
While it is one thing to compile bytecodes to native code and have it executed within the JVM, getting it to run as efficiently as possible is a different story. This is where 40 years of research into compilers is useful, along with some insight into the Java language. This section discusses how a JIT compiler can turn bytecode into efficient native code.
A compiler for a programming language typically starts out with source code, such as C++. A Java JIT compiler, in a JVM, is different in the way that it has to start out with Java bytecode, parts of which are quite low level and assembly-like. The JIT compiler frontend, similar to a C++ compiler frontend, can be reused on all architectures, as it's all about tokenizing and understanding a format that is platform-independent—bytecode.
While compiled bytecode may sound low level, it is still a well-defined format that keeps its code (operations) and data (operands and constant pool entries) strictly separated from each other. Parsing bytecode and turning it into a program description for the compiler frontend actually has a lot more in common with compiling Java or C++ source code, than trying to deconstruct a binary executable. Thus, it is easier to think of bytecode as just a different form of source code—a structured program description. The bytecode format adds no serious complexities to the compiler frontend compared to source code. In some ways, bytecode helps the compiler by being unambiguous. Types of variables, for instance, can always be easily inferred by the kind of bytecode instruction that operates on a variable.
However, bytecode also makes things more complex for the compiler writer. Compiling byte code to native code is, somewhat surprisingly, in some ways harder than compiling human-readable source code.
One of the problems that has to be solved is the evaluation stack metaphor that the Java Virtual Machine specification mandates. As we have seen, most bytecode operations pop operands from the stack and push results. No native platforms are stack machines, rather they rely on registers for storing intermediate values. Mapping a language that uses local variables to native registers is straightforward, but mapping an evaluation stack to registers is slightly more complex. Java also defines plenty of virtual registers, local variables, but uses an evaluation stack anyway. It is the authors' opinion that this is less than optimal. One might argue that it is strange that the virtual stack is there at all, when we have plenty of virtual registers. Why isn't an add operation implemented simply as "x = y+z" instead of "push y, push z, add, pop x". Clearly the former is simpler, given that we have an ample supply of registers.
It turns out that as one needs to compile bytecodes to a native code, the stack metaphor often adds extra complexity. In order to reconstruct an expression, such as add, the contents of the execution stack must be emulated at any given point in the program.
Another problem, that in rare cases may be a design advantage, is the ability of Java bytecodes to express more than Java source code. This sounds like a good thing when it comes to portability—Java bytecode is a mobile format executable by any JVM. Wouldn't it make sense to decouple the Java source code from the bytecode format so that one might write Java compilers for other languages that in turn can run on Java Virtual Machines? Of course it would, and it was probably argued that this would further help the spread and adoption of Java early in its design stage. However, for some reason or other, auto-generated bytecode from foreign environments is rarely encountered. A small number of products that turn other languages into Java bytecode exist, but they are rarely used. It seems that when the need for automatic bytecode generation exists, the industry prefers to convert the alien source code to Java and then compile the generated Java code. Also, when auto generated Java code exists, it tends to conform pretty much to the structure of compiled Java source code.
Note
The problem that bytecode can express more than Java has led to the need for bytecode verification in the JVM, a requirement defined by the Java Virtual Machine specification. Each JVM implementation needs to check that the bytecode of an executing program does no apparently malicious tricks, such as jumping outside the method, overflowing the evaluation stack, or creating recursive subroutines.
Though bytecode portability and cross compiling several languages to bytecode is potentially a good thing, it also leads to problems. This is especially because bytecode allows unstructured control flow. Control flow with gotos to arbitrary labels is available in bytecode, which is not possible in the Java language. Therefore, it is possible to generate bytecodes that have no Java source code equivalent.
Allowing bytecodes that have no Java equivalent can lead to some other problems. For example, how would a Java source code debugger handle bytecode that cannot be decompiled into Java?
Consider the following examples:
- In bytecode, it is conceivable to create a
gotothat jumps into the body of a loop from before the loop header (irreducible flow graphs). This construct is not allowed in Java source code. Irreducible flow graphs are a classic obstacle for an optimizing compiler. - It is possible to create a
tryblock that is its owncatchblock. This is not allowed in Java source code. - It is possible to take a lock in one method and release it in another method. This is not allowed in Java source code and will be discussed further in Chapter 4.
The problem of bytecode expressing more than source code is even more complex. Through the years, various bytecode obfuscators have been sold with promises of "protecting your Java program from prying eyes". For Java bytecode this is mostly a futile exercise because, as we have already discussed, there is a strict separation between code and data. Classic anti-cracking techniques are designed to make it hard or impossible for adversaries to find a sensitive place in a program. Typically, this works best in something like a native binary executable, such as an .exe file, where distinctions between code and data are less clear. The same applies to an environment that allows self-modifying code. Java bytecode allows none of these. So, for a human adversary with enough determination, any compiled Java program is more vulnerable by design.
Bytecode obfuscators use different techniques to protect bytecode. Usually, it boils down to name mangling or control flow obfuscation.
Name mangling means that the obfuscator goes over all the variable info and field and method names in a Java program, changing them to short and inexplicable strings, such as a, a_, and a__ (or even more obscure Unicode strings) instead of getPassword, setPassword, and decryptPassword. This makes it harder for an adversary to crack your program, since no clues can be gleaned from method and field names. Name mangling isn't too much of a problem for the compiler writer, as no control flow has been changed from the Java source code.
It is more problematic if the bytecode obfuscator deliberately creates unstructured control flow not allowed in Java source code. This technique is used to prevent decompilers from reconstructing the original program. Sadly though, obfuscated control flow usually leads to the compiler having to do extra work, restructuring the lost control flow information that is needed for optimizations. Sometimes it isn't possible for the JVM to do a proper job at all, and the result is lowered performance. Thus control flow obfuscation should be avoided.
Various bytecode "optimizers" are also available in the market. They were especially popular in the early days of Java, but they are still encountered from time to time. Bytecode "optimizers" claim performance through restructuring bytecodes into more "efficient" forms. For example, divisions with powers of two can be replaced by shifts, or a loop can be inverted, potentially saving a goto instruction.
In modern JVMs, we have failed to find proof that "optimized" bytecodes are superior to unaltered ones straight out of javac. A modern JVM has a code generator well capable of doing a fine job optimizing code, and even though bytecode may look low level, it certainly isn't to the JVM. Any optimization done already at the bytecode level is likely to be retransformed into something else several times over on the long journey to native code.
We have never seen a case where a customer has been able to demonstrate a performance benefit from bytecode optimization. However, we have frequently run into customer cases where the program behavior isn't the expected one and varies between VMs because of failed bytecode optimization.
Our advice is to not use bytecode optimizers, ever!
As we have seen, Java bytecode has its advantages and disadvantages. The authors find it helpful just to think of bytecode as serialized source code, and not as some low level assembler that needs to run as fast as possible. In an interpreter, bytecode performance matters, but not to a great extent as the interpretation process is so slow anyway. Performance comes later in the code pipeline.
Note
While bytecode is both compact and extremely portable, it suffers from the strength of expression problem. It contains low-level constructs such as gotos and conditional jumps, and even the dreaded jsr (jump to subroutine, used for implementing finally clauses) instruction. As of Java 1.6, however, subroutines are inlined instead by javac and most other Java compilers.
A bytecode to native compiler can't simply assume that the given bytecode is compiled Java source code, but needs to cover all eventualities. A compiler whose frontend reads source code (be it Java, C++, or anything else) usually works by first tokenizing the source code into known constructs and building an Abstract Syntax Tree (AST). Clean ASTs are possible only if control flow is structured and no arbitrary goto instructions exist, which is the case for Java source code. The AST represents code as sequences, expressions, or iterations (loop nodes). Doing an in-order traversal of the tree reconstructs the program. The AST representation has many advantages compared to bytecode.
For example, consider the following method that computes the sum of the elements in an array:
public int add(int [] series) {
int sum = 0;
for (int i = 0; i < series.length; i++) {
sum += series[i];
}
return sum;
}
When turning it to bytecode, the javac compiler most likely creates an abstract syntax tree that looks something like this:
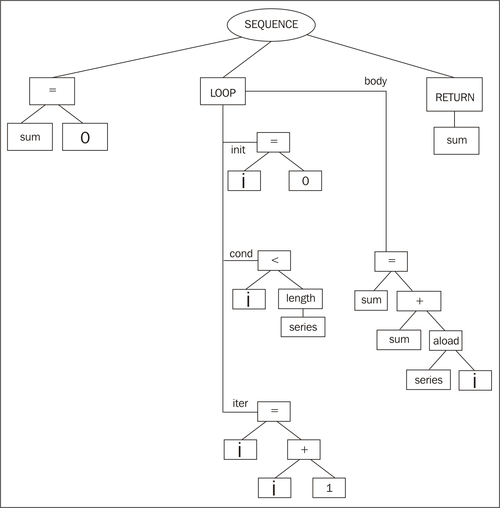
Several important prerequisites for code optimization, such as identifying loop invariants and loop bodies require expensive analysis in a control flow graph. Here, this comes very cheap, as loops are given implicitly by the representation.
However, in order to create the bytecode, the structured for loop, probably already represented as a loop node in the Java compiler's abstract syntax tree, needs to be broken up into conditional and unconditional jumps.
public int add(int[]);
Code:
0: iconst_0
1: istore_2 //sum=0
2: iconst_0
3: istore_3 //i=0
4: iload_3 //loop_header:
5: aload_1
6: arraylength
7: if_icmpge 22 //if (i>=series.length) then goto 22
10: iload_2
11: aload_1
12: iload_3
13: iaload
14: iadd
15: istore_2 //sum += series[i]
16: iinc 3, 1 //i++
19: goto 4 //goto loop_header
22: iload_2
23: ireturn //return sum
Now, without structured control flow information, the bytecode compiler has to spend expensive CPU cycles restructuring control flow information that has been lost, sometimes irretrievably.
Perhaps, in retrospect, it would have been a better design rationale to directly use an encoded version of the compiler's ASTs as bytecode format. Various academic papers have shown that ASTs are possible to represent in an equally compact or more compact way than Java bytecode, so space is not a problem. Interpreting an AST at runtime would also only be slightly more difficult than interpreting bytecode.
Note
The earliest versions of the JRockit JIT used a decompiling frontend. Starting from byte code, it tried to recreate the ASTs present when javac turned source code into bytecode. If unsuccessful, the decompiler fell back to more naive JIT compilation. Reconstructing ASTs, however, turned out to be a very complex problem and the decompiler was scrapped in the early 2000s, to be replaced by a unified frontend that created control flow graphs, able to support arbitrary control flow directly from bytecode.
Programmers tend to optimize their Java programs prematurely. This is completely understandable. How can you trust the black box, the JVM below your application, to do something optimal with such a high-level construct as Java source code? Of course this is partially true, but even though the JVM can't fully create an understanding of what your program does, it can still do a lot with what it gets.
It is sometimes surprising how much faster a program runs after automatic adaptive optimization, simply because the JVM is better at detecting patterns in a very large runtime environment than a human. On the other hand, some things lend themselves better to manual optimization. This book is in no way expressing the viewpoint that all code optimizations should be left to the JVM; however, as we have explained, explicit optimization on the bytecode level is probably a good thing to avoid.
There are plenty of opportunities for writing efficient programs in Java and situations where an adaptive runtime can't help. For example, a JVM can never turn a quadratic algorithm into a linear one, replacing your BubbleSort with a QuickSort. A JVM can never invent its own object cache where you should have written one yourself. These are the kinds of cases that matter in Java code. The JVM isn't magical. Adaptive optimization can never substitute bad algorithms with good ones. At most, it can make the bad ones run a little bit faster.
However, the JVM can easily deal with many constructs in standard object-oriented code. The programmer will probably gain very little by avoiding the declaration of an extra variable or by copying and pasting field loads and stores all over the place instead of calling a simple getter or setter. These are examples of micro-optimizations that make the Java code harder to read and that don't make the JIT compiled code execute any faster.
Note
Sometimes, Java source code level optimizations are downright destructive. All too often people come up with hard-to-read Java code that they claim is optimal because some micro benchmark (where only the interpreter was active and not the optimizing JIT) told them so. An example from the real world is a server application where the programmer did a lot of iterations over elements in arrays. Believing it important to avoid using a loop condition, he surrounded the for loops with a try block and catch clause for the ArrayIndexOutOfBoundsException, that was thrown when the program tried to read outside the array. Not only was the source very hard to read, but once the runtime had optimized the method, it was also significantly slower than a standard loop would have been. This is because exceptions are very expensive operations and are assumed to be just that—exceptions. The "gambling" behavior of the JVM, thinking that exceptions are rare, became a bad fit.
It is all too easy to misunderstand what you are measuring when you are looking for a performance bottleneck. Not every problem can be stripped down into a small self contained benchmark. Not every benchmark accurately reflects the problem that is being examined.Chapter 5 will go into extensive detail on benchmarking and how to know what to look for in Java performance. The second part of this book will cover the various components of the JRockit Mission Control Suite, which is an ideal toolbox for performance analysis.