold site must be distant enough from the main facility so that a disaster that makes the primary facility unusable will likely not affect the cold site.
There are several disadvantages to cold sites. First and foremost is that ordering, receiving, installing, and powering up the computer system can take many days. Once the system is functional, the cold site becomes a dedicated facility ready to perform all functions in a controlled environment, but the time required to achieve this state can stretch into a week or more. Few organizations can rely on a cold site as their primary vehicle for disaster recovery. A secondary disadvantage of cold sites is the inherent inability to test the recovery plan. An untested plan is an unreliable plan—testing a cold site would require obtaining all of the requisite equipment, installing the equipment, and performing operations on the new equipment. Few organizations can afford the costs associated with such testing. There are also hidden pitfalls with this strategy. Key equipment may be unavailable for immediate delivery. Communication lines may be untested and unreliable. This strategy is generally not a desirable first line of defense. It can, however, be a part of a larger overall strategy that includes other types of sites.
59.3.2.2 Hot Sites.
A hot site is a facility ready to assume processing responsibility immediately. The term usually refers to a site that contains equipment ready to assume all hardware functions, but requiring massive restoration of data and an influx of personnel to operate the equipment. The hot site cannot, therefore, begin total processing instantaneously. In actuality, the site is only warm, with an ability to get hot fast. A hot site can be dedicated to one organization, shared by several organizations, or leased from a specialty company, called a commercial recovery service provider. The provider option is described in a later section.
The primary advantage of a hot site is the speed of recovery. The time to resume processing is defined as the time to reach the facility with people and backup media, plus the time to restore data and programs from the backup media, to test the operations, and to go live with a fully functional system. For larger systems, this period can range from less than two days to almost a week.
The primary disadvantage of a hot site is the cost associated with acquiring and maintaining the fully equipped site. For this reason, most organizations choose to share the cost of a hot site with other organizations, which may be sister companies or only neighbors. In any event, there is a large cost associated with maintaining the site and ensuring that it is updated with every change to each of the participant's requirements, while still maintaining compatibility with all of them. One of the most common solutions to this problem is to use a service provider.
59.3.2.3 Reciprocal Agreements.
Reciprocal agreements were often used in the earlier decades of disaster recovery planning but are uncommon today. A reciprocal agreement is an arrangement between two or more companies in which each agrees to make excess capacity available to the others in case of a disaster. The major advantage is the apparent low cost of this solution. The major disadvantage is that these arrangements rarely provide the needed computing power. A major issue with these arrangements is maintaining compatible systems. If one company changes a processor, it may find that its partners' systems cannot perform adequately, even in degraded mode. If the host company faces a crisis or deadline of its own, a reciprocal company may find itself with no computer power at all. These arrangements are seldom testable, because it is the rare company willing to shut down operations to help a partner perform a disaster recovery test.
59.3.2.4 Internal Redundancy.
A strategy of internal redundancy requires that a business have multiple facilities, geographically dispersed, with similar equipment in each site. If there are data centers at several sites, then the alternate data centers may be designed with excess capacity to support a potential failure at another site.
The major advantage of internal redundancy is that the organization maintains complete control of all equipment and data, without relying on any outside company to come to its aid. The excess capacity at the various alternate sites must be carefully protected, and management must exercise diligence in budgeting and operations. Careful intracompany agreements must be crafted to ensure that all parties are aware of, and agree to, the backup arrangements. Internal redundancy can be an effective solution in cases where temporarily degraded processing still can provide sufficient support to meet timeline requirements. If degraded performance is not an acceptable option, then the cost of the excess capacity will probably be too high. If reasonable degradation is acceptable, then those costs can be manageable.
Internal redundancy can also be difficult to test. Testing requires that processing be shifted to a recovery mode. Unlike external, separate computers, all of these redundant systems would be operational. Testing one disaster recovery plan requires affecting a minimum of two corporate locations. A failed test that causes a system crash or other problem can have damaging consequences.
Internal redundancy can overcome its difficulties if the redundancy is part of a load-balanced system with automatic or semiautomatic failover. In such cases, normal processing is already split between the primary and backup system so that both systems are fully operational at all times. The recovery requirements add an additional dimension to the nominal load-balancing configuration. Namely, there can be no system or system component that is unique to only one site. The most common load-balancing implementations may still rely, for example, on a database housed at only one site. This is insufficient for recovery purposes. If full duplication can be achieved, then the sudden loss of one of the systems causes degradation rather than loss of functionality. There are, however, often technical issues that many organizations must overcome prior to the implementation of such load balancing with full redundancy. For example, some legacy systems do not support multiple points of processing; some modern implementations may require a single database instead of multiple, overlapping databases, as is required for full load balancing with redundancy.
59.3.2.5 Mobile Data Centers.
Mobile data centers are transportable units such as trailers outfitted with replacement equipment, air conditioning, electrical connections, and all other computer requirements. Mobile data centers are used most often for recovery of midrange and PC LAN systems. The primary advantage of the mobile data center is that it can be activated quickly at reasonably low cost. The primary disadvantages are the expense of testing such a facility and the possibility that a local or regional disaster will prevent successful activation. Deploying a mobile data center requires careful planning. Land must be available to accommodate the transportable units, with outside parking lots as the most common resource. Local government and municipal regulations must be researched in advance to ensure that such units do not violate ordinances, and can arrive as certified for immediate occupancy. External power and communications hookups also must be available.
59.3.2.6 Priority Replacement Agreements.
Some computer vendors support priority equipment replacement agreements. These are arrangements in which the vendor promises to ship replacement equipment on a priority basis. For midrange systems, this is often an agreement to send the next-off-the-line system to the priority customer. The major advantage of this strategy is its low cost. However, if the vendor is not currently manufacturing the required system, or if the assembly line is down for any reason, and if equipment stocks are depleted, there may still be a significant delay in receiving the equipment. This is the major disadvantage. This strategy also assumes the disaster recovery plan makes an alternate facility available in case the primary facility is damaged along with the equipment being replaced.
59.3.2.7 Commercial Recovery Services.
Commercial recovery service providers can support a combination of the strategies just discussed. These companies generally provide three major benefits: cost sharing, reduced management needs, and diminished risk of obsolescence. First, they spread facility costs across multiple subscribers so that each subscriber saves as compared with building and maintaining a comparable, privately held capability. Because all subscribers share the same physical space, each pays less than would be needed to maintain such a site independently.
The second major benefit of using a commercial provider is that these companies eliminate the need for the subscriber to manage backup resources. Management and maintenance of such a site by an individual business could be a heavy burden, but the provider's primary focus is on managing, maintaining, and upgrading the equipment and sites. The subscriber company can be assured that the equipment is exercised and serviced regularly and that peripheral equipment, power systems, and facility support structures are properly maintained. A properly run site will also provide security, safety, compliance with evolving rules and regulations, and competent staffing. The provider assumes full responsibility for these functions during normal operations and continues support during times of crisis. The subscriber brings its technical personnel, while the provider leaves its facilities staff in place.
The third major benefit centers around today's fast pace of hardware evolution. A subscriber company typically leases a hot site or other service for a five-year period. During that time, hardware platforms will evolve. The subscribing company can protect its lease investment by ensuring that system upgrades are reflected in the leased equipment configuration for reasonable extra charges. A business that provides its own hot site must upgrade the hot site whenever hardware, and sometimes software, changes are made to the operational systems.
The disadvantage of commercial recovery services is in the obvious risk that the hot site may not be available in an emergency. Indeed, if a local or regional disaster affects numerous subscribers, there could be significant contention for the provider's resources. To address this issue, providers typically maintain hot sites in geographically dispersed areas. Although it is likely that in the case of a local or regional disaster a subscriber would need to use a hot site farther away than planned, it is unlikely that the subscriber would be left completely without the prearranged resources.
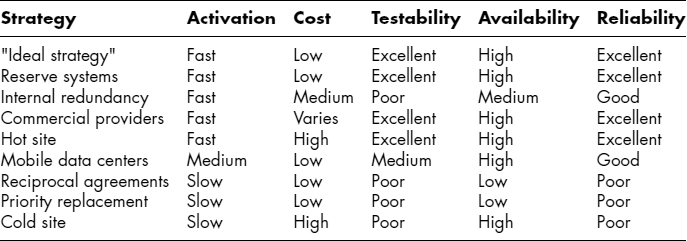
EXHIBIT 59.7 Strategy Overview
59.3.2.8 Reserve Systems.
The newest of strategies is the reserve system, which is a small replica of a portion of an operational system meant for use during the first few days following a disaster. The reserve system provides continuation of key functions for short durations, although in degraded mode. The reserve system usually resides off site at an employee's home or at another corporate office. Another version of the reserve system is also kept on site. A reserve site may be equipped with a microcomputer or a minicomputer ready to assume functioning in case the primary system becomes unavailable. This meets the important criteria of a reserve system, which must be fast and easy to activate, simple to move, low in cost, testable, available, and highly reliable.
The reserve system concept was not feasible until client/server technology emerged and telecommuting with high-speed communications became accepted and readily available. Many large organizations provide employees the option of telecommuting on a regular basis so that they work at home sometimes and in the office at other times. Web-centric processing and remote application server technologies can provide powerful reserve systems for disaster recovery.
Proper security precautions must be taken to protect proprietary, confidential, and critical information stored on these reserve systems. Strong encryption protects against theft, while redundant systems protect against other losses. The reserve system is a quick-response, short-term solution intended to solve the problem of immediate continuation, even in the case where employees may be unable to travel outside their immediate residence areas. See Exhibit 59.7 for an overview of different recovery strategies.
59.3.3 Data Backup Scenarios and Their Meanings.
Data backup is a key function in all system installations. The best recovery strategy, chosen to meet recovery timelines according to the BIA, is useless without a backup from which to restore and resume operations. Data backup is perhaps the single most critical element of a disaster recovery plan, yet only 31 percent of U.S. companies have backup plans and equipment. See Chapter 41 in this Handbook for details of backup scenarios.
59.4 DESIGNING RECOVERY TASKS.
The disaster recovery plan becomes an operating document when the strategies and reserve capabilities are translated into specific actions to be performed during the disaster recovery process. These are the actions required to protect assets, mitigate damage, continue partial operations, and resume full operations. Most tasks begin with actions to evaluate the disaster and then to initiate recovery procedures. The example recovery task flow (Exhibit 59.8) lists a series of steps to evaluate the situation. These steps, numbered 1 through 5, determine whether to declare a disaster or not. The second set of steps, numbered 6 through 10, is used to initiate recovery procedures. These first two sets of steps are called the beginning sequence.
The beginning sequence leads to full activation of a disaster recovery effort. The next set of activities, called the middle sequence, institutes the actions necessary to perform business continuation and recovery. Usually multiple choices for the middle sequence correspond to the disaster scenarios developed. Each path in the middle sequence is executed for a particular scenario. At the end of the middle sequence, full operations are resumed as specified in the disaster recovery plan. In the exhibit, the middle sequence includes two distinct paths. The first path includes steps numbered 11 through 20, and the second path includes steps numbered 21 through 30.
The end sequence begins with damage assessments and continues through resumption of normal operations in the original facility, a semipermanent facility, or a new facility. The end sequence may begin while the middle sequence is still unfolding. The timing is dependent on the requirements specific in the BIA. The end sequence consists of two sets of activities performed in sequence. The first set consists of steps 31 through 38, and the second set consists of steps 39 through 59.
59.4.1 Beginning Sequence.
The beginning sequence (Exhibit 59.9) helps the disaster recovery team in its first two major actions: evaluation of the emergency and initiation of the recovery procedures. Box 1, labeled “Disaster Evaluation,” begins the process with a set of actions whose end goal determines what actions to take to meet the upcoming emergency. In step 2, the disaster recovery team determines which course of action to take: continue normal operations, disrupt operations for a short while and then resume normal operations, or initiate a full- or partial-scale disaster recovery. The decision is based on a set of predetermined criteria.
Box 2 is labeled “Evaluate Emergency.” This is the step in which the disaster recovery team assesses the expected duration and extent of the upcoming or existing outage. Using a set of criteria developed as part of the BIA, and based on the assessment of the outage, the team determines which course of action to take. For example, if the emergency is a power outage, the disaster recovery team will likely call the power utility to determine the cause. If the outage is expected to last less time than the shortest recovery requirement, then it may make the most sense simply to disrupt operations for a short time without initiating recovery procedures. The comprehensive disaster recovery procedures provide sufficient guidance in a simple form to support the team's decision-making process while leaving room for real-time evaluation and decision making.
If the decision is to initiate disaster recovery procedures, then the flow proceeds through box 5, “Initiate DR Procedure,” to the initiation phase represented by the actions in boxes 6 through 9. In step 6, the disaster recovery team determines which of the disaster scenarios applies; the team formally declares that type of disaster in step 7, and notifies, in step 8, the disaster recovery team and others, as required, of the decisions made and the next steps to take. All members of the team are pretrained and equipped with written procedures that anticipate each of these potential decisions. The only remaining step in the beginning sequence is box 9, “Manage Legal Issues.” From the moment a disaster situation is considered, the team must document its decisions. In some industries, this is required by regulatory agencies; in public companies, it may be required for reporting to a board of directors' committee meeting. For all companies, it is important to maintain a clear record of the diligence used in planning and implementing recovery.
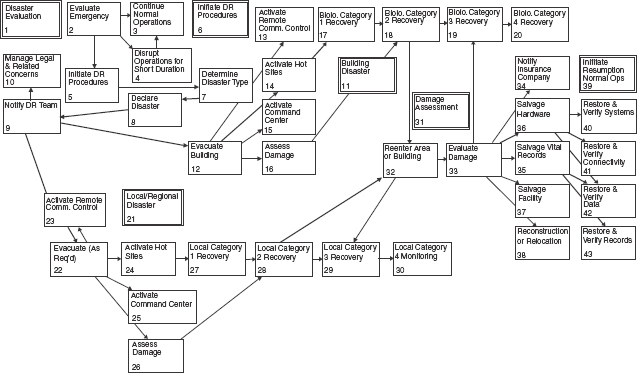
EXHIBIT 59.8 Recovery Task Flow

EXHIBIT 59.9 Beginning Sequence
In addition to legal concerns, there are insurance concerns. Typically, money spent during the recovery process is reimbursable by insurance policies. This includes out-of-pocket expenditures by staff; the cost of travel, food, and lodging vouchers; and other allowed expenditures for meeting disaster recovery needs. In its haste to restore damaged systems, the team may neglect to document specific damages; once repaired, it is difficult to submit an insurance claim unless the damage is documented properly. Box 10 represents a step that begins early and continues throughout the disaster recovery process.
59.4.2 Middle Sequence.
The middle sequence represents the activities that begin once the disaster recovery procedures are under way. In our example, there are two possible paths for the middle sequence to follow. The steps are labeled similarly, but the specific actions taken are quite different. There is an advantage to using a schematic representation of the steps and their relationships: The overall structure or shape can show at a glance the complexity or simplicity of the plan. It is best to be as uncomplicated as possible, even if the form and structure require larger content. Exhibit 59.10 describes the middle sequence, “Building Scenario.”
The first step listed in the middle sequence, Building Scenario, is to evacuate the building. Although this is clearly performed as early as possible, perhaps even early in the beginning sequence, it is presented here for completeness. Human safety is the primary concern of any recovery plan—no employee should ever be allowed to delay evacuation or reenter a building, except in the case of a qualified individual who is helping others evacuate or attempting a rescue attempt. The next four activities occur in parallel. They are represented by boxes 3 through 6, and include activation functions for remote communications, the hot sites, and the command center. These four steps also include a first effort at damage assessment.
Box 3 is labeled “Activate Remote Communications Control.” This is the activity that reroutes digital and analog communications from their normal patterns to their emergency routes. This may include telecommunications lines, call center toll-free lines, normal business lines, data lines, and other communications media. Typically, arrangements are made in advance with the various telecommunications carriers so that a series of short phone calls can initiate the rerouting. If arrangements were not made in advance, then the rerouting will not meet timeline requirements, and may significantly impair the efficiency of the disaster recovery team members.
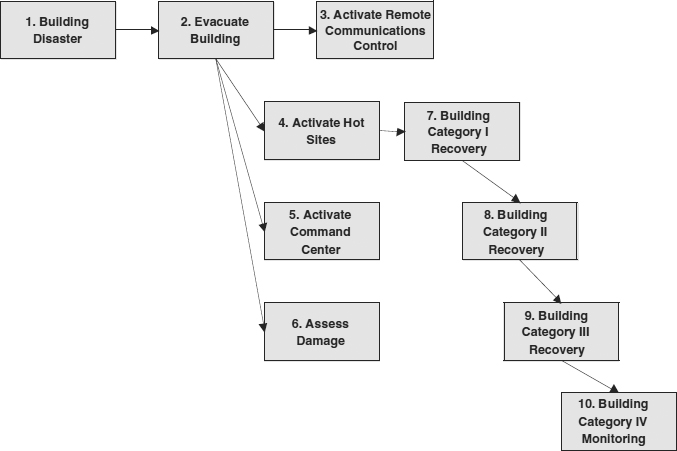
EXHIBIT 59.10 Middle Sequence, Building Scenario
Box 4, “Activate Hot Sites,” represents the sets of actions required to inform the hot site provider that a disaster is in progress. Hot site activation must be performed at the earliest moment, so that the hot site can be available as soon as possible and so that, in cases of contention, the preferred hot site will be available.
Hot site activation usually obligates the company to pay certain activation costs and occasionally a minimum usage cost. If the disaster requires the hot site, then insurance often reimburses the company for related expenses, but if the declaration was erroneous, the company will suffer a financial loss.
The major hot site providers' services are quite reliable. There are few instances of hot site providers failing to meet their obligations, and many stories of near-heroic feats performed to meet customer needs. One provider even abandoned its own operations so that a client suffering from a regional disaster could occupy the provider's corporate space to continue its own operations. Hot site contracts usually include a proviso that in cases of contention, where more than one company is seeking the same disaster recovery space, the provider can send the late declarer to another, equivalent site. This means that the disaster recovery plan must include instructions for multiple hot sites. All maps, directions, instructions, and delivery requirements must be consistent with the assigned hot site location. Clearly, it is in the company's best interest to declare early so that the hot site of choice is obtained. It would be prudent to err on the side of early declaration rather than late declaration, especially in cases of regional disasters.
Boxes 7 through 10 represent recovery of the various categories of functions. It is seldom possible or desirable to recover all functions simultaneously. The BIA determined and documented the timelines for all functions needing recovery. The procedures must reflect that analysis so that functions are in fact recovered “just in time.” These four boxes are labeled Building Category Recovery I to IV. Each box represents the full set of procedures required to bring all the functions in each category into operational mode. For example, if there are seven functions in the Category I group, then there will be seven sets of procedures required to implement Box 7. Category I functions usually require special efforts, such as reserve systems. Therefore, each Category I function may require two sets of activation procedures: the first for the reserve system and the second for the hot site.
At the conclusion of the middle sequence, all required functions would have been recovered. It may be that during the beginning sequence a determination was made that the disaster would require only recovery of a subset of functions. A small-scale power failure, for example, may require only Category I functions to be recovered. A weather disaster with no lasting effects may require Category I and Category II functions. This decision is made during the early phases of the recovery, and reevaluated continually throughout the recovery process.
59.4.3 End Sequence.
The end sequence represented in Exhibit 59.11 is the long path back to normal operations. The end sequence consists of two major phases. The “Damage Assessment” set of activities comprises the first phase and includes boxes 2 through 8. The “Initiate Resumption of Normal Operations” set of activities constitutes the second phase and includes boxes 10 through 13. Although there is an assess damage activity at the beginning of the middle sequence, that activity is a quick assessment of damage for the purpose of determining what recovery options need to be activated. This damage assessment activity is a comprehensive evaluation of damage to equipment, facilities, and records.
Box 2 is labeled “Reenter Area or Building.” This activity needs supporting procedures to guide disaster recovery team members on what regulatory, municipal, state, and federal authorities control access into damaged facilities. Often access is restricted for long periods of time even when there is little or no apparent damage. For example, following an earthquake, structural engineers may tag a building as uninhabitable pending further analysis. As another example, after a fire, the fire marshal may prohibit entry pending analysis by chemical engineers to determine whether the fire produced hazardous materials. Fires often cause chemical reactions that transform normal, benign office materials into toxic chemicals. The procedures for box 2 should provide contact information for each major agency that may control the facility after a disaster.
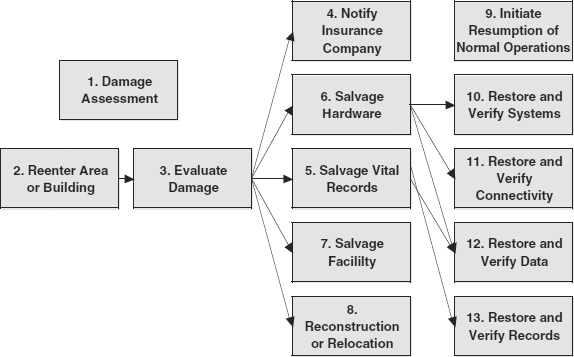
EXHIBIT 59.11 End Sequence
Box 3 leads to five parallel activities. The first, “Notify Insurance Company,” is related to the “Manage Legal and Other Concerns” activity in the beginning sequence. In this case, the various insurance carriers will need to send their own adjusters and engineers to help assess the damage.
The procedures for box 4 should provide the disaster recovery team with specific contact information for all insurance carriers with which the company has policies in force. The insurance company must be given the opportunity to investigate the premises before any salvage, repair, or cleanup operations begin. Unlike the period immediately following a disaster, when some cleanup may be required for safety and health reasons, the insurance company will look very unfavorably at any attempt to disturb the scene prior to it inspections. This does not mean that facility repairs must await a leisurely investigation and inspection by the insurance company; there are immediate steps to take to make preparations for salvage and repair. The procedure for box 4 will aid the disaster recovery team in deciding what they can do immediately, how they can document status prior to repairs, and what must await the approval of the insurance company and others.
Boxes 5 through 7 are the control procedures for salvaging hardware, records, and the facility. The procedures for “Salvage Hardware” must contain all the contact information for hardware vendors, including computer, communications, reproduction, and others. Each type of equipment requires different salvage operations; the best procedure for a computer may, for example, be the worst procedure for a magnetic tape drive. The salvage procedures should provide general guidelines and contact information for quick access to salvage experts. The same is true for facility salvage procedures.
Salvaging vital records is a complex and unpredictable process. For some records, drying is the top priority; for others, getting them into oxygen-free containers is far more important. The procedures supporting the “Salvage Vital Records” activity must provide contact points, general instructions, and guidance for making decisions about salvage possibilities. Unlike hardware, where the salvage decision is usually driven by cost considerations alone, salvaging vital records and legacy materials may be driven by other factors, such as corporate legacy and history considerations or legal issues. The salvage decision is often much more subjective in this area.
Box 8 is labeled “Reconstruction or Relocation.” This task differs from the other tasks in three important ways. First, it is likely that the members of the disaster recovery team will not have the required authority to make this decision but will play an important role in presenting analyses to the decision-making top management people. Second, there are no specific company-external contacts to be made by the disaster recovery team as a part of this process. Although a real estate agent may be contacted for information, it is not likely that the disaster recovery team will undertake that task. The third difference is that the result of this activity is not some specific observable process but a set of recommendations made to top management. The procedures built to support this activity should provide guidance to the disaster recovery team so that they can develop the analyses and present the results in a timely fashion.
Box 9 represents the last phase of the disaster recovery process, initiating the process that returns operations to a normal operating environment. At the time the plan is written, there is no way to predict whether by following this step the company will be relocating to a new facility, or making minor repairs or none, and returning to the existing facility. The importance of these last steps is that they confirm the operability of the newly restored and operational systems. Each of these activities needs to be supported by a set of procedures that guide qualified personnel in their tasks of restoring and verifying systems, networks, data, and records.
59.5 IMPLEMENTATION AND READINESS.
The final steps in preparing the disaster recovery plan are proving that the plan works and ensuring that the people understand their roles. This is performed through rehearsals, walk-throughs, and testing. Once the plan is completed and all of the reserve systems and capabilities have been installed, it is time to test whether these backup systems work as planned. There are a variety of testing phases, starting with extremely limited tests performed separately from ongoing operations and proceeding through full tests using live data.
The first set of tests is intended to prove that specific functions and capabilities are in place and available for use. These are the on-site and off-site limited tests, whose goal is to segregate tasks into small groups of related functions. With only a few functions per tests, there can be many tests that, in the aggregate, prove that each required function is successfully represented in the suite of recovery capabilities. The on-site portion of these tests will “disconnect” the users from normal operating capabilities such as LAN, WAN, and support staff.
This is best accomplished by setting up a testing room within the facility, but away from operations. Users are given the tools and instructions they would receive during a real disaster, and they attempt to perform their designated disaster recovery functions. An example of such a function is emergency payroll operations, where the outsource company is notified that this is only a test or the backup company facility is put on notice that a test is in progress. The tests would determine whether off-line systems were able to process and transfer data as expected. It also may demonstrate that manual procedures work as written. In this testing, the keys are to set test objectives in advance, monitor test progress, ensure that users have only the expected disaster recovery tools at their disposal and no others, and document the results. After the on-site tests prove satisfactory, these same basic, limited procedures should be followed off-site as they would be during an actual emergency. This requires some employees to stay away from the office, so the tests should be planned to avoid periods of expected high activity.
Once the functions have been tested, the next set of tests is intended to prove that the technical systems can be made operational in the planned time frame and that the systems can support users as expected. Two types of tests accomplish this: off-site network tests and hot site tests. These are discussed together because they are often overlapping capabilities performed at the same time. The off-site network and large-system hot site tests demonstrate that the systems and networks can each be restored within the time allotted and that the interface between them survives the transition to hot site operations. One of the primary advantages of performing the off-site network and hot site tests concurrently is that connectivity and intersystem functionality can be demonstrated.
The last test is a full operations test that attempts to show that all of these elements will work together. Just as in a real emergency, the test will focus on a subset of normal operations. Critical functions are tested first, and other functions are added according to the recovery timeline. For these operations, a test disaster is declared. Employees are notified that this is a test and that they are to cease normal operations and immediately implement their recovery procedures.
Most disaster recovery tests use simulated data or backup data that are real but are not the operational data. Changes made and transactions recorded during such tests are never brought back into the operational environment. Processing performed during the test is based on simulated business operations, with “representative” transactions rather than real ones. In the past decade, there has been a trend toward making final full operations tests online, using actual backup sites, systems, and procedures for processing real transactions. This makes the test process significantly more exciting, with a corresponding increase in stress, for employees and management. Mistakes made in this type of testing can cost the company dearly, but success can assure the company of a recovery plan that is much more likely to succeed during a real crisis.
Employees participating in full operations tests, using real data, are going to be much more serious, but employee rewards are also greater. There is more of a feeling of accomplishment if the test processed live data rather than simulated data. After the test, employees can return to work without needing to catch up on missed work. Management is also more likely to be directly involved in a live test than in a simulated test—because in a real test, management will be called on to make real decisions. They are more likely to be present, just as they would be during a real emergency. Not all organizations are structured in such a way as to make live tests possible. When they can be used, they are the most valid test of the recovery plan. However, they should never be attempted until the plan has been proven using multiple instances of the full complement of tests that should precede the live test.
59.6 CONCLUDING REMARKS.
Over the past three decades, the very nature of the threats we considered, and the preparations we made, have changed dramatically. In the early days, major fears included equipment failures and minor geographic events, such as storms and small floods. In the event of a major catastrophe, we felt confident that our plans would unfold as well as those of our neighboring companies; perhaps there would even be some cooperation between companies.
In the decade of the 1990s, however, the criticality of systems combined with an upsurge in man-made disasters forced us to rethink our practices, scenarios, and procedures. The first bombing of the New York World Trade Center in 1993, the bombing of the Murrah Federal Building in Oklahoma City in 1995, the damage to the Pentagon and the heinous destruction of the World Trade Center twin towers in 2001, as well as attacks and failed attempts worldwide since then have finally led us to the point where we must include “artificial” disasters in our planning as well as natural ones. The disaster recovery planner must now consider disasters and recovery scenarios that include terrorism as well as tornadoes. The task is difficult, but the techniques and technologies are the same as before.
59.7 FURTHER READING
See Chapter 58 in this Handbook for a list of suggested readings.