
This section discusses how threads and synchronization can be optimized in an adaptive runtime environment.
As was mentioned when the different types of locks were introduced, one of the most important optimizations in an adaptive runtime is the ability to convert thin locks to fat locks and vice versa, depending on load and contention. Both the code generator and the lock implementation will attempt to solve this problem as efficiently as possible.
In an adaptive environment, the runtime has the benefit of free lock profiling information (at least a small amount of free lock profiling information, as, we shall see, doing complete in-depth lock profiling incurs some runtime overhead). Whenever a lock is taken or released, information can be logged about who is trying to get the lock and how many times it has been contended. So, if a single thread has failed to acquire a thin lock in too many subsequent attempts, it makes good sense for the virtual machine to convert it to a fat lock. The fat lock is better suited for handling contention, in that waiting threads sleep instead of spin and therefore use less CPU cycles. We refer to the practice of converting a thin lock to a fat lock as lock inflation.
Note
JRockit, by default, also uses a small spinlock to implement a fat lock while it has been recently inflated and held only for a very short time. This might seem counterintuitive, but is generally beneficial. This behavior can be turned off from the command line (with the flag -XX:UseFatSpin=false), if deemed too slow for example, in an environment with highly contended locks with long waiting periods. The spinlock that is part of the fat lock can also be made adaptive and based on runtime feedback. This is turned off by default, but can be enabled with the command-line flag -XX:UseAdaptiveFatSpin=true.
In the same manner, when many subsequent unlocks of a fat lock have been done without any other thread being queued on its lock or wait queue, it makes sense to turn the fat lock into a thin lock again. We refer to this as lock deflation.
JRockit uses heuristics to perform both inflation and deflation, thus adapting to the changed behavior of a given program where, for example, locks that were contended in the beginning of program execution stop being contended. Then these locks are candidates for deflation.
The heuristics that trigger transitions between thin and fat locks can be overridden and modified from the command line if needed, but this is generally not recommended. The next chapter will briefly discuss how to do this.
It is permissible, though unnecessary, for the same thread to lock the same object several times, also known as recursive locking. Code that does so occurs, for example, where inlining has taken place or in a recursive synchronized method. Then the code generator may remove the inner locks completely, if no unsafe code exists within the critical section, (such as volatile accesses or escaping calls between the inner and outer locks).
This can be combined with optimizing for the recursive lock case. JRockit uses a special lock token bit configuration to identify recursive locks. As long as a lock has been taken at least twice by one thread without first being released, it is tagged as recursive. So, forced unlock operations upon exceptions can still be correctly implemented, resetting the recursion count to the correct state, with no extra synchronization overhead.
The JRockit optimizing JIT compiler also uses a code optimization called lock fusion (sometimes also referred to as lock coarsening in literature). When inlining plenty of code, especially synchronized methods, the observation can be made that frequent sequential locks and unlocks with the same monitor object are common.
Consider code that, after inlining, looks like:
synchronized(x) {
//Do something...
}
//Short snippet of code...
x = y;
synchronized(y) {
//Do something else...
}
Classic alias analysis by the compiler trivially gives us that x and y are the same object. If the short piece of code between the synchronized blocks carries little execution overhead, less than the overhead of releasing and reacquiring the lock, it is beneficial to let the code generator fuse the lock regions into one.
synchronized(x) {
//Do something...
//Short snippet of code...
x = y;
//Do something else...
}
Additional requirements are of course that there are no escaping or volatile operations in the code between the synchronized blocks, or the Java Memory Model semantics for equivalence would be violated. There are of course a few other code optimization issues that have to be handled that are beyond the scope of this chapter. An example would be that any exception handlers for the regions that are to be fused need to be compatible.
Naturally, it might not be beneficial just to fuse every block of code we see, but we can avoid some overhead if the blocks to fuse are picked cleverly. And if enough sampling information is available for the short snippet of code, we can make clever adaptive guesses to whether a lock fusion would be beneficial or not.
To summarize, this code optimization all boils down to not releasing a lock unnecessarily. The thread system itself can, by making its state machine a little bit more complicated, implement a similar optimization, independent of the code generator, known as lazy unlocking.
So what does the previous observation really mean, if it can be showed that there are many instances of thread local unlocks and re-locks that simply slow down execution? Perhaps this is the case almost all the time? Perhaps the runtime should start assuming that each individual unlock operation is actually not needed?
This gamble will succeed each time the lock is reacquired by the same thread, almost immediately after release. It will fail as soon as another thread tries to acquire the seemingly unlocked object, which semantics must allow it to do. Then the original thread will need to have the lock forcefully unlocked in order to make it seem as if "nothing has happened". We refer to this practice as lazy unlocking (also referred to as biased locking in some literature).
Even in the case that there is no contention on a lock, the actual process of acquiring and releasing the lock is expensive compared to doing nothing at all. Atomic instructions incur overhead to all Java execution in their vicinity.
In Java, sometimes it is reasonable to assume that most locks are thread local. Third-party code often uses synchronization unnecessarily for a local application, as the authors of third-party libraries cannot be sure if the code is to run in a parallel environment or not. They need to be safe unless it is explicitly specified that thread safety is not supported. There are plentiful examples of this in the JDK alone, for example the java.util.Vector class. If the programmer needs vector abstraction for a thread local application, he might pick java.util.Vector for convenience, not thinking about its inherent synchronization, when java.util.ArrayList virtually performs the same job but is unsynchronized.
It seems sensible that if we assume most locks are thread local and never shared, we would gain performance in such cases, taking a lazy unlocking approach. As always, we have a trade off—if another thread needs to acquire a lazy unlocked object, more overhead is introduced than in a non-lazy model, as the seemingly free object must be located and released.
It seems reasonable to assume that, as an overall approach, always gambling that an unlock won't be needed, isn't such a safe bet. We need to optimize for several different runtime behaviors.
The semantics of a lazy unlocking implementation are fairly simple.
For the lock operation, monitorenter:
- If the object is unlocked, the thread that locks the object will reserve the lock, tagging the object as lazily locked.
- If the object is already tagged as lazily locked:
- If the lock is wanted by the same thread, do nothing (in principle a recursive lock).
- If the lock is wanted by another thread, we need to stop the thread holding the lock, detect the "real" locking state of the object, i.e. is it locked or unlocked. This is done with an expensive stack walk. If the object is locked, it is converted to a thin lock, otherwise it is forcefully unlocked so that it can be acquired by the new thread.
For the unlock operation, monitorexit:
- Do nothing for a lazily locked object and leave the object in a locked state, that is, perform lazy unlocking.
In order to revoke a reservation for a thread that wants the lock, the thread that did the reservation needs to be stopped. This is extremely expensive. The actual state of the lock to be released is determined by inspecting the thread stack for lock tokens. This is similar to the approach of handling unmatched locks described earlier. Lazy unlocking uses a lock token of its own, whose bit configuration means "this object is lazily locked".
If we never had to revert a lazy locked object, that is if all our locks are in fact thread local, all would be well and we would see immense performance gains. In the real world, however, we cannot afford to take the very steep penalty of releasing lazy locked objects time and time again, if our guess proves to be wrong. So, we have to keep track of the number of times a lazy lock is transferred between threads—the number of penalties incurred. This information is stored in the lock word of the monitor object in the so called transfer bits.
If the number of transfers between threads is too large, a particular object or its entire type (class) and all its instances can be forbidden from further lazy locking and will just be locked and unlocked normally using standard thin and fat lock mechanisms.
When a transfer limit is hit, the forbid bit in a JRockit object lock word is set. This bit indicates that a specific object instance is unsuitable for lazy unlocking. If the forbid bit is set in an object header, this particular object cannot be used for lazy unlocking ever again.
Also, if a lock is contended, regardless of other settings, lazy unlocking is immediately banned for its monitor object.
Further locking on a banned object will behave as ordinary thin and fat locks.
Just banning certain instances from being used in lazy unlocking may not be enough. Several objects of the same type often use locks similarly. Thus an entire class can be tagged so that none of its instances can be subject to lazy unlocking. If too many instances of a class are banned or too many transfers take place for instances of a class, the entire class is banned.
A dynamic twist to class bans and object bans can be introduced by letting the bans "age"—the runtime system gets a new chance to retry lazy unlocking with a certain object if a significant amount of time has been spent since the last ban. If we end up with the same ban in effect again, the aging can be set to be restarted, but run more slowly, or the ban can be made permanent.
The following figure tries to better illustrate the complexities of states involved in lazy unlocking:
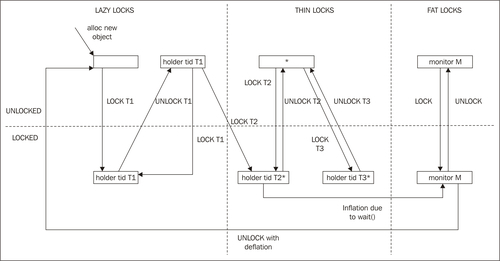
Now, we have three lock domains, as opposed to two (thin and fat) shown in the state graphs earlier in this chapter. The new domain "lazy" is added, which is where locking of hitherto unseen objects starts we hope our "gamble" that locks are mostly thread local pays off.
Just as before, starting at the unlocked, previously untouched object, a monitorenter by thread T1 will transition it to lazy locked state (just as with the thin locked state before). However, if T1 performs a monitorexit on the object, it will pretend to be unlocked, but really remain in a locked state, with the thread ID for T1 still flagging ownership in the lock bits. Subsequent locks by T1 will then be no-ops.
If another thread, T2 now tries to lock the object, we need to respect that, take the penalty for our erroneous guess that the lock was taken mostly by T1, flush out T1 from the thread ID bits and replace them with T2. If this happens often enough, the object may be subject to banning from lazy unlocking and then we must transfer the object to a normal thin locked state. Pretending that this was the case with the first monitorenter
T2 did on our object, this moves the state diagram to the familiar thin locked domain. Objects that are banned from lazy unlocking in the figure are denoted by (*). If thread T3 tries to lock a banned (but unlocked) object, we notice that we remain in the thin locked section of the picture. No lazy unlocking is allowed.
In similar fashion as before, thin locks are inflated to fat locks if they get contended or their objects are used with wait / notify, which requires wait queues. This is true for objects in the lazy domain as well.
Most commercial JVM implementations maintain some kind of mechanism for lazy unlocking. Somewhat cynically, this may have its origin in the popular SPECjbb2005 benchmark, which has many thread local locks and where small optimization efforts towards hanging on to locks result in huge performance gains.
Note
SPEC and the benchmark name SPECjbb2005 are trademarks of the Standard Performance Evaluation Corporation.
However, there are also several real-world applications, for example, application servers where it turns out that lazy unlocking can deliver performance. This is just because the sheer complexity and many abstraction layers has made it hard for developers to see if synchronization across threads needs be used at all.
Some versions of JRockit, such as the x86 implementation running JDK 1.6.0, come with lazy unlocking and banning heuristics enabled out of the box. This can be turned off from the command line if needed. To find out if a particular shipment of JRockit uses lazy unlocking as a default option, please consult the section on locks in the JRockit documentation.