
CHAPTER 8
USING A COMMON LANGUAGE FOR COMPUTER SECURITY INCIDENT INFORMATION
John D. Howard
8.2 WHY A COMMON LANGUAGE IS NEEDED
8.3 DEVELOPMENT OF THE COMMON LANGUAGE
8.4 COMPUTER SECURITY INCIDENT INFORMATION TAXONOMY
8.4.3 Full Incident Information Taxonomy
8.5 ADDITIONAL INCIDENT INFORMATION TERMS
8.6 HOW TO USE THE COMMON LANGUAGE
8.1 INTRODUCTION.
A computer security incident is some set of events that involves an attack or series of attacks at one or more sites. (See Section 8.4.3 for a more formal definition of the term “incident.”) Dealing with these incidents is inevitable for individuals and organizations at all levels of computer security. A major part of dealing with these incidents is recording and receiving incident information, which almost always is in the form of relatively unstructured text files. Over time, these files can end up containing a large quantity of very valuable information. Unfortunately, the unstructured form of the information often makes incident information difficult to manage and use.
This chapter presents the results of several efforts over the last few years to develop and propose a method to handle these unstructured, computer security incident records. Specifically, this chapter presents a tool designed to help individuals and organizations record, understand, and share computer security incident information. We call the tool the common language for computer security incident information. This common language contains two parts:
- A set of “high-level” incident-related terms
- A method of classifying incident information (a taxonomy)
The two parts of the common language, the terms and the taxonomy, are closely related. The taxonomy provides a structure that shows how most common-language terms are related. The common language is intended to help investigators improve their ability to:
- Talk more understandably with others about incidents
- Gather, organize, and record incident information
- Extract data from incident information
- Summarize, share, and compare incident information
- Use incident information to evaluate and decide on proper courses of action
- Use incident information to determine effects of actions over time
This chapter begins with a brief overview of why a common language is needed, followed by a summary of how the incident common language was developed. We then present the common language in two parts: (1) incident terms and taxonomy and (2) additional incident information terms. The final section contains information about some practical ways to use the common language.
8.2 WHY A COMMON LANGUAGE IS NEEDED.
When the first edition of this Handbook was published more than 30 years ago, computer security was a small, obscure, academic specialty. Because there were only a few people working in the field, the handling of computer security information could largely take place in an ad hoc way. In this environment, individuals and groups developed their own terms to describe computer security information. They also developed, gathered, organized, evaluated, and exchanged their computer security information in largely unique and unstructured ways. This lack of generalization has meant that computer security information has typically not been easy to compare or combine, or sometimes even to talk about in an understandable way.
Progress over the years in agreeing on a relatively standard set of terms for computer security (a common language) has had mixed results. One problem is that many terms are not yet in widespread use. Another problem is that the terms that are in widespread use often do not have standard meanings. An example of the latter is the term “computer virus.” We hear the term frequently, not only in academic forums but also in the news media and popular publications. It turns out, however, that even in academic publications, “computer virus” has no accepted definition.1 Many authors define a computer virus to be “a code fragment that copies itself into a larger program.”2 They use the term “worm” to describe an independent program that performs a similar invasive function (e.g., the “Internet Worm” in 1988). But other authors use the term “computer virus” to describe both invasive code fragments and independent programs.
Progress in developing methods to gather, organize, evaluate, and exchange computer security information also has had limited success. For example, the original records (1988–1992) of the Computer Emergency Response Team (now the CERT Coordination Center or CERT/CC) are simply a file of e-mail and other files sent to the CERT/CC. These messages and files were archived together in chronological order, without any other organization. After 1992, the CERT/CC and other organizations developed methods to organize and disseminate their information, but the information remains difficult to combine or compare because most of it remains almost completely textual information that is uniquely structured for the CERT/CC.
Such ad hoc terms and ad hoc ways to gather, organize, evaluate, and exchange computer security information are no longer adequate. Far too many people and organizations are involved, and there is far too much information to understand and share. Today computer security is an increasingly important, relevant, and sophisticated field of study. Numerous individuals and organizations now regularly gather and disseminate computer security information. Such information ranges all the way from the security characteristics and vulnerabilities of computers and networks, to the behavior of people and systems during security incidents—far too much information for each individual and organization to have its own unique language.
One of the key elements to making systematic progress in any field of inquiry is the development of a consistent set of terms and taxonomies (principles of classification) that are used in that field.3 This is a necessary and natural process that leads to a growing common language, which enables gathering, exchanging, and comparing information. In other words, as a field of inquiry such as computer security grows, the more a common language is needed to understand and communicate with one another.
8.3 DEVELOPMENT OF THE COMMON LANGUAGE.
Two of the more significant efforts in the process of developing this common language for computer security incident information were (1) a project to classify more than 4,300 Internet security incidents completed in 1997,4 and (2) a series of workshops in 1997 and 1998, called the Common Language Project. Workshop participants included people primarily from the Security and Networking Research Group at the Sandia National Laboratories, Livermore, California, and from the CERT/CC at the Software Engineering Institute, Carnegie Mellon University, Pittsburgh, Pennsylvania. Additional participation and review came from people in the Department of Defense (DoD) and the National Institute of Standards and Technology (NIST).
These efforts to develop the common language were not efforts to develop a comprehensive dictionary of terms. Instead, the participants were trying to develop both a minimum set of “high-level” terms to describe computer security attacks and incidents, and a structure and classification scheme for these terms (a taxonomy), which could be used to classify, understand, exchange, and compare computer security attack and incident information.
Participants in the workshops hoped this common language would gain wide acceptance because of its usefulness. There is already evidence that this acceptance is taking place, particularly at incident response teams and in the DoD.
In order to be complete, logical, and useful, the common language for computer security incident information was based initially and primarily on theory (i.e., it was a priori or nonempirically based).5 Classification of actual Internet security incident information was then used to refine and expand the language. More specifically, the common language development proceeded in six stages:
- Records at the CERT/CC for incidents reported to them from 1988 through 1995 were examined to establish a preliminary list of terms used to describe computer security incidents.
- The terms in this list, and their definitions, were put together into a structure (a preliminary taxonomy).
- This preliminary taxonomy was used to classify the information in the 1988 through 1995 incident records.
- The preliminary taxonomy and classification results were published in 1997.6
- A series of workshops was conducted from 1997 through 1998 (the Common Language Project) to make improvements to the taxonomy and to add additional terms.
- The results of the workshops (the “common language for security incidents”) were first published in 1998.
A taxonomy is a classification scheme (a structure) that partitions a body of knowledge and defines the relationship of the pieces.7 Most of the terms in this common language for security incident information are arranged in such a taxonomy, as presented in the next section. Classification is the process of using a taxonomy for separating and ordering. As discussed earlier, classification of information using a taxonomy is necessary for computer security incident information because of the rapidly expanding amount of information and the nature of that information (primarily text). Classification using the common-language taxonomy is discussed in the final section of this chapter.
Our experience has shown that satisfactory taxonomies have classification categories with these six characteristics:8
- Mutually exclusive. Classifying in one category excludes all others because categories do not overlap.
- Exhaustive. Taken together, the categories include all possibilities.
- Unambiguous. The taxonomy is clear and precise, so that classification is not uncertain, regardless of who is doing the classifying.
- Repeatable. Repeated applications result in the same classification, regardless of who is doing the classifying.
- Accepted. It is logical and intuitive, so that categories can become generally approved.
- Useful. The taxonomy can be used to gain insight into the field of inquiry.
These characteristics were used to develop and evaluate the common-language taxonomy. A taxonomy, however, is merely an approximation of reality, and as such, even the best taxonomy will fall short in some characteristics. This may be especially true when the characteristics of the data being classified are imprecise and uncertain, as is typical for computer security incident information. Nevertheless, classification is an important, useful, and necessary prerequisite for systematic study of incidents.
8.4 COMPUTER SECURITY INCIDENT INFORMATION TAXONOMY.
We have been able to structure most of the terms in the common language for security incident information into a taxonomy. These terms and the taxonomy are presented in this section. Additional terms that describe the more general aspects of incidents are presented in Section 8.5.
8.4.1 Events.
The operation of computers and networks involves innumerable events. In a general sense, an event is a discrete change of state or status of a system or device.9 From a computer security viewpoint, these changes of state result from actions that are directed against specific targets. An example is a user taking action to log in to the user's account on a computer system. In this case, the action taken by the user is to authenticate to the login program by claiming to have a specific identity and then presenting the required verification. The target of this action would be the user's account. Other examples include numerous actions that can be targeted toward:
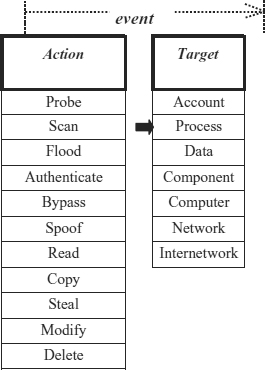
EXHIBIT 8.1 Computer and Network Events
- Data (e.g., actions to read, copy, modify, steal, or delete)
- A process (e.g., actions to probe, scan, authenticate, bypass, or flood a running computer process or execution thread)
- A component, computer, network, or internetwork (e.g., actions to scan or steal)
Exhibit 8.1 presents a matrix of actions and targets that represent possible computer and network events (although not all of the possible combinations shown are feasible). A computer or network event is defined as:
Event—action directed at a target that is intended to result in a change of state, or status, of the target.10
Several aspects of this definition are important to emphasize. First, in order for there to be an event, there must be an action that is taken, and it must be directed against a target, but the action does not have to succeed in actually changing the state of the target. For example, if a user enters an incorrect user name and password combination when logging in to an account, an authentication event has taken place, but the event was not successful in verifying that the user has the proper credentials to access that account.
A second important aspect is that an event represents a practical linkage between an action and a specific target against which the action is directed. As such, it represents the way people generally conceptualize events on computers and networks, and not all of the individual steps that actually take place during an event. For example, when a user logs in to an account, we classify the action as authenticate and the target as account. The actual action that takes place is for the user to access a process (e.g., a “login” program) in order to authenticate. Trying to depict all of the individual steps is an unnecessary complication; the higher-level concepts presented here can describe correctly and accurately the event in a form well understood by people. In other words, it makes sense to abstract the language and its structure to the level at which people generally conceptualize the events.
By all means, supporting evidence should be presented so the evidence provides a complete idea of what happened. Stated another way, abstraction, conceptualization, and communication should be applied as close to the evidence as possible. For example, if a network switch is the target of an attack, then the target should normally be viewed as a computer or as a component (depending on the nature of the switch), and not the network, because assuming the network is the target may be an inaccurate interpretation of the evidence.
Another aspect of the definition of event is that it does not make a distinction between authorized and unauthorized actions. Most events that take place on computers or networks are both routine and authorized and, therefore, are not of concern to security professionals. Sometimes, however, an event is part of an attack or is a security concern for some other reason. This definition of event is meant to capture both authorized and unauthorized actions. For example, if a user authenticates properly, by giving the correct user identification and password combination while logging in to an account, that user is given access to that account. It may be the case, however, that this user is masquerading as the actual user, after having obtained the user identification and password from snooping on the network. Either way, this is still considered authentication.
Finally, an important aspect of events is that not all of the possible events (the action–target combinations depicted in Exhibit 8.1) are considered likely or even possible. For example, an action to authenticate is generally associated with an account or a process and not a different target, such as data or a component. Other examples include read and copy, which are generally targeted toward data; flooding, which is generally targeted at an account, process, or system; or stealing, which is generally targeted against data, a component, or a computer.
We define action and target as follows:
Action—step taken by a user or process in order to achieve a result,11 such as to probe, scan, flood, authenticate, bypass, spoof, read, copy, steal, modify, or delete.
Target—computer or network logical entity (account, process, or data) or a physical entity (component, computer, network or internetwork).
8.4.1.1 Actions.
The actions depicted in Exhibit 8.1 represent a spectrum of activities that can take place on computers and networks. An action is a step taken by a user or a process in order to achieve a result. Actions are initiated by accessing a target, where access is defined as:
Access—establish logical or physical communication or contact.12
Two actions are used to gather information about targets: probe and scan. A probe is an action to determine one or more characteristics of a specific target. This is unlike a scan, which is an action where a user or process accesses a set of targets systematically, in order to determine which targets have one or more characteristics.
“Probe” and “scan” are terms commonly used by incident response teams. As a result, they have common, accepted definitions. Despite this, there is a logical ambiguity:
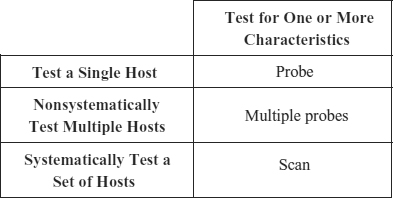
EXHIBIT 8.2 Probe Compared to Scan
A scan could be viewed as multiple probes. In other words, if an attacker is testing for one or more characteristics on multiple hosts, this can be (a) multiple attacks (all probes), or (b) one attack (a scan). This point was discussed extensively in the Common Language Project workshops, and the conclusion was that the terms in the common language should match, as much as possible, their common usage. This common usage is illustrated in Exhibit 8.2.
With probes and scans, it is usually obvious what is taking place. The attacker is either “hammering away” at one host (a probe), randomly testing many hosts (multiple probes), or using some “automatic” software to look for the same characteristic(s) systematically across a group of hosts (a scan). As a practical matter, incident response teams do not usually have a problem deciding what type of action they are dealing with.
One additional point about scan is that the term “systematic” is not meant to specify some specific pattern. The most sophisticated attackers try to disguise the systematic nature of a scan. A scan may, at first, appear to be multiple probes. For example, an attacker may randomize a scan with respect to hosts and with respect to the characteristic(s) being tested. If the attack can be determined to involve testing of one or more characteristics on a group of hosts with some common property (e.g., an Internet Protocol [IP] address range) or if tests on multiple hosts appear to be otherwise related (e.g., having a common origin in location and time), then the multiple probes should be classified as a scan.
Unlike probe or scan, an action taken to flood a target is not used to gather information about the target. Instead, the desired result of a flood is to overwhelm or overload the target's capacity by accessing the target repeatedly. An example is repeated requests to open connections to a port over a network or repeated requests to initiate processes on a computer. Another example is a high volume of e-mail messages, which may exceed the resources available for the targeted account.
Authenticate is an action taken by a user to assume an identity. Authentication starts with a user accessing an authentication process, such as a login program. The user must claim to have a certain identity, such as by entering a user name. Usually verification is also required as a second authentication step. For verification, the user must prove knowledge of some secret (e.g., a password), prove the possession of some token (e.g., a secure identification card), and/or prove to have a certain characteristic (e.g., a retinal scan pattern). Authentication can be used not only to log in to an account but also to access other objects, such as to operate a process or to access a file. In other words, the target of an authentication action is the entity (e.g., account, process, or data) that the user is trying to access, not the authentication process itself.
Two general methods might be used to defeat an authentication process. First, a user could obtain a valid identification and verification pair that could be used to authenticate, even though it does not belong to that user. For example, during an incident, an attacker might use a process operating on an Internet host computer that captures user name, password, and IP address combinations that are sent in clear text across the Internet. The attacker could then use this captured information to authenticate (log in) to accounts that belong to other users. It is important to note, as mentioned earlier, that this action is still considered authenticate, because the attacker presents valid identification and verification pairs, even though they have been stolen.
The second method that might be used to defeat an authentication process is to exploit a vulnerability in order to bypass the authentication process and access the target. Bypass is an action taken to avoid a process by using an alternative method to access a target. For example, some operating systems have vulnerabilities that an attacker could exploit to gain privileges without actually logging in to a privileged account.
As was discussed with respect to authenticate, an action to bypass does not necessarily indicate that the action is unauthorized. For example, some programmers find it useful to have a shortcut (“back-door”) method to enter an account or run a process, particularly during development. In such a situation, an action to bypass may be considered authorized.
Authenticate and bypass are actions associated with users identifying themselves. In network communications, processes also identify themselves to each other. For example, each packet of information traveling on a network contains addresses identifying both the source and the destination, as well as other information. “Correct” information in these communications is assumed, since it is automatically generated. Thus no action is included on the list to describe this normal situation. Incorrect information could, however, be entered into these communications. Supplying such false information is commonly called an action to spoof. Examples include IP spoofing, mail spoofing, and Domain Name Service (DNS) spoofing.
Spoofing is an active security attack in which one machine on the network masquerades as a different machine….[It] disrupts the normal flow of data and may involve injecting data into the communications link between other machines. This masquerade aims to fool other machines on the network into accepting the imposter as an original, either to lure the other machines into sending it data or to allow it to alter data.13
Some actions are closely associated with data found on computers or networks, particularly with files: read, copy, modify, steal, and delete. There has been some confusion over these terms because their common usage in describing the “physical” world sometimes differs from their common usage describing the “electronic” world. For example, if I say that an attacker stole a computer, then you can assume I mean the attacker took possession of the target (computer) and did not leave an identical computer in that location. If I say, however, that the attacker stole a computer file, what does that actually mean? It is often taken to mean that the attacker duplicated the file and now has a copy, but also it means that the original file is still in its original location. In other words, “steal” sometimes means something different in the physical world than it does in the electronic world.
It is confusing for there to be differences in the meaning of actions in the physical world and the electronic world. Workshop participants attempted to reconcile these differences by carefully defining each term (read, copy, modify, steal, or delete) so it would have a very specific and mutually exclusive meaning that matches the “physical world” meaning as much as possible.
Read is defined as an action to obtain the content of the data contained within a file or other data medium. This action is distinguished conceptually from the actual physical steps that may be required to read. For example, in the process of reading a computer file, the file may be copied from a storage location into the computer's main memory and then displayed on a monitor to be read by a user. These physical steps (copy the file into memory and then onto the monitor) are not part of the abstract concept of read. In other words, to read a target (obtain the content in it), copying of the file is not necessarily required, and it is conceptually not included in our definition of read.
The same separation of concepts is included in the definition of the term “copy.” In this case, we are referring to acquiring a copy of a target without deleting the original. The term “copy” does not imply that the content in the target is obtained, just that a copy has been made and obtained. To get the content, the file must be read. An example is copying a file from a hard disk to a floppy disk. This copying is done by duplicating the original file while leaving the original file intact. A user would have to open the file and look at the content in order to read it.
Copy and read are both different concepts from steal, which is an action that results in the attacker taking possession of the target and the target also becoming unavailable to the original owner or user. This definition agrees with our concepts about physical property, specifically that there is only one object that cannot be copied. For example, if someone steals a car, then that person has deprived the owner of his or her possession. When dealing with property that is in electronic form, such as a computer file, often the term “steal” is used when what actually is meant is copy. The term “steal” specifically means that the original owner or user has been denied access or use of the target. On the other hand, stealing also could mean physically taking a floppy disk that has the file located on it or stealing an entire computer.
Two other actions involve changing the target in some way. The first are actions to modify a target. Examples include changing the content of a file, changing the password of an account, sending commands to change the characteristics of an operating process, or adding components to an existing system. If the target is eliminated entirely, the term “delete” is used to describe the action.
As stated earlier, differences in usage of terms between the physical world and the electronic world are undesirable. As such, we tried to be specific and consistent in our usage. The resulting set of terms is exhaustive and mutually exclusive but goes against the grain in some common usage for the “electronic world,” particularly with respect to the term “steal.” The situation seems unavoidable. Here are some examples that might clarify the terms:
- A user clicks on a link with the browser and sees the content of a web page on the computer screen. We would classify this as a read. While what actually happens is that the content of the page is stored in volatile memory, copied to the cache on the hard drive, and displayed on the screen, from a logical (i.e., user) point of view, the web page has not been copied (nor stolen). Now, if a user copies the content of the web page to a file or prints it out, then the user has copied the web page. Again, this would be a logical classification of the action, from the user's point of view.
- A user duplicates a file that is encrypted. We would classify this as copy, not read. In this case, the file was reproduced, but the content not obtained, so it was not read.
- A user deletes several entries in a password or group file. Should this action be described as several delete actions or as one action to modify? We would describe this action as modify, and the target is data. There is no ambiguity here because of the definition of data. Data are defined to be either a stationary file or a file in transit (see the next section). If a user deletes a line out of the password file, then the file has been modified. The action would be described as delete only if the whole file was deleted. If we had defined data to include part of a file, then we would indeed have an ambiguity.
- A user copies a file and deletes the original. We would classify this as steal. Although the steps actually include a copy followed by a delete, that is the electronic way of stealing a file, and therefore it is more descriptive to describe the action as steal.
In reality, the term “steal” is rarely used (correctly) because attackers who copy files usually do not delete the originals. The term “steal” often is used incorrectly, as in “stealing the source code,” when in fact the correct term is copy.
The list of actions was hashed over in numerous group discussions, off and on, for several years before being put into the common language. Most people who participated in these discussions were not entirely happy with the list, but it is the best we have seen so far. Specifically, the list seems to capture all of the common terms with their common usage (probe, scan, flood, spoof, copy, modify and delete) and the other terms are logical (to the people who participated in the discussion groups) and are necessary to make the action category exhaustive (authenticate, bypass, read and steal).
Here is a summary of our definitions of the actions shown in Exhibit 8.1.
Probe—access a target in order to determine one or more of its characteristics.
Scan—access a set of targets systematically in order to identify which targets have one or more specific characteristics.14
Flood—access a target repeatedly in order to overload the target's capacity.
Authenticate—present an identity to a process and, if required, verify that identity, in order to access a target.15
Bypass—avoid a process by using an alternative method to access a target.16
Spoof—masquerade by assuming the appearance of a different entity in network communications.17
Read—obtain the content of data in a storage device or other data medium.18
Copy—reproduce a target leaving the original target unchanged.19
Steal—take possession of a target without leaving a copy in the original location.
Modify—change the content or characteristics of a target.20
Delete—remove a target or render it irretrievable.21
8.4.1.2 Targets.
Actions are considered to be directed toward seven categories of targets. The first three of these are “logical” entities (account, process, and data), and the other four are “physical” entities (component, computer, network, and internetwork).
In a multiuser environment, an account is the domain of an individual user. This domain includes the files and processes the user is authorized to access and use. A special program that records the user's account name, password, and use restrictions controls access to the user's account. Some accounts have increased or “special” permissions that allow access to system accounts, other user accounts, or system files and processes, and often are called privileged, superuser, administrator, or root accounts.
Sometimes an action may be directed toward a process, which is a program executing on a computer or network. In addition to the program itself, the process includes the program's data and stack, its program counter, stack pointer and other registers, and all other information needed to execute the program.22 The action may then be to supply information to the process or command the process in some manner.
The target of an action may be data that are found on a computer or network. Data are representations of facts, concepts, or instructions in forms that are suitable for use by either users or processes. Data may be found in two forms: files or data in transit. Files are data that are designated by name and considered as a unit by the user or by a process. Commonly we think of files as being located on a storage medium, such as a storage disk, but files also may be located in the volatile or nonvolatile memory of a computer. Data in transit are data being transmitted across a network or otherwise emanating from some source. Examples of the latter include data transmitted between devices in a computer and data found in the electromagnetic fields that surround computer monitors, storage devices, processors, network transmission media, and the like.
Sometimes we conceptualize the target of an action as not being a logical entity (account, process, or data) but rather as a physical entity. The smallest of the physical entities is a component, which is one of the parts that make up a computer or network. A network is an interconnected or interrelated group of computers, along with the appropriate switching elements and interconnecting branches.23 When a computer is attached to a network, it is sometimes referred to as a host computer. If networks are connected to each other, then they are sometimes referred to as an internetwork.
Here is a summary of our definitions of the targets shown in Exhibit 8.1.
Account—domain of user access on a computer or network that is controlled according to a record of information which contains the user's account name, password, and use restrictions.
Process—program in execution, consisting of the executable program, the program's data and stack, its program counter, stack pointer and other registers, and all other information needed to execute the program.24
Data—representations of facts, concepts, or instructions in a manner suitable for communication, interpretation, or processing by humans or by automatic means.25 Data can be in the form of files in a computer's volatile memory or nonvolatile memory, or in a data storage device, or in the form of data in transit across a transmission medium.
Component—one of the parts that make up a computer or network.26
Computer—device that consists of one or more associated components, including processing units and peripheral units, that is controlled by internally stored programs and that can perform substantial computations, including numerous arithmetic operations or logic operations, without human intervention during execution. Note: may be stand-alone or may consist of several interconnected units.27
Network—interconnected or interrelated group of host computers, switching elements, and interconnecting branches.28
Internetwork—network of networks.
8.4.2 Attacks.
Sometimes an event that occurs on a computer or network is part of a series of steps intended to result in something that is not authorized to happen. This event is then considered part of an attack. An attack has three elements.
- It is made up a series of steps taken by an attacker. Among these steps is an action directed at a target (an event, as described in the previous section) as well as the use of some tool to exploit a vulnerability.
- An attack is intended to achieve an unauthorized result as viewed from the perspective of the owner or administrator of the system involved.
- An attack is a series of intentional steps initiated by the attacker. This differentiates an attack from something that is inadvertent.
We define an attack in this way:
Attack—a series of steps taken by an attacker to achieve an unauthorized result.
Exhibit 8.3 presents a matrix of possible attacks, based on our experience. Attacks have five parts that depict the logical steps an attacker must take. An attacker uses a (1) tool to exploit a (2) vulnerability to perform an (3) action on a (4) target in order to achieve an (5) unauthorized result. To be successful, an attacker must find one or more paths that can be connected (attacks), perhaps simultaneously or repeatedly. The first two steps in an attack, tool and vulnerability, are used to cause an event (action directed at a target) on a computer or network. The logical end of a successful attack is an unauthorized result. If the logical end of the previous steps is an authorized result, then an attack has not taken place.
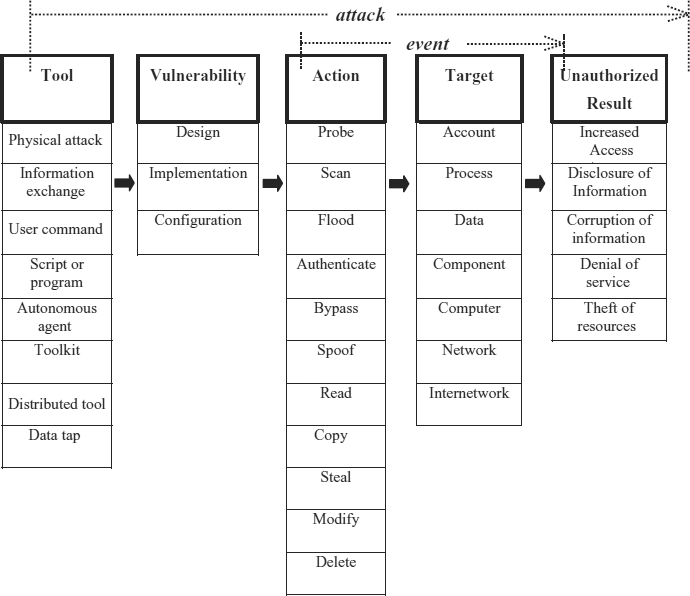
EXHIBIT 8.3 Computer and Network Attacks
The concept of authorized versus unauthorized is key to understanding what differentiates an attack from the normal events that occur. It is also a system-dependent concept in that what may be authorized on one system may be unauthorized on another. For example, some services, such as anonymous File Transfer Protocol (FTP), may be enabled on some systems and not on others. Even actions that are normally viewed as hostile, such as attempts to bypass access controls to gain entry into a privileged account, may be authorized in special circumstances, such as during an approved test of system security, or in the use of a “back door” during development. System owners or their administrators make the determination of what actions they consider authorized for their systems by establishing a security policy.29 Here are the definitions for authorized and unauthorized.
Authorized—approved by the owner or administrator.
Unauthorized—not approved by the owner or administrator.
The steps action and target in Exhibit 8.1 are the two parts of an event as discussed in Section 8.4.1. The following sections discuss the other steps: tool, vulnerability, and unauthorized result.
8.4.2.1 Tool.
The first step in the sequence that leads attackers to their unauthorized results is the tool used in the attack. A tool is some means that can be used to exploit a vulnerability in a computer or network. Sometimes a tool is simple, such as a user command or a physical attack. Other tools can be very sophisticated and elaborate, such as a Trojan horse program, computer virus, or distributed tool. We define tool in this way.
Tool—means of exploiting a computer or network vulnerability
The term “tool” is difficult to define more specifically because of the wide variety of methods available to exploit vulnerabilities in computers and networks. When authors make lists of methods of attack, often they are actually making lists of tools. Based on our experience, these categories of tools are currently an exhaustive list. (See Exhibit 8.3)
Physical attack—means of physically stealing or damaging a computer, network, its components, or its supporting systems (e.g., air conditioning, electric power, etc.).
Information exchange—means of obtaining information either from other attackers (e.g., through an electronic bulletin board) or from the people being attacked (commonly called social engineering).
User command—means of exploiting a vulnerability by entering commands to a process through direct user input at the process interface. An example is entering UNIX commands through a telnet connection or commands at a protocol's port.
Script or program—means of exploiting a vulnerability by entering commands to a process through the execution of a file of commands (script) or a program at the process interface. Examples are a shell script to exploit a software bug, a Trojan horse log-in program, or a password-cracking program.
Autonomous agent—means of exploiting a vulnerability by using a program or program fragment that operates independently from the user. Examples are computer viruses or worms.
Toolkit—software package that contains scripts, programs, or autonomous agents that exploit vulnerabilities. An example is the widely available toolkit called rootkit.
Distributed tool—tool that can be distributed to multiple hosts, which then can be coordinated to anonymously perform an attack on the target host simultaneously after some time delay.
Data tap—means of monitoring the electromagnetic radiation emanating from a computer or network using an external device.
With the exception of the physical attack, information exchange, and data tap categories, each of the tool categories may contain the other tool categories within itself. For example, toolkits contain scripts, programs, and sometimes autonomous agents. So when a toolkit is used, the script or program category is also included. User commands also must be used for the initiation of scripts, programs, autonomous agents, toolkits, and distributed tools. In other words, there is an order to some of the categories in the tools block, from the simple user command category to the more sophisticated distributed tools category. In describing or classifying an attack, generally a choice must be made among several alternatives within the tools block. We chose to classify according to the highest category of tool used, which makes the categories mutually exclusive in practice.
8.4.2.2 Vulnerability.
To reach the desired result, an attacker must take advantage of a computer or network vulnerability.
Vulnerability—weakness in a system allowing unauthorized action.30
A vulnerability in software is an error that arises in different stages of development or use.31 This definition can be used to give us three categories of vulnerabilities.
Design vulnerability—vulnerability inherent in the design or specification of hardware or software whereby even a perfect implementation will result in a vulnerability.
Implementation vulnerability—vulnerability resulting from an error made in the software or hardware implementation of a satisfactory design.
Configuration vulnerability—vulnerability resulting from an error in the configuration of a system, such as having system accounts with default passwords, having “world write” permission for new files, or having vulnerable services enabled.32
8.4.2.3 Unauthorized Result.
As shown in Exhibit 8.3, the logical end of a successful attack is an unauthorized result. At this point, an attacker has used a tool to exploit a vulnerability in order to cause an event to take place.
Unauthorized result—unauthorized consequence of an event. If successful, an attack will result in one of the following:33
Increased access—unauthorized increase in the domain of access on a computer or network.
Disclosure of information—dissemination of information to anyone who is not authorized to access that information.
Corruption of information—unauthorized alteration of data on a computer or network.
Denial of service—intentional degradation or blocking of computer or network resources.
Theft of resources—unauthorized use of computer or network resources.
8.4.3 Full Incident Information Taxonomy.
Often attacks on computers and networks occur in a distinctive group that we would classify as being part of one incident. What makes these attacks a distinctive group is a combination of three factors, each of which we may only have partial information about.
- There may be one attacker, or there may be several attackers who are related in some way.
- The attacker(s) may use similar attacks, or they may be trying to achieve a distinct or similar objective.
- The sites involved in the attacks and the timing of the attacks may be the same or may be related.
Here is the definition of incident:
Incident—group of attacks that can be distinguished from other attacks because of the distinctiveness of the attackers, attacks, objectives, sites, and timing.
The three parts of an incident are shown in simplified form in Exhibit 8.4, which shows that an attacker, or group of attackers, achieves objectives by performing attacks. An incident may be comprised of one single attack or may be made of multiple attacks, as illustrated by the return loop in the figure.
Exhibit 8.5 shows the full incident information taxonomy. It shows the relationship of events to attacks and attacks to incidents, and suggests that preventing attackers from achieving objectives could be accomplished by ensuring that an attacker cannot make any complete connections through the seven steps depicted. For example, investigations could be conducted of suspected terrorist attackers, systems could be searched periodically for attacker tools, system vulnerabilities could be patched, access controls could be strengthened to prevent actions by an attacker to access a targeted account, files could be encrypted so as not to result in disclosure, and a public education program could be initiated to prevent terrorists from achieving an objective of political gain.
8.4.3.1 Attackers and Their Objectives.
People attack computers. They do so through a variety of methods and for a variety of objectives. What distinguishes the categories of attackers is a combination of who they are and their objectives (what they want to accomplish).

EXHIBIT 8.4 Simplified Computer and Network Incident
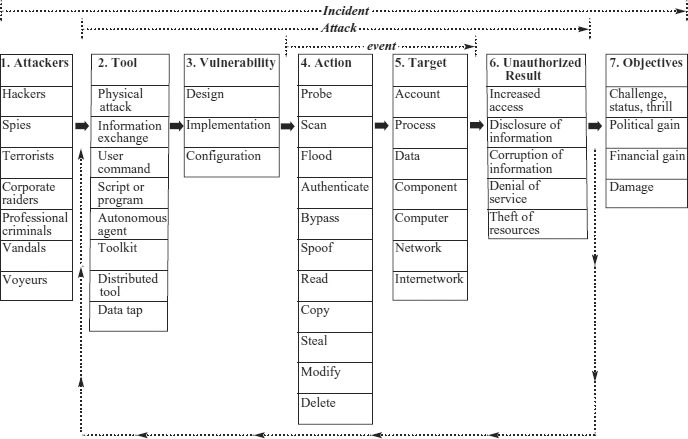
EXHIBIT 8.5 Computer and Network Incident Information Taxonomy
Attacker—individual who attempts one or more attacks in order to achieve an objective.
Objective—purpose or end goal of an incident.
Based on their objectives, we have divided attackers into a number of categories:
Hackers—attackers who attack computers for challenge, status, or the thrill of obtaining access. (Note: We have elected to use the term “hacker” because it is common and widely understood. We realize that the term's more positive connotation was once more widely accepted.)
Spies—attackers who attack computers for information to be used for political gain.
Terrorists—attackers who attack computers to cause fear, for political gain.
Corporate raiders—employees (attackers) who attack competitors' computers for financial gain.
Professional criminals—attackers who attack computers for personal financial gain.
Vandals—attackers who attack computers to cause damage.
Voyeurs—attackers who attack computers for the thrill of obtaining sensitive information.
These seven categories of attackers and their four categories of objectives as shown in the leftmost and rightmost blocks of Exhibit 8.5 are fundamental to the difference between incidents and attacks. This difference is summed up in the phrase “attackers use attacks to achieve objectives.”
8.5 ADDITIONAL INCIDENT INFORMATION TERMS.
The taxonomy of the last section presented all of the terms in the common language for computer security that describe how attackers achieve objectives during an incident. However, some other, more general terms are required to fully describe an incident. The next sections discuss these terms.
8.5.1 Success and Failure.
Information on success or failure can be recorded at several levels in the overall taxonomy. In the broadest sense, overall success or failure is an indication of whether one or more attackers have achieved one or more objectives. A narrower focus would be to determine the success or failure of an individual attack by evaluating whether the attack leads to an unauthorized result. Information on success or failure, however, may simply not be known. For example, an attempt to log in to the root or superuser account on a system may be classified as a success a failure, or as being unknown.
8.5.2 Site and Site Name.
“Site” is the common term used to identify Internet organizations as well as physical locations. A “site” is also the organizational level of the site administrator or other authority with responsibility for the computers and networks at that location.
The term “site name” refers to a portion of the fully qualified domain name in the Internet's Domain Name Service (DNS). For sites in the United States, site names generally are at the second level of the DNS tree. Examples would be cmu.edu or widgets.com. In other countries, the site name is the third or lower level of the DNS tree, such as widgets.co.uk. Some site names occur even farther down the DNS tree. For example, a school in Colorado might have a site name of myschool.k12.co.us.
Here are the definitions of site and site name.
Site—organizational level with responsibility for security events; the organizational level of the site administrator or other authority with responsibility for the computers and networks at that location.
Site name—portion of the fully qualified domain name that corresponds to a site.
Some organizations, such as larger universities and companies, are large enough to be physically divided into more than one location, with separate administration. This separation cannot easily be determined. Therefore, often these different locations must be treated as one site.
8.5.3 Other Incident Terms.
Several additional terms are necessary to fully describe actual Internet incidents. The first of these terms concern dates.
Reporting date—first date that the incident was reported to a response team or other agency or individuals collecting data.
Starting date—date of the first known incident activity.
Ending date—date of the last known incident activity.
Several terms concern the sites involved.
Number of sites—overall number of sites known to have reported or otherwise to have been involved in an incident.
Reporting sites—site names of sites known to have reported an incident.
Other sites—site names of sites known to have been involved in an incident but that did not report the incident.
For most incident response teams, actual site names are considered sensitive information. In our research, in order to protect the identities of the sites associated with an incident, we sanitize the site information by coding the site names prior to public release. An example would be to replace a site name, such as the fictitious widgets.com, with numbers and the upper-level domain name, such as 123.com.
Response teams often use incident numbers to track incidents and to identify incident information.
Incident number—reference number used to track an incident or identify incident information.
The last term we found to be of use is corrective action, which indicates those actions taken in the aftermath of an incident. These actions could include changing passwords, reloading systems files, talking to the intruders, or even criminal prosecution. Information on corrective actions taken during or after an incident is difficult to obtain for incident response teams, since response team involvement generally is limited to the early stages of an incident. CERT/CC records indicate that the variety of corrective actions is extensive, and a taxonomy of corrective actions may be a desirable future expansion of the common language.
Corrective action—action taken during or after an incident to prevent further attacks, repair damage, or punish offenders.
8.6 HOW TO USE THE COMMON LANGUAGE.
Two things are important to emphasize about using the common language for computer security incident information. First, the common language really is a “high-level” set of terms. As such, it will not settle all the disputes about everything discussed concerning computer security incidents. For example, the common language includes “autonomous agent” as a term (a category of tool). Autonomous agents include computer viruses, worms, and the like, regardless of how those specific terms might be defined. In other words, the common language does not try to settle disputes on what should or should not be considered a computer virus but rather deals at a higher level of abstraction (autonomous agent) where, it is hoped, there can be more agreement and standardization. Stated another way, participants in the Common Language Project workshops anticipated that individuals and organizations would continue to use their own terms, which may be more specific in both meaning and use. The common language has been designed to enable these “lower-level” terms to be classified within the common language structure.
The second point to emphasize is that the common language, even though it presents a taxonomy, does not classify an incident (or individual attacks) as any one thing. Classifying computer security attacks or incidents is difficult because attacks and incidents are a series of steps that an attacker must take. In other words, attacks and incidents are not just one thing but rather a series of things. That is why I say the common language provides a taxonomy for computer security incident information.
An example of the problem is found in the popular and simple taxonomies often used to attempt to classify incidents. They appear as a list of single, defined terms. The following terms from Icove, Seger, and VonStorch provide an example.34

Lists of terms are not satisfactory taxonomies for classifying actual attacks or incidents. They fail to have most of the six characteristics of a satisfactory taxonomy. First, the terms tend not to be mutually exclusive. For example, the terms “virus” and “logic bomb” are generally found on these lists, but a virus may contain a logic bomb, so the categories overlap. Actual attackers generally also use multiple methods so their attacks would have to be classified into multiple categories. This makes classification ambiguous and difficult to repeat.
A more fundamental problem is that, assuming that an exhaustive and mutually exclusive list could be developed, the taxonomy would be unmanageably long and difficult to apply. It also would not indicate any relationship between different types of attacks. Finally, none of these lists has become widely accepted, partly because it is difficult to agree on the definition of terms. In fact, many different definitions of terms are in common use.
The fundamental problems with these lists (and their variations) are that most incidents involve multiple attacks, and attacks involve multiple steps. As a result, information about the typical incident must be classified in multiple categories. For example, one of the attacks in an incident might be a flood of a host resulting in a denial of service. But this same incident might involve the exploitation of a vulnerability to compromise the host computer that was the specific origin of the flood. Should this be classified as a flood? As a root compromise? As a denial-of-service attack? In reality, the incident should be classified in all of these categories. In other words, this incident has multiple classifications.
In summary, in developing the common language, we have found that, with respect to attacks and incidents, we can really only hope to (1) present a common set of “high-level” terms that are in general use and have common definitions and (2) present a logical structure to the terms that can be used to classify information about an incident or attack with respect to specific categories.
Some examples may make this clear. As discussed earlier, most of the information about actual attacks and incidents is in the form of textual records. In a typical incident record at the CERT/CC, three observations might be reported:
- We found rootkit on host xxx.xxx.
- A flood of e-mail was sent to account [email protected], which crashed the mail server.
- We traced the attack back to a teenager in Xyz city, who said he was not trying to cause any damage, just to see if he could break in.
For observation 1, we would classify rootkit in the “toolkit” category under “Tool” and the hostname in the “computer” category under “Target.” For observation 2, the “e-mail flood” is a specific instantiation in the “flood” category under “Action” as well as in the “denial-of-service” category under “Unauthorized Result.” There is ambiguity as to the target for observation 2: Is it the account or the computer? As a practical matter, the observations would be classified as both, since information is available on both. For observation 3, it could be inferred that this is a “hacker” seeking “challenge, status, or thrill.”
What does this taxonomic process provide that is of practical value? First, the taxonomy helps us communicate to others what we have found. When we say that rootkit is a type of toolkit, then our common set of terms (“common language”) provides us the general understanding of what we mean. When it is said that 22 percent of incidents reported to CERT/CC from 1988 through 1995 involved various problems with passwords (a correct statistic35), then the taxonomy has proven useful in communicating valuable information.
The application of the taxonomy, in fact, is a four-step process that can be used to determine what are the biggest security problems. Specifically, the process is to:
- Take observations from fragmentary information in incident reports.
- Classify those observations.
- Perform statistical studies of these data.
- Use this information to determine the best course(s) of action.
Over time, the same process can be used to determine the effects of these actions.
Two more points are important to emphasize about this taxonomy. First, an attack is a process that, with enough information, is always classified in multiple categories. For example: in a “Tool” category, in a “Vulnerability” category, in an “Action” category, in a “Target” category, and in an “Unauthorized Result” category. Second, an incident can involve multiple, perhaps thousands, of attacks. As such, the information gathered in an incident theoretically could be classified correctly into all of the taxonomy categories.
Within these guidelines, the common language for computer security incidents has proven to be a useful and increasingly accepted tool to gather, exchange, and compare computer security information. The taxonomy itself has proven to be simple and straightforward to use.
8.7 NOTES
1. E. G. Amoroso, Fundamentals of Computer Security Technology (Upper Saddle River, NJ: Prentice-Hall PTR, 1994), p. 2.
2. Deborah Russell and G. T. Gangemi Sr., Computer Security Basics (Sebastopol, CA: O'Reilly & Associates, 1991), p. 79.
3. Bill McKelvey, Organization Systematics: Taxonomy, Evolution, Classification (Berkeley: University of California Press, 1982), p. 3.
4. John D. Howard, “An Analysis of Security Incidents on the Internet, 1989–1995” (PhD diss., Department of Engineering and Public Policy, Carnegie Mellon University, Pittsburgh, PA, April 1997). Also available online at www.cert.org/research/JHThesis/Start.html.
5. Ivan Victor Krsul, “Software Vulnerability Analysis” (PhD diss., Computer Sciences Department, Purdue University, Lafayette, IN, May 1998), p. 12.
6. Howard, “Analysis of Security Incidents on the Internet.”
7. John Radatz, ed., The IEEE Standard Dictionary of Electrical and Electronics Terms, 6th ed. (New York: Institute of Electrical and Electronics Engineers, 1996), p. 1087.
8. Amoroso, Fundamentals of Computer Security Technology, p. 34.
9. Radatz, IEEE Standard Dictionary, p. 373.
10. Radatz, IEEE Standard Dictionary, p. 373.
11. Radatz, IEEE Standard Dictionary, p. 11.
12. Radatz, IEEE Standard Dictionary, p. 5.
13. Derek Atkins et al., Internet Security Professional Reference (Indianapolis: New Riders Publishing, 1996), p. 258.
14. Radatz, IEEE Standard Dictionary, p. 947, and K. M. Jackson and J. Hruska, eds., Computer Security Reference Book (Boca Raton, FL: CRC Press, 1992), p. 916.
15. Merriam-Webster, Merriam-Webster's Collegiate Dictionary, 10th ed. (Springfield, MA: Author, 1996), pp. 77, 575, 714, and Radatz, IEEE Standard Dictionary, p. 57.
16. Merriam-Webster's Collegiate Dictionary, p. 157.
17. Radatz, IEEE Standard Dictionary, p. 630, and Atkins et al., Internet Security, p. 258.
18. Radatz, IEEE Standard Dictionary, p. 877.
19. Radatz, IEEE Standard Dictionary, p. 224.
20. Radatz, IEEE Standard Dictionary, p. 661.
21. Radatz, IEEE Standard Dictionary, p. 268.
22. Andrew S. Tanenbaum, Modern Operating Systems (Englewood Cliffs, NJ: Prentice-Hall, 1992), p. 12.
23. Radatz, IEEE Standard Dictionary, p. 683.
24. Tanenbaum, Modern Operating Systems, p. 12, and Radatz, IEEE Standard Dictionary, p. 822.
25. Radatz, IEEE Standard Dictionary, p. 250.
26. Radatz, IEEE Standard Dictionary, p. 189.
27. Radatz, IEEE Standard Dictionary, p. 192.
28. Radatz, IEEE Standard Dictionary, p. 683.
29. Krsul, “Software Vulnerability Analysis”, pp. 5–6.
30. National Research Council, Computers at Risk: Safe Computing in the Information Age (Washington, DC: National Academy Press, 1991), p. 301; and Amoroso, Fundamentals of Computer Security Technology, p. 2.
31. Krsul, Software Vulnerability Analysis, pp. 10–11.
32. Atkins et al., Internet Security, p. 196.
33. Amoroso, Fundamentals of Computer Security Technology, pp. 3–4, 31; Russell and Gangemi, Computer Security Basics, pp. 9–10; and Frederick B. Cohen, Protection and Security on the Information Superhighway (New York: John Wiley & Sons, 1995), pp. 55–56.
34. David Icove, Karl Seger, and William VonStorch, Computer Crime: A Crime-fighter's Handbook (Sebastopol, CA: O'Reilly & Associates, 1995), pp. 31–52; Cohen, Protection and Security on the Information Superhighway, pp. 40–54 (39 terms); and Frederick B. Cohen, “Information System Attacks: A Preliminary Classification Scheme,” Computers and Security 16, No. 1 (1997): 29–46 (96 terms).
35. Howard, “Analysis of Security Incidents on the Internet”, p. 100.