
Once again, it's time to look inside the JVM. This section covers some of the issues implementing threads and synchronization in a Java runtime. The aim is to provide enough insight and technical background so that the reader will be better equipped to handle parallel constructs and understand how to use synchronization without too much performance loss.
On modern CPU architectures, data caches exist, which is a necessary mechanism for speeding up data access for loads and stores and for reducing contention on the processor bus. As with any cache mechanism, invalidation issues are a problem, especially on multiprocessor systems where we often get the situation that two processors want to access the same memory at the same time.
A memory model defines the circumstances under which different CPUs will and won't see the same data. Memory models can be strong (x86 is fairly strong), where multiple CPUs almost automatically see the same, newly stored, data after one of them does a write to memory. In strong memory models, multiple writes to memory locations as good as always occur in the same order as they were placed in the code. Memory models can also be weak (such as IA-64), where there is virtually no guarantee (unless the CPU writing the data executes a special barrier instruction) when field accesses and, more generally, all Java induced memory accesses should be visible to all.
Subtle differences handling read-after-write, write-after-read and write-after-write dependencies of the same data exist on different hardware platforms. Java, being a hardware agnostic language, needs to define strict semantics for how these dependencies should be interpreted for threads in the JVM. This is a complication not present in a static language like C++ that compiles to hardware specific code and lacks a memory model per se. Although there is a volatile keyword in C++ as well as in Java, parts of the C++ program behavior are still impossible to decouple from that of the hardware architecture for which it is compiled. Parts of the "de facto" memory model in a C++ program also reside outside the language itself—in thread libraries and in the semantics of operating system calls. On architectures with weak memory models such as Intel IA-64, the programmer may even have to explicitly put calls to memory barrier functions in the C++ program. Anyway, once compiled, the behavior of the native code generated from the C++ will remain the same within the chosen architecture.
But how can the programmer make sure that the same behavior applies to a compiled Java program, no matter if it is running on x86, Itanium, PowerPC, or SPARC? There are no explicit memory barriers in Java, and probably shouldn't be either, because of its platform independence.
The need for a unified memory model for Java that guarantees identical behavior across different hardware architectures was acknowledged from the start. Java 1.0 through 1.4 implemented the memory model as specified in the original Java Language Specification. However, the first Java Memory Model contained several surprising issues that were counter-intuitive and even made standard compiler optimizations invalid.
The original memory model allowed volatile and non-volatile writes to be reordered interchangeably. Consider the following code:
volatile int x;
int y;
volatile boolean finished;
/* Code executed by Thread 1 */
x = 17;
y = 4711;
finished = true;
/* Thread 1 goes to sleep here */
/* Code executed by Thread 2 */
if (finished) {
System.err.println(x):
System.err.println(y);
}
In the old memory model, the previous code was guaranteed to print out 17, but not necessarily 4711, once Thread 2 was woken up. This had to do with the semantics for volatile. They were clearly defined, but not in relation to non-volatile reads or writes. To a person used to working closer to hardware than a Java programmer, this might not be too surprising, but often Java programmers intuitively expected that constructs like the assignment to finished shown earlier would act as a barrier, and commit all earlier field stores to memory, including the non-volatile ones. The new memory model has enforced stricter barrier behavior for volatile, also with respect to non-volatile fields.
Recollect from our "infinite loop" example in the introduction to volatile earlier in this chapter, that the JIT compiler may optimize code by creating thread local copies of any non-volatile field.
Consider the following code:
int operation(Item a, Item b) {
return (a.value + b.value) * a.value;
}
The compiler might choose to optimize the previous method to the assembly equivalent of:
int operation(Item a, Item b) {
int tmp = a.value;
return (tmp + b.value) * tmp;
}
Notice how two field loads turned into one. Depending on CPU architecture, this will lead to a smaller or larger performance increase if the method is hot. However, it is almost certainly a good idea for the JIT compiler to try to eliminate loads wherever possible, as memory access is always orders of magnitude more expensive than register access. The equivalent optimization is performed by compilers in virtually all statically compiled languages, and not being able to perform it in Java would lead to severe performance loss in comparison.
Originally, through some oversights in the original Java Memory Model, this kind of optimization wasn't guaranteed to be allowed (if it couldn't be proven that a and b were the same object). Luckily, the new Java Memory Model allows this kind of optimization as long as the value field isn't declared volatile. The new memory model allows any thread to keep local copies of non-volatile field values, as was also illustrated with the potentially infinite loop on the field finished earlier in this chapter.
One of the most surprising problems in the original Java Memory Model was that objects that were declared final were sometimes not in fact final (immutable) at all. final objects were defined to require no synchronization, intuitively through their immutability, but there were problems. These manifested themselves to the ordinary user in unexpected ways. A final instance field in a Java object is assigned its one and only value in a constructor, but as all uninitialized fields, it also has an implicit default value (0 or maybe null) before the constructor is run. Without explicit synchronization, the old memory model could allow a different thread to temporarily see this default value of the field before the assignment in the constructor had been committed to memory.
This issue typically led to problems with String instances. A String instance contains a char array with its text, a start offset in the array for where the text begins and a length. All these fields are final and immutable, just like Strings themselves are guaranteed to be in the Java language. So, two String objects can save memory by reusing the same immutable char array. For example, the String"cat" may point out the same char array as the String"housecat", but with a start offset of 5 instead of 0. However, the old memory model would allow the String object for "cat" to be visible with its uninitialized (zeroed) start offsets for a very short period of time, before its constructor was run, basically allowing other threads to think it was spelling out "housecat" very briefly until it became "cat". This clearly violates the immutability of a java.lang.String.
The new memory model has fixed this problem, and final fields without synchronization are indeed immutable. Note that there can still be problems if an object with final fields is badly constructed, so that the this reference is allowed to escape the constructor before it has finished executing.
Redesigning the memory model in Java was done through the Java community process, in Java Specification Request (JSR) 133. It was ready as of Sun's reference implementation of Java 1.5, which was released in 2004. The JSR document itself, and the updated Java Language Specification, are fairly complex, full of precise and formal language. Getting into the details of JSR-133 is beyond the scope of this book. The reader is, however, encouraged to examine the documents, to become a better Java programmer.
Note
There are also several great resources on the Internet about the Java Memory Model that are easier to read. One example is the excellent JSR-133 FAQ by Jeremy Manson and Brian Goetz. Another is Fixing the Java memory Model by Brian Goetz. Both are referenced in the bibliography of this book.
For this text, it suffices to say that JSR-133 cleaned up the problem with reordering fields across volatiles, the semantics of final fields, immutability, and other visibility issues that plagued Java 1.0 through 1.4. Volatiles were made stricter, and consequently, using volatile has become slightly more expensive.
JSR-133 and the new Java Memory Model was a huge step in making sure that intrinsic synchronized semantics were simpler and more intuitive. The intuitive approach to using volatile declarations in Java became the approach that also provided correct synchronization. Of course, a Java programmer may still stumble upon counterintuitive effects of memory semantics in the new memory model, especially if doing something stupid. But the worst unpredictable issues are gone. Maintaining proper synchronization discipline and understanding locks and volatiles will keep the number of synchronization bugs (or races) down to a minimum.
Now that we have covered specification and semantics, we'll see how synchronization is actually implemented, both in Java bytecode and inside the JVM.
On the lowest level, i.e. in every CPU architecture, are atomic instructions which are used to implement synchronization. These may or may not have to be modified in some way. For example on x86, a special lock prefix is used to make instructions maintain atomicity in multiprocessor environments.
Usually, standard instructions such as increments and decrements can be made atomic on most architectures.
A compare and exchange instruction is also commonly available, for atomically and conditionally loading and/or storing data in memory. Compare and exchange examines the contents of a memory location and an input value, and if they are equal, a second input value is written to the memory location. The compare and exchange may write the old memory contents to a destination operand or set a conditional flag if the exchange succeeded. This way, it can be used to branch on. Compare and exchange can, as we shall see later, be used as a fundamental building block for implementing locks.
Another example is memory fence instructions that ensure that reads or writes from memory can be seen by all CPUs after execution of the fence. Fences can be used, for example, to implement Java volatiles by having the compiler insert a fence after each store to a volatile field.
Atomic instructions introduce overhead, as they enforce memory ordering, potentially destroy CPU caches, and disallow parallel execution. So, even though they are a necessary ingredient for synchronization, the runtime should use them with care.
A simple optimization in the JVM is to use atomic instructions as intrinsic calls for various JDK functions. For example, certain calls to java.util.concurrent.atomic methods can be implemented directly as a few inline assembly instructions if the virtual machine is programmed to recognize them. Consider the following code:
import java.util.concurrent.atomic.*;
public class AtomicAdder {
AtomicInteger counter = new AtomicInteger(17);
public int add() {
return counter.incrementAndGet();
}
}
public class AtomicAdder {
int counter = 17;
public int add() {
synchronized(this) {
return ++counter;
}
}
}
Given the first case, the virtual machine knows what is intended and uses an atomic add instruction in the generated code instead of even contemplating generating whatever code is inside AtomicInteger.incrementAndGet. We can do this because java.util.concurrent.AtomicInteger is a system class that is part of the JDK. Its semantics are well defined. In the case without atomics, it is possible, but a little bit harder, to deduce that the synchronization contains a simple atomic add.
Trivially, using synchronization to gain exclusive access to a resource is expensive, as a program that might have been running faster in parallel doesn't anymore. But beside from the obvious issue that the code in a critical section can be run only by one thread at a time, the actual synchronization itself might also add overhead to execution.
On the micro-architecture level, what happens when a locking atomic instruction executes varies widely between hardware platforms. Typically, it stalls the dispatch of the CPU pipeline until all pending instructions have finished executing and their memory writes have been finalized. The CPU also typically blocks other CPUs from the particular cache line with the memory location in the instruction. They continue to be blocked until the instruction has completed. A fence instruction on modern x86 hardware may take a large amount of CPU cycles to complete if it interrupts sufficiently complex multi-CPU execution. From this it can be concluded that not only are too many critical sections in a program bad for performance, but the lock implementation of the platform also matters—especially if locks are frequently taken and released, even for small critical sections.
While any lock may be implemented as a simple OS call to whatever appropriate synchronization mechanism the native platform provides, including one that puts threads to sleep and handles wait queues of monitor objects competing for the lock, one quickly realizes that this one-size-fits-all approach is suboptimal.
What if a lock is never contended and is acquired only a small number of times? Or what if a lock is severely contended and many threads compete for the resource that the particular lock protects? It is once more time to bring the power of the adaptive runtime into play. Before we discuss how the runtime can pick optimal lock implementations for a particular situation, we need to introduce the two fundamental types of lock implementations—thin locks and fat locks.
Thin locks are usually used for fast uncontended locks that are held for a short time only. Fat locks are used for anything more complex. The runtime should be able to turn one kind of lock into the other, depending on the current level of contention.
The simplest implementation of a thin lock is the spinlock. A spinlock spends its time in a while loop, waiting for its monitor object to be released—that is, burning CPU cycles. Typically, a spinlock is implemented with an atomic compare and exchange instruction to provide the basic exclusivity, and a conditional jump back to the compare and exchange if the test failed to acquire the lock.
Following is the pseudocode for a very simple spinlock implementation:
public class PseudoSpinlock {
private static final int LOCK_FREE = 0;
private static final int LOCK_TAKEN = 1;
//memory position for lock, either free or taken
static int lock;
/**
* try to atomically replace lock contents with
* LOCK_TAKEN.
*
* cmpxchg returns the old value of [lock].
* If lock already was taken, this is a no-op.
*
* As long as we fail to set the taken bit,
* we spin
*/
public void lock() {
//burn cycles, or do a yield
while (cmpxchg(LOCK_TAKEN, [lock]) == LOCK_TAKEN);
}
/**
* atomically replace lock contents with "free".
*/
public void unlock() {
int old = cmpxchg(LOCK_FREE, [lock]);
//guard against recursive locks, i.e. the same lock
//being taken twice
assert(old == LOCK_TAKEN);
}
}
Due to the simplicity and low overhead of entering a spinlock, but because of the relatively high overhead maintaining it, spinlocks are only optimal if used in an implementation where locks are taken for very short periods of time. Spinlocks do not handle contention well. If the lock gets too contended, significant runtime will be wasted executing the loop that tries to acquire the lock. The cmpxchg itself is also dangerous when frequently executed, in that it may ruin caches and prevent any thread from running at maximum capacity.
Spinlocks are referred to as "thin" if they are simple to implement and take up few resources in a contention free environment. Less intrusive varieties can be implemented with slightly more complex logic (for example adding a yield or CPU pause to the spin loop), but the basic idea is the same.
As the implementation is nothing but a while loop with an atomic check, spinlocks cannot be used to support every aspect of Java synchronization. One example is the wait/notify mechanism that has to communicate with the thread system and the scheduler in order to put threads to sleep and wake them up when so required.
Fat locks are normally an order of magnitude slower than thin locks to release or acquire. They require a more complex representation than the thin lock and also have to provide better performance in a contended environment. Fat lock implementations may, for example, fall back to an OS level locking mechanism and thread controls.
Threads waiting for a fat lock are suspended. A lock queue for each fat lock is typically maintained, where the threads waiting for the lock are kept. The threads are usually woken up in FIFO order. The lock queue may be rearranged by the runtime as the scheduler sees fit or based on thread priorities. For objects used in wait / notify constructs, the JVM may also keep a wait queue for each monitor resource where the threads that are to be notified upon its release are queued.
In scheduling, the term fairness is often used to describe a scheduling policy where each thread gets an equally sized time quantum to execute. If a thread has used its quantum, another thread gets an opportunity to run.
If fairness is not an issue—such as when we don't need a certain level of even thread spread over CPUs and threads perform the same kind of work—it is, in general, faster to allow whatever thread that gets a chance to run to keep running. Simply put, if we are just concerned about maximizing Java execution cycles, it can be a good idea to let a thread that just released a lock reacquire it again. This avoids expensive context switching and doesn't ruin the caches. Surprisingly enough, unfair behavior like this from the scheduler can, in several cases, improve runtime performance.
When it comes to thin locks, there is actually no fairness involved by design. All locking threads race with each other when attempting to acquire a lock.
With fat locks, in principle, the same thing applies. The lock queue is ordered, but threads will still have to race for the lock if several threads at once are awoken from the queue.
Recollect the 2 x 32-bit word header of any object in JRockit. One word is the class block that contains a pointer to type information for the object. The other word is the lock and GC word. Of the 32 bits in the lock and GC word, JRockit uses 8 bits for GC information and 24 bits for lock information.
Note
The lock word and object header layout described in this section reflects the current state of the implementation in JRockit R28 and is subject to change without notice between releases. The bit-level details are only introduced to further help explaining lock states and their implementation.
In JRockit, every lock is assumed to be a thin lock when first taken. The lock bits of a thin locked object contain information about the thread that is holding the lock, along with various extra information bits used for optimization. For example for keeping track of the number of lock transfers between threads to determine if a lock is mostly thread local, and thus mostly unnecessary.
A fat lock requires a JVM internal monitor to be allocated for lock and semaphore queue management. Therefore, most of the space in the lock word for fat locks is taken up by an index (handle) to the monitor structure.
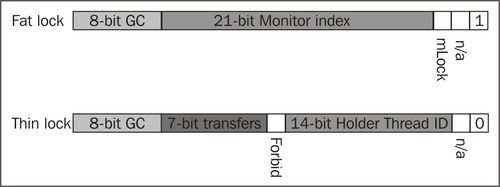
The JRockit lock bits are one example of an implementation of helper data structures for thin and fat locks, but of course both object header layout and contents vary between different vendors' JVM implementations. The various state diagrams that follow, go into some more detail on how thin locks and fat locks are converted to each other in JRockit and how lock words are affected by the state transitions.
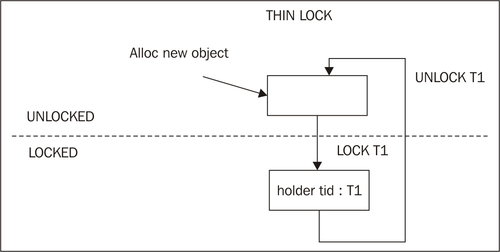
The previous figure shows the relatively simple transitions between a locked and unlocked state if only thin locks are involved. An unlocked object is locked when thread T1 executes a successful lock on the object. The lock word in the object header now contains the thread ID of the lock taker and the object is flagged as thin locked. As soon as T1 executes an unlock, the object reverts back to unlocked state and the lock holder bits are zeroed out in the object header.
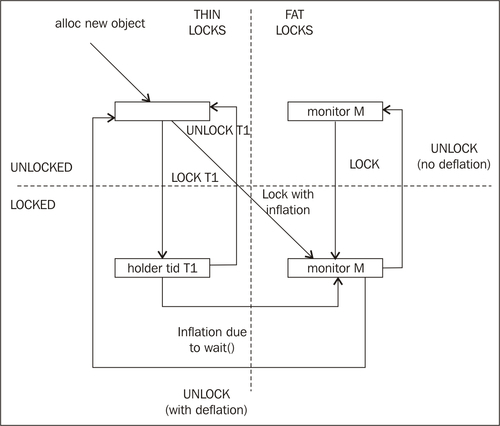
If we add fat locks to the picture, things get a little bit more complex. Recollect that a thin lock can be inflated into a fat lock if it is determined that it is too contended or if a call to wait is applied to it, such as a call to wait. The object can go directly to fat locked if thread T1 attempts to acquire it and it is known to be contended. There is also a path from the thin locked version of the lock to the fat locked version in the event of a wait call. As a fat lock keeps its allocated JVM internal monitor, along with the handle to it, in the lock word, unlocking a fat lock without finding the need to deflate it will retain the monitor ID in the lock word, reusing the monitor structure.
The section on Pitfalls and false optimizations later in this chapter will further discuss how the runtime adaptively turns thin locks and fat locks into one another using contention based heuristics.
Java bytecode defines two opcodes for controlling synchronization—monitorenter and monitorexit. They both pop a monitor object from the execution stack as their only operand. The opcodes monitorenter and monitorexit are generated by javac when there are synchronized regions with explicit monitor objects in the code. Consider the following short Java method that synchronizes on an implicit monitor object, in this case this, as it is an instance method:
public synchronized int multiply(int something) {
return something * this.somethingElse;
}
The bytecode consists of the seemingly simple sequence shown as follows:
public synchronized int multiply(int);
Code:
0: iload_1
1: aload_0
2: getfield #2; //Field somethingElse:I
5: imul
6: ireturn
Here, the runtime or JIT compiler has to check that the method is synchronized by examining an access flag set for this particular method in the .class file. Recollect that a synchronized method has no explicit monitor, but in instance methods this is used and in static methods a unique object representing the class of the object is used. So, the earlier source code is trivially equivalent to:
public int multiply(int something) {
synchronized(this) {
return something * this.somethingElse;
}
}
But, the previous code compiles to this rather more complex sequence:
public int multiply(int);
Code:
0: aload_0
1: dup
2: astore_2
3: monitorenter
4: iload_1
5: aload_0
6: getfield #2; //Field somethingElse:I
9: imul
10: aload_2
11: monitorexit
12: ireturn
13: astore_3
14: aload_2
15: monitorexit
16: aload_3
17: athrow
Exception table:
from to target type
4 12 13 any
13 16 13 any
What javac has done here, except for generating monitorenter and monitorexit instructions for this, is that it has added a generic catch-all try block for the entire code of the synchronized block, bytecode 4 to bytecode 9 in the previous example. Upon any unhandled exception, control will go to bytecode 13, the catch block, which will release the lock before re-throwing whatever exception was caught.
Compiler intervention in this fashion is the standard way of solving the issue of unlocking a locked object when an exception occurs. Also notice that if there are exceptions in the catch block from bytecode 13 to bytecode 16, it will use itself as the catch-all, creating a cyclic construct that isn't possible to express in Java source code. We explained the problems with this in Chapter 2.
Naturally, we could treat this as unstructured control flow, but as the recursive catch is a common pattern, and as we don't want it to complicate control flow analysis, it is treated specially by the JRockit compiler. Otherwise it would be considered obfuscated code, and a number of optimizations would be forbidden from being done.
JRockit internally translates all methods with an implicit monitor object into methods with an explicit one, similar to what is shown in the second part of example, in order to avoid the special case with the synchronized flag.
Other than the previous bytecode issue there is a more serious one—monitorenter and monitorexit are not paired. It is simple to generate weird bytecode where, for example, a monitorexit is executed on an unlocked object. This would lead to an IllegalMonitorStateException at runtime. However, bytecode where a lock is taken in one method and then released in another is also possible (and perfectly legal at runtime). The same applies to various many-to-many mappings of monitorenter and monitorexit for the same lock. Neither of these constructs have Java source code equivalents. The problem of the power of expression comes back to bite us.
For performance reasons, in a JIT compiler, it is very important to be able to identify the matching lock for a particular unlock operation. The type of the lock determines the unlock code that has to be executed. As we shall soon see, given even more kinds of locks than just thin and fat ones, this becomes increasingly important. Sadly, we cannot assume that locks are nicely paired, because of the non-symmetrical semantics of the bytecode. Unpaired locks don't occur in ordinary bytecode and in ordinary programs, but as it is possible, JRockit needs to be able to handle unpaired synchronization constructs as well.
The JRockit code generator does control flow analysis upon method generation and tries to match every monitorenter to its corresponding monitorexit instruction(s). For structured bytecode that was compiled from Java source, this is almost always possible (if we treat the anomalous catch produced by synchronized blocks as a special case). The match is done when turning the stack-based metaphor into a register-based one, piggybacking on the BC2HIR pass of the code generator, which, as explained in Chapter 2, has to do control flow analysis anyway.
JRockit uses a mechanism called lock tokens to determine which monitorenter and monitorexit instructions belong together. Each monitorenter is translated into an instruction with a lock token destination. Its matching monitorexit is translated into an instruction with that particular lock token as a source operand.
Following is a pseudocode example of the transformation of a Java synchronized region to JRockit matched (or paired) locks:
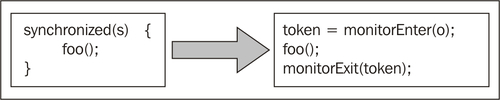
In the rare case that a monitorenter can't be mapped to a particular monitorexit, JRockit tags these instructions with a special "unmatched" flag. While, this is still supported by the runtime, and needs to be for full bytecode compliance, we shall soon see that handling unmatched locks is orders of magnitude more expensive than handling tokenized locks.
From a practical perspective, unmatched locks never occur in standard compiled bytecode, but may show up in obfuscated code or as the result of various bytecode profilers. Running JRockit with verbose code generator output (-Xverbose:codegen) will display information about unmatched locks if they are detected. In JRockit versions from R28, there is also special JRockit Flight Recorder event for unmatched locks that can be used for performance profiling. If unmatched locks show up in your Java program, all performance bets are off. You probably need to get rid of them.
A special case, where lock pairing can never be done is in native code. Calls from native code, accessed through JNI, to monitorenter and monitorexit equivalents will always be treated as unmatched locks, as once the program is executing native code, we have no control over the stack. However, JNI marshalling overhead, i.e. executing the stub code to get from Java code to native code, is orders of magnitude slower than taking locks anyway. So, the key to lock performance may lie elsewhere if we enter and exit native code frequently.
So what is a lock token? JRockit implements a lock token as a reference to a monitor object, the operand to monitorenter, with a couple of bits added at the end. As we have seen in Chapter 3, objects are typically aligned on even addresses, in practice on 8 byte boundaries (or more for compressed references with larger heaps). So, we always have the lowest bits of any object pointer available for storing arbitrary information. Whenever any of the three lowest bits in an object pointer are non-zero, JRockit takes this to mean that the object is used as a monitor, locked with a lock token. The seven different possible non-zero bit configurations can be used to communicate different information about the lock, for instance if it is thin, taken recursively by the same thread, fat, or unmatched. Lock tokens can only exist in local stack frames, never on the heap. Since JRockit doesn't use compressed references in local frames, we are guaranteed to be able to claim the alignment bits of any object for token information.
Recollect from the previous chapter that all live registers at any given time are explicitly determined by the compiler and stored as livemaps, metadata accessible to the code generator. The same thing applies to lock tokens.
Trivially, because of the implicit lock pairing in structured Java code, one lock cannot be released before another one, taken inside that lock. It is easy to look at an object in a livemap and determine whether it is a lock token or not, but in order to be able to unlock tokens in the correct order upon, for example, an exception being thrown, nesting information is required as well. If many locks are taken when an exception occurs, the runtime needs to know the order in which they were locked. Consequently, the livemap system also provides the nesting order of lock tokens.
For unmatched unlocks, an expensive stack walk is required in order to discover the matching lock operation and update the lock state in its lock token reference. The JVM needs to look for it on all previous frames on the stack. This requires stopping the world and is several orders of magnitude slower than with perfect lock pairing that can be immediately handled by modifying a lock token on the local stack frame. Luckily, unmatched locks are rare. No code that is compiled with javac is likely to contain unmatched locks.
This section briefly covers some different types of thread implementations. It is fairly brief, as unmodified OS threads are the preferred way of implementing threads in a JVM these days.
Green threads usually refers to implementing threads with some kind of multiplexing algorithm, using one OS thread to represent several or all Java threads in the JVM. This requires that the runtime handle the thread scheduling for the Java threads inside the OS thread. The advantages to using green threads is that the overhead is a lot smaller than for OS threads when it comes to things like context switches and starting a new thread. Many early JVMs tended to favor some kind of green thread approach.
However, aside from the added complexity of having to implement lifecycle and scheduling code for the green threads, there is also the intrinsic problem of Java native code. If a green thread goes into native code that then blocks on the OS level, the entire OS thread containing all the green threads will be suspended. This most likely causes a deadlock issue by preventing any other Java thread contained in the same OS thread from running. So, a mechanism for detecting this is needed. Early versions of JRockit used green threads and solved the OS-level suspension problem with a mechanism called renegade threads, basically branching off a native thread from the main OS thread whenever a native operation was to be performed. If this happened frequently, the green thread model incrementally turned into a model where Java threads were one-to-one mapped to OS threads.
A variety of the green thread approach is to use several OS threads that in turn represent several green threads—sort of a hybrid solution. This is referred to as an n x m thread model. This can somewhat alleviate the green thread problem of blocking in native code.
In the early days of server-side Java, certain kinds of applications lent themselves well to this model—applications where thread scalability and low thread start overhead was everything. Several of the first paying JRockit customers had setups with the need for a very large number of concurrent threads and for low thread creation overhead, the prime example being chat servers. JRockit 1.0 used the n x m model and was able to provide massive performance increases in these very specialized domains.
As time went by and Java applications grew more complex, the added complexity of multiplexing virtual threads on OS threads, the common reliance on native code, and the refinement of other techniques such as more efficient synchronization, made the n x m approach obsolete.
To our knowledge, no modern server-side JVM still uses a thread implementation based on green threads. Because of their intrinsic simplicity and the issues mentioned earlier, OS threads are the preferred way of representing Java threads.
Naturally, the most obvious implementation of a java.lang.Thread is to use an underlying operating system thread, for example a POSIX thread on *NIX, one-to-one-mapped against each java.lang.Thread object. This has the advantage that most of the semantics are similar and little extra work needs to be done. Thread scheduling can also be outsourced to the operating system.
This is the most common approach and as far as we know, it is used in all modern JVM implementations. Other approaches often aren't worth the complexity anymore, at least not for standard server-side applications. In, for example, embedded environments, it may still make sense to use other approaches, but then, on the other hand, implementation space is constrained.
If we can rely on threads being OS threads, optimization techniques with slightly bad reputations, such as thread pooling, also make a certain amount of sense. The creation and starting of OS threads introduces a significantly larger overhead than if the VM uses some kind of green thread model. Under special circumstances, in a java.lang.Thread implementation based on OS threads, it might make sense to reuse existing thread objects in a Java program, to try to reduce this overhead. This is typically done by keeping finished threads in a thread pool and reusing them for new tasks instead of allocating new threads. The authors of this book generally frown upon trying to outsmart the JVM, but this is a case where it might sometimes pay off. However, serious profiling should be done before trying thread pooling to determine if it is really necessary.
Also, if the underlying thread implementation is not using pure OS threads, thread pooling may be disruptive and counterproductive. In a green thread model, starting a thread is extremely cheap. While to our knowledge no other JVM thread implementation than OS threads exists today, Java is still supposed to be a platform-independent language. So, proceed with caution.