
CHAPTER 4
HARDWARE ELEMENTS OF SECURITY
Sy Bosworth and Stephen Cobb
4.3.1 Vertical Redundancy Checks
4.3.2 Longitudinal Redundancy Checks
4.3.3 Cyclical Redundancy Checks
4.13 MICROCOMPUTER CONSIDERATIONS
4.13.5 Threats to Microcomputers
4.15 HARDWARE SECURITY CHECKLIST
4.1 INTRODUCTION.
Computer hardware has always played a major role in computer security. Over the years, that role has increased dramatically, due to both the increases in processing power, storage capacity, and communications capabilities as well as the decreases in cost and size of components. The ubiquity of cheap, powerful, highly connected computing devices poses significant challenges to computer security. At the same time, the challenges posed by large, centralized computing systems have not diminished. An understanding of the hardware elements of computing is thus essential to a well-rounded understanding of computer security.
Chapter 1 of this Handbook has additional history of the evolution of information technology.
4.2 BINARY DESIGN.
Although there are wide variations among computer architectures and hardware designs, all have at least one thing in common: They utilize a uniquely coded series of electrical impulses to represent any character within there range. Like the Morse code with its dots and dashes, computer pulse codes may be linked together to convey alphabetic or numeric information. Unlike the Morse code, however, computer pulse trains may also be combined in mathematical operations or data manipulation.
In 1946, Dr. John von Neumann, at the Institute for Advanced Study of Princeton University, first described in a formal report how the binary system of numbers could be used in computer implementations. The binary system requires combinations of only two numbers, 0 and 1, to represent any digit, letter, or symbol and, by extension, any group of digits, letters, or symbols. In contrast, the conventional decimal system requires combinations of 10 different numbers, from 0 to 9, letters from a to z, and a large number of symbols, to convey the same information. Von Neumann recognized that electrical and electronic elements could be considered as having only two states, on and off, and that these two states could be made to correspond to the 0 and 1 of the binary system. If the turning on and off of a computer element occurred at a rapid rate, the voltage or current outputs that resulted would best be described as pulses. Despite 60 years of intensive innovation in computer hardware, and the introduction of some optically based methods of data representation, the nature of these electrical pulses and the method of handling them remain the ultimate measure of a computer's accuracy and reliability.
4.2.1 Pulse Characteristics.
Ideally, the waveform of a single pulse should be straight-sided, flat-topped, and of an exactly specified duration, amplitude, and phase relationship to other pulses in a series. It is the special virtue of digital computers that they can be designed to function at their original accuracy despite appreciable degradation of the pulse characteristics. However, errors will occur when certain limits are exceeded, and thus data integrity will be compromised. Because these errors are difficult to detect, it is important that a schedule of preventive maintenance be established and rigidly adhered to. Only in this way can operators detect degraded performance before it is severe enough to affect reliability.
4.2.2 Circuitry.
To generate pulses of desirable characteristics, and to manipulate them correctly, requires components of uniform quality and dependability. To lower manufacturing costs, to make servicing and replacement easier, and generally to improve reliability, computer designers try to use as few different types of components as possible and to incorporate large numbers of each type into any one machine.
First-generation computers used as many as 30,000 vacuum tubes, mainly in a half-dozen types of logic elements. The basic circuits were flip-flops, or gates, that produced an output pulse whenever a given set of input pulses was present. However, vacuum tubes generated intense heat, even when in a standby condition. As a consequence, the useful operating time between failures was relatively short.
With the development of solid state diodes and transistors, computers became much smaller and very much cooler than their vacuum-tube predecessors. With advances in logic design, a single type of gate, such as the not-and (NAND) circuit, could replace all other logic elements. The resulting improvements in cost and reliability have been accelerated by the use of monolithic integrated circuits. Not least in importance is their vastly increased speed of operation. Since the mean time between failures of electronic computer circuitry is generally independent of the number of operations performed, it follows that throughput increases directly with speed; speed is defined as the rate at which a computer accesses, moves, and manipulates data. The ultimate limitation on computer speed is the time required for a signal to move from one physical element to another. At a velocity of 299, 792, 458 meters per second (186, 282 miles per second) in vacuum, an electrical signal travels 3.0 meters or 9.84 feet in 10 nanoseconds (0.000,000,01 seconds). If components were as large as they were originally, and consequently as far apart, today's nanosecond computer speeds would clearly be impossible, as would be the increased throughput and reliability now commonplace.
4.2.3 Coding.
In a typical application, data may be translated and retranslated automatically into a half-dozen different codes thousands of times each second. Many of these codes represent earlier technology retained for backward compatibility and economic reasons only. In any given code, each character appears as a specific group of pulses. Within each group, each pulse position is known as a bit, since it represents either of the two binary digits, 0 or 1. Exhibit 4.1 illustrates some of the translations that may be continuously performed as data move about within a single computer.
A byte is the name originally applied to the smallest group of bits that could be read and written (accessed or addressed) as a unit. Today a byte is always considered by convention to have 8 bits. In modern systems, a byte is viewed as the storage unit for a single American Standard Code for Information Interchange (ASCII) character, although newer systems such as Unicode, which handle international accented characters and many other symbols, use up to 4 bytes per character. By convention, most people use metric prefixes (kilo-, mega-, giga-, tera-) to indicate collections of bytes; thus KB refers to kilobytes and is usually defined as 1,024 bytes. Outside the data processing field, K would normally indicate the multiplier 1,000. Because of the ambiguity in definitions, the United States National Institute of Standards and Technology (NIST) proposed, and in 2000 the International Electrotechnical Commission established, a new set of units for information or computer storage. These units are established by a series of prefixes to indicate powers of 2; in this scheme, KB means kibibytes and refers exclusively to 1,024 (210 or ∼103) bytes. However, kibibytes, mebibytes (220 or ∼106), gibibytes (230 or ∼109), and tebibytes (240 or ∼1012) are terms that have not yet become widely used.
EXHIBIT 4.1 Common Codes for Numeral 5

Because translations between coding systems are accomplished at little apparent cost, any real incentive to unify the different systems is lacking. However, all data movements and translations increase the likelihood of internal error, and for this reason parity checks and validity tests have become indispensable.
4.3 PARITY.
Redundancy is central to error-free data processing. By including extra bits in predetermined locations, certain types of errors can be detected immediately by inspection of these metadata (data about the original data). In a typical application, data move back and forth many times, among primary memory, secondary storage, input and output devices, as well as through communications links. During these moves, the data may lose integrity by dropping 1 or more bits, by having extraneous bits introduced, and by random changes in specific bits. To detect some of these occurrences, parity bits are added before data are moved and are checked afterward.
4.3.1 Vertical Redundancy Checks.
In this relatively simple and inexpensive scheme, a determination is initially made as to whether there should be an odd or an even number of “1” bits in each character. For example, using the binary-coded decimal representation of the numerical “5,” we find that the 6-bit pulse group 000101 contains two 1s, an even number. Adding a seventh position to the code group, we may have either type of parity. If odd parity has been selected, a 1 would be added in the leftmost checkbit position:
Odd parity 1000101 three 1s
Even parity 0000101 two 1s
After any movement the number of 1 bits would be counted, and if not an odd number, an error would be assumed and processing halted. Of course, if 2 bits, or any even number, had been improperly transmitted, no error would be indicated since the number of “1” bits would still be odd.
To compound the problem of nonuniformity illustrated in Exhibit 4.1, each of the 4-, 5-, 6-, 7-, 8-, and 16-bit code groups may have an additional bit added for parity checking. Furthermore, there may be inconsistency of odd or even parity between manufacturers, or even between different equipment from a single supplier.
4.3.2 Longitudinal Redundancy Checks.
Errors may not be detected by a vertical redundancy check (VRC) alone, for reasons just discussed. An additional safeguard, of particular use in data transmission and media recording such as tapes and disks, is the longitudinal redundancy check (LRC). With this technique, an extra character is generated after some predetermined number of data characters. Each bit in the extra character provides parity for its corresponding row, just as the vertical parity bits do for their corresponding columns. Exhibit 4.2 represents both types as they would be recorded on 7-track magnetic tape. One bit has been circled to show that it is ambiguous. This bit appears at the intersection of the parity row and the parity column, and must be predetermined to be correct for one or the other, as it may not be correct for both. In the illustration, the ambiguous bit is correct for the odd parity requirement of the VRC character column; it is incorrect for the even parity of the LRC bit row.
EXHIBIT 4.2 Vertical and Longitudinal Parity, Seven-Track Magnetic Tape
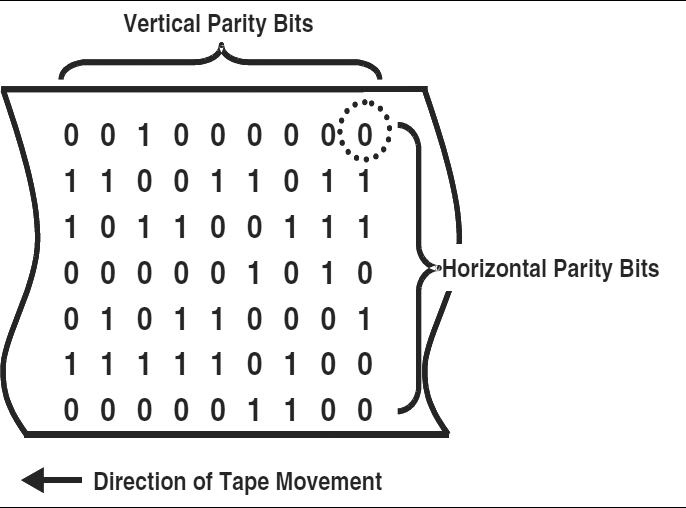
In actual practice, the vertical checkbits would be attached to each character column as shown, but the longitudinal bits would follow a block of data that might contain 80 to several hundred characters. Where it is possible to use both LRC and VRC, any single data error in a block will be located at the intersection of incorrect row and column parity bits. The indicated bit may then be corrected automatically. The limitations of this method are: (1) multiple errors cannot be corrected, (2) an error in the ambiguous position cannot be corrected, and (3) an error that does not produce both a VRC and LRC indication cannot be corrected.
4.3.3 Cyclical Redundancy Checks.
Where the cost of a data error could be high, the added expense of cyclical redundancy checks (CRCs) is warranted. In this technique, a relatively large number of redundant bits is used. For example, each 4-bit character requires 3 parity bits, while a 32-bit computer word needs 6 parity bits. Extra storage space is required in main and secondary memory, and transmissions take longer than without such checks. The advantage, however, is that any single error can be detected, whether in a data bit or a parity bit, and its location can be positively identified. By a simple electronic process of complementation, an incorrect 0 is converted to a 1, and vice versa.
4.3.4 Self-Checking Codes.
Several types of codes are in use that inherently contain a checking ability similar to that of the parity system. Typical of these is the 2-of-5 code, in which every decimal digit is represented by a bit configuration containing exactly two 1s and three 0s. Where a parity test would consist of counting 1s to see if their number was odd or even, a 2-of-5 test would indicate an error whenever the number of 1s was more or less than 2.
4.4 HARDWARE OPERATIONS.
Input, output, and processing are the three essential functions of any computer. To protect data integrity during these operations, several hardware features are available.
- Read-after-write. In disk and tape drives, it is common practice to read the data immediately after they are recorded and to compare them with the original values. Any disagreement signals an error that requires rewriting.
- Echo. Data transmitted to a peripheral device, to a remote terminal (see Section 4.9.1), or to another computer can be made to generate a return signal. This echo is compared with the original signal to verify correct reception. However, there is always the risk that an error will occur in the return signal and falsely indicate an error in the original transmission.
- Overflow. The maximum range of numerical values that any computer can accommodate is fixed by its design. If a program is improperly scaled, or if an impossible operation such as dividing by zero is called for, the result of an arithmetic operation may exceed the allowable range, producing an overflow error. Earlier computers required programmed instructions to detect overflows, but this function now generally is performed by hardware elements at the machine level. Overflows within application programs still must be dealt with in software. (Indeed, failure to do so can render software susceptible to abuse by malicious parties.)
- Validitation. In any one computer coding system, some bit patterns may be unassigned, and others may be illegal. In the IBM System/360 Extended Binary Coded Decimal Interchange Code (EBCDIC), for example, the number 9 is represented by 11111001, but 11111010 is unassigned. A parity check would not detect the second group as being in error, since both have the same number of 1 bits. A validity check, however, would reject the second bit configuration as invalid.
Similarly, certain bit patterns represent assigned instruction codes while others do not. In one computer, the instruction to convert packed-decimal numbers to zoned-decimal numbers is 11110011, or F3 in hexadecimal notation; 11110101, or F5, is unassigned, and a validity check would cause a processing halt whenever that instruction was tested.
- Replication. In highly sensitive applications, it is good practice to provide backup equipment on site, for immediate changeover in the event of failure of the primary computer. For this reason, it is sometimes prudent to retain two identical, smaller computers rather than to replace them with a single unit of equivalent or even greater power. Fault-tolerant, or fail-safe, computers use two or more processors that operate simultaneously, sharing the load and exchanging information about the current status of duplicate processes running in parallel. If one of the processors fails, another continues the processing without pause.
Many sensitive applications, such as airline reservation systems, have extensive data communications facilities. It is important that all of this equipment be duplicated as well as the computers themselves. (The failure of an airline reservation system, if permitted to extend beyond a relatively small number of hours, could lead to failure of the airline itself.)
Replacements should also be immediately available for peripheral devices. In some operating systems, it is necessary to inform the system that a device is down and to reassign its functions to another unit. In the more sophisticated systems, a malfunctioning device is automatically cut out and replaced. For example, the New York Stock Exchange operates and maintains two identical trading systems so that failure of the primary system should not result in any interruption to trading.
4.5 INTERRUPTS.
The sequence of operations performed by a computer system is determined by a group of instructions: a program. However, many events that occur during operations require deviations from the programmed sequence. Interrupts are signals generated by hardware elements that detect changed conditions and initiate appropriate action. The first step is immediately to store the status of various elements in preassigned memory locations. The particular stored bit patterns, commonly called program status words, contain the information necessary for the computer to identify the cause of the interrupt, to take action to process it, and then to return to the proper instruction in the program sequence after the interrupt is cleared.
4.5.1 Types of Interrupts.
Five types of interrupts are in general use. Each of them is of importance in establishing and maintaining data processing integrity.
4.5.1.1 Input/Output Interrupts.
Input/output (I/O) interrupts are generated whenever a device or channel that had been busy becomes available. This capability is necessary to achieve error-free use of the increased throughput provided by buffering, overlapped processing, and multiprogramming.
After each I/O interrupt, a check is made to determine whether the data have been read or written without error. If so, the next I/O operation can be started; if not, an error-recovery procedure is initiated. The number of times that errors occur should be recorded so that degraded performance can be detected and corrected.
4.5.1.2 Supervisor Calls.
The supervisor, or monitor, is a part of the operating system software that controls the interactions between all hardware and software elements.
Every request to read or write data is scheduled by the supervisor when called upon to do so. I/O interrupts also are handled by supervisor calls that coordinate them with read/write requests. Loading, executing, and terminating programs are other important functions initiated by supervisor calls.
4.5.1.3 Program Check Interrupts.
Improper use of instructions or data may cause an interrupt that terminates the program. For example, attempts to divide by zero and operations resulting in arithmetic overflow are voided. Unassigned instruction codes, attempts to access protected storage, and invalid data addresses are other types of exceptions that cause program check interrupts.
4.5.1.4 Machine Check Interrupts.
Among the exception conditions that will cause machine check interrupts are parity errors, bad disk sectors, disconnection of peripherals in use, and defective circuit modules. It is important that proper procedures be followed to clear machine checks without loss of data or processing error.
4.5.1.5 External Interrupts.
External interrupts are generated by timer action, by pressing an Interrupt key, or by signals from another computer. When two central processing units are interconnected, signals that pass between them initiate external interrupts. In this way, control and synchronization are continuously maintained while programs, data, and peripheral devices may be shared and coordinated.
In mainframes, an electronic clock generally is included in the central processor unit for time-of-day entries in job logs and for elapsed-time measurements. As an interval timer, the clock can be set to generate an interrupt after a given period. This feature should be used as a security measure, preventing sensitive jobs from remaining on the computer long enough to permit unauthorized manipulation of data or instructions.
4.5.2 Trapping.
Trapping is a type of hardware response to an interrupt. Upon detecting the exception, an unconditional branch is taken to some predetermined location. An instruction there transfers control to a supervisor routine that initiates appropriate action.
4.6 MEMORY AND DATA STORAGE.
Just as the human mind is subject to aberrations, so is computer memory. In the interests of data security and integrity, various therapeutic measures have been developed for the several types of storage.
4.6.1 Main Memory.
Random access memory (RAM), and its derivatives, such as dynamic RAM (DRAM), synchronous DRAM (SDRAM, introduced in 1996 and running at 133 megaHertz [MHz]), and DDR-3 (Double Data Rate 3 SDRAM, announced in 2005 and running at 800 MHz), share the necessary quality of being easily accessed for reading and writing of data. Unfortunately, this necessary characteristic is at the same time a potential source of difficulty in maintaining data integrity against unwanted read/write operations. The problems are greatly intensified in a multiprogramming environment, especially with dynamic memory allocation, where the possibility exists that one program will write improperly over another's data in memory. Protection against this type of error must be provided by the operating system. Chapter 24 in this Handbook discusses operating system security in more detail.
One form of protection requires that main memory be divided into blocks or pages; for example, 2,048 eight-bit bytes each. Pages can be designated as read-only when they contain constants, tables, or programs to be shared by several users. Additionally, pages that are to be inaccessible except to designated users may be assigned a lock by appropriate program instructions. If a matching key is not included in the user's program, access to that page will be denied. Protection may be afforded against writing only or against reading and writing.
4.6.2 Read-Only Memory.
One distinguishing feature of main memory is the extremely high speed at which data can be entered or read out. The set of sequential procedures that accomplishes this and other functions is the program, and the programmer has complete freedom to combine any valid instructions in a meaningful way. However, certain operations, such as system start-up, or booting, are frequently and routinely required, and they may be performed automatically by a preprogrammed group of memory elements. These elements should be protected from inadvertent or unauthorized changes.
For this purpose, a class of memory elements has been developed that, once programmed, cannot be changed at all, or require a relatively long time to do so. These elements are called read-only memory, or ROM; the process by which sequential instructions are set into these elements is known as microprogramming. The technique can be used to advantage where data integrity is safeguarded by eliminating the possibility of programmer error.
Variations of the principle include programmable read-only memories (PROM) and erasable, programmable read-only memory (EPROM), all of which combine microprogramming with a somewhat greater degree of flexibility than read-only memory itself. The data on these chips can be changed through a special operation often referred to as flashing (literally exposure to strong ultraviolet light; this is different from flash memory used today for storage of such data as digital music files and digital photographs—we will return to the subject of flash memory in the next section).
4.6.3 Secondary Storage.
The term “secondary storage” traditionally has been used to describe storage such as magnetic disks, diskettes, tapes, and tape cartridges. Although the 1.44 megabyte (MB) magnetic floppy disk is obsolete, the magnetic hard drive, with capacities up to terabytes, remains an essential element of virtually all computers, and terabyte-capacity external hard drives the size of a paperback book are now available off-the-shelf for a few hundred dollars.
A more recent development are optical drives such as the removable, compact-disk read-only memory (CD-ROM), originally made available in the early 1980s, which are useful for long-term archival storage of around 700 MB per disk. Hybrid forms of this type exist as well, such as CD-Rs, which can be written to once, and CD-RWs which accommodate multiple reads and writes. The Digital Video Disk (DVD), or as it has been renamed, the Digital Versatile Disk, was introduced in 1997 and provides capacities ranging from 4.7 gigabytes (GB) per disk up to 30 GB for data archiving. The higher-capacity optical disks use Blu-ray technology introduced in 2002 and can store 25 GB per side; they typically are used for distributing movies, but BD-R (single use) and BD-RE (rewritable) disks hold much potential for generalized data storage.
The newest addition to secondary storage is RAM that simulates hard disks, known as flash memory. Derived from electrical EPROMs (EEPROMs) and introduced by Toshiba in the 1980s, this kind of memory now exists in a huge variety of formats, including relatively inexpensive Universal Serial Bus (USB) tokens with storage capacities now in the gigabyte range. These devices appear as external disk drives when plugged into a plug-and-play personal computer. Another flash memory format is small cards, many the size of postage stamps, that can be inserted into mobile phones, cameras, printers, and other devices as well as computers.
Hardware safeguards described earlier, such as redundancy, validity, parity, and read-after-write, are of value in preserving the integrity of secondary storage. These safeguards are built into the equipment and are always operational unless disabled or malfunctioning. Other precautionary measures are optional, such as standard internal labeling procedures for drives, tapes, and disks. Standard internal labels can include identification numbers, record counts, and dates of creation and expiration. Although helpful, external plastic or paper labels on recordable media are not an adequate substitute for computer-generated labels, magnetically inscribed on the medium itself, and automatically checked by programmed instructions.
Another security measure sometimes subverted is write-protection on removable media. Hardware interlocks prevent writing to them. These locks should be activated immediately when the media are removed from the system. Failure to do so will cause the data to be destroyed if the same media are improperly used on another occasion.
Hard drives, optical discs, and flash memory cards are classified as direct access storage devices (DASDs). Unlike magnetic tapes with their exclusively sequential processing, DASDs may process data randomly as well as in sequence. This capability is essential to online operations, where it is not possible to sort transactions prior to processing. The disadvantage of direct access is that there may be less control over entries and more opportunity to degrade the system than exists with sequential batch processing.
One possible source of DASD errors arises from the high rotational velocity of the recording medium and, except on head-per-track devices, the movement of heads as well. To minimize this possibility, areas on the recording surface have their addresses magnetically inscribed. When the computer directs that data be read from or into a particular location, the address in main memory is compared with that read from the DASD. Only if there is agreement will the operation be performed.
Through proper programming, the integrity of data can be further assured. In addition to the address check, comparisons can be made on identification numbers or on key fields within each record. Although the additional processing time is generally negligible, there can be a substantial improvement in properly posting transactions.
Several other security measures often are incorporated into DASDs. One is similar to the protection feature in main memory and relies on determining “extents” for each data set. If these extents, which are simply the upper and lower limits of a data file's addresses, are exceeded, the job will terminate.
Another safety measure is necessitated by the fact that defective areas on a disk surface may cause errors undetectable in normal operations. To minimize this possibility, disks should be tested and certified prior to use and periodically thereafter. Further information is provided by operating systems that record the number of disk errors encountered. Reformatting or replacement must be ordered when errors exceed a predetermined level. Many personal computer hard drives now have some form of Self-Monitoring, Analysis, and Reporting Technology (SMART). Evolved from earlier technology such as IBM's Predictive Failure Analysis (PFA) and Intellisafe by computer manufacturer Compaq, and disk drive manufacturers Seagate, Quantum, and Conner, SMART can alert operators to potential drive problems. Unfortunately, the implementation of SMART is not standardized, and its potential for preventive maintenance and failure prediction is often overlooked.
Note that SMART is different from the range of technologies used to protect hard drives from head crashes. A head crash occurs when the component that reads data from the disk actually touches the surface of the disk, potentially damaging it and the data stored on it. Many hard drives have systems in place to withdraw heads from the disk before such contact occurs. These protective measures have reached the point where an active hard drive can be carried around in relative safety as part of a music and video player (e.g., Apple iPod or Microsoft Zune).
4.7 TIME.
Within the computer room and in many offices, a wall clock is usually a dominant feature. There is no doubt that this real-time indicator is of importance in scheduling and regulating the functions of people and machines, but the computer's internal timings are more important for security.
4.7.1 Synchronous.
Many computer operations are independent of the time of day but must maintain accurate relationships with some common time and with each other. Examples of this synchronism include the operation of gates, flip-flops, and registers, and the transmission of data at high speeds. Synchronism is obtained in various ways. For gates and other circuit elements, electronic clocks provide accurately spaced pulses at a high-frequency rate, while disk and tape drives are maintained at rated speed by servomotor controls based on power-line frequency.
Of all computer errors, the ones most difficult to detect and correct are probably those caused by timing inconsistencies. Internal clocks may produce 1 billion pulses per second (known as 1 gigahertz [GHz]), or more, when the computer is turned on. The loss of even a single pulse, or its random deformation or delay, can cause undetected errors. More troublesome is the fact that even if errors are detected, their cause may not be identified unless the random timing faults become frequent or consistent.
An example of the insidious nature of timing faults is the consequence of electrical power fluctuations when voltage drops below standard. During these power transients, disk drives may slow down; if sectors are being recorded, their physical size will be correspondingly smaller. Then, when the proper voltage returns, the incorrect sector sizes can cause data errors or loss.
4.7.2 Asynchronous.
Some operations do not occur at fixed time intervals and therefore are termed “asynchronous.” In this mode, signals generated by the end of one action initiate the following one. As an example, low-speed data transmissions such as those using ordinary modems are usually asynchronous. Coded signals produced by the random depression of keyboard keys are independent of any clock pulses.
4.8 NATURAL DANGERS.
To preserve the accuracy and timeliness of computer output, computers must be protected against environmental dangers. Chapters 22 and 23 of this Handbook discuss such threats in extensive detail.
4.8.1 Power Failure.
Probably the most frequent cause of computer downtime is power failure. Brownouts and blackouts are visible signs of trouble; undetected voltage spikes are far more common, although hardly less damaging.
Lightning can produce voltage spikes on communications and power lines of sufficient amplitude to destroy equipment or, at the very least, to alter data randomly. Sudden storms and intense heat or cold place excessive loads on generators. The drop in line voltage that results can cause computer or peripheral malfunction. Even if it does not, harmful voltage spikes may be created whenever additional generators are switched in to carry higher loads.
Where warranted, a recording indicator may be used to detect power-line fluctuations. Such monitoring often is recommended when computer systems show unexplained, erratic errors. At any time that out-of-tolerance conditions are signaled, the computer output should be checked carefully to ensure that data integrity has not been compromised. If such occurrences are frequent, or if the application is a sensitive one, auxiliary power management equipment should be considered. These range from simple voltage regulators and line conditioners to uninterruptible power supplies (UPSs).
4.8.2 Heat.
Sustained high temperatures can cause electronic components to malfunction or to fail completely. Air conditioning (AC) is therefore essential, and all units must be adequate, reliable, and properly installed. If backup electrical power is provided for the computer, it must also be available for the air conditioners. For example, after the San Francisco earthquake of 1989, the desktop computers and network servers in at least one corporate headquarters were damaged by a lack of synchronization between air conditioning and power supply. The AC was knocked out by the quake, and the building was evacuated, but the computers were left on. Many of them failed at the chip and motherboard level over the next few days because the temperature in the uncooled offices got too high. A frequently unrecognized cause of overheating is obstruction of ventilating grilles. Printouts, tapes, books, and other objects must not be placed on cabinets where they can prevent free air circulation. A digital thermometer is a good investment for any room in which computers are used. Today, many electronic devices include thermostats that cut off the power if internal temperatures exceed a danger limit.
4.8.3 Humidity.
Either extreme of humidity can be damaging. Low humidity,—below about 20 percent,—permits buildup of static electricity charges that may affect data pulses. Because this phenomenon is intensified by carpeting, computer room floors should either be free of carpeting or covered with antistatic carpet.
High humidity,—above about 80 percent,—may lead to condensation that causes shorts in electrical circuits or corrodes metal contacts. To ensure operation within acceptable limits, humidity controls should be installed and a continuous record kept of measured values.
4.8.4 Water.
Water introduced by rain, floods, bursting pipes, and overhead sprinklers probably has been responsible for more actual computer damage than fire or any other single factor. Care taken in locating computer facilities, in routing water pipes, and in the selection of fire-extinguishing agents will minimize this significant danger.
The unavailability of water—following a main break, for example,—will cause almost immediate shut down of water-cooled mainframes. Mission-critical data centers should be prepared for this contingency. As an example, when the Des Moines River flooded in 1993, it caused the skyscraper housing the headquarters of the Principal Financial Group to be evacuated, but not because of water in the building. The building stayed high and dry, but the flood forced the city water plant to shut down, depriving the building of the water necessary for cooling. After the flood, the company installed a 40,000-gallon water tank in the basement, to prevent any recurrence of this problem.
4.8.5 Dirt and Dust.
Particles of foreign matter can interfere with proper operation of magnetic tape and disk drives, printers, and other electromechanical devices. All air intakes must be filtered, and all filters must be kept clean. Cups of coffee seem to become especially unstable in a computer environment; together with any other food or drink, they should be banned entirely. Throughout all areas where computer equipment is in use, good housekeeping principles should be rigorously enforced.
4.8.6 Radiation.
Much has been written about the destructive effect of magnetic fields on tape or disk files. However, because magnetic field strength diminishes rapidly with distance, it is unlikely that damage actually could be caused except by large magnets held very close to the recorded surfaces. For example, storing a CD or DVD by attaching it to a filing cabinet with a magnet is not a good idea, but simply walking past a refrigerator decorated with magnets while holding a CD or DVD is unlikely to do any damage.
The proliferation of wireless signals can expose data to erroneous pulses. Offices should be alert for possible interference from and between cordless phones, mobile phones, wireless Internet access points and peripherals, and microwave ovens.
Radioactivity is a great threat to personnel but not to the computer or its recording media.
4.8.7 Downtime.
It is essential to the proper functioning of a data center that preventive maintenance be performed regularly and that accurate records be kept of the time and the reason that any element of the computer is inoperative. The more often the computer is down, the more rushed operators will be to catch up on their scheduled workloads. Under such conditions, controls are bypassed, shortcuts are taken, and human errors multiply.
Downtime records should be studied to detect unfavorable trends and to pinpoint equipment that must be overhauled or replaced before outages become excessive. If unscheduled downtime increases, preventive maintenance should be expanded or improved until the trend is reversed.
4.9 DATA COMMUNICATIONS.
One of the most dynamic factors in current computer usage is the proliferation of devices and systems for data transmission. These range from telephone modems to wired networks, from Internet-enabled cell phones to 802.11 wireless Ethernet, and include Bluetooth, infrared, personal digital assistants (PDAs), music players, and new technologies that appear almost monthly. Computers that do not function at least part time in a connected mode may well be rarities. For fundamentals of data communications, see Chapter 5 of this Handbook.
The necessity for speeding information over great distances increases in proportion to the size and geographic dispersion of economic entities; the necessity for maintaining data integrity and security, and the difficulty of doing so, increases even more rapidly. Major threats to be guarded against include human and machine errors, unauthorized accession, alteration, and sabotage. The term “accession” refers to an ability to read data stored or transmitted within a computer system; it may be accidental or purposeful. “Alteration” is the willful entering of unauthorized or incorrect data. “Sabotage” is the intentional act of destroying or damaging the system or the data within it. For each of these threats, the exposure and the countermeasures will depend on the equipment and the facilities involved.
4.9.1 Terminals.
In these discussions, a terminal is any input/output device that includes facilities for receiving, displaying, composing, and sending data. Examples include personal computers and specialized devices such as credit card validation units.
Data communications are carried on between computers, between terminals, or between computers and terminals. The terminals themselves may be classified as dumb or intelligent. Dumb terminals have little or no processing or storage capability and are largely dependent on a host computer for those functions. Intelligent terminals generally include disk storage and capabilities roughly equivalent to those of a personal computer. In addition to vastly improved communications capabilities, they are capable of stand-alone operation.
In the simplest of terminals, the only protection against transmission errors lies in the inability to recognize characters not included in the valid set and to display a question mark or other symbol when one occurs. Almost any terminal can be equipped to detect a vertical parity error. More sophisticated terminals are capable of detecting additional errors through longitudinal and cyclical redundancy characters, as well as by vertical parity and validity checks. Of course, error detection is only the first step in maintaining data integrity. Error correction is by far the more important part, and retransmission is the most widely used correction technique.
Intelligent terminals and personal computers are capable of high-speed transmission and reception. They can perform complicated tests on data before requesting retransmission, or they may even be programmed to correct errors internally. The techniques for self-correction require forward-acting codes, such as the Hamming cyclical code. These are similar to the error-detecting cyclic redundancy codes, except that they require even more redundant bits. Although error correction is more expensive and usually slower than detection with retransmission, it is useful under certain circumstances. Examples include simplex circuits where no return signal is possible, and half-duplex circuits where the time to turn the line around from transmission to reception is too long. Forward correction is also necessary where errors are so numerous that retransmissions would clog the circuits, with little or no useful information throughput.
A more effective use of intelligent terminals and personal computers is to preserve data integrity by encryption, as described in this chapter and in Chapter 7. Also, they may be used for compression or compaction. Reducing the number of characters in a message reduces the probability of an error as well as the time required for transmission. One technique replaces long strings of spaces or zeroes with a special character and a numerical count; the procedure is reversed when receiving data.
Finally, the intelligent terminal or microprocessor may be used to encode or decipher data when the level of security warrants cryptography.
All terminals, of every type, including desktop and notebook personal computers (PCs), have at least one thing in common: the need to be protected against sabotage or unauthorized use. Although the principles for determining proper physical location and the procedures for restricting access are essentially the same as those that apply to a central computer facility, the actual problems of remote terminals are even more difficult. Isolated locations, inadequate supervision, and easier access by more people all increase the likelihood of compromised security.
4.9.2 Wired Facilities.
Four types of wired facilities are in widespread use: dial-up access, leased lines, digital subscriber lines (DSL), and cable carriers. Both common carriers and independent systems may employ various media for data transmission. The increasing need for higher speed and better quality in data transmission has prompted utilization of coaxial and fiber optic cables, while microwave stations and communication satellites often are found as wireless links within wired systems.
Generally, decisions as to the choice of service are based on the volume of data to be handled and on the associated costs, but security considerations may be even more important.
4.9.2.1 Dial-up Lines.
Still widely used for credit and debit card terminals, dial-up lines have been replaced for many other applications by leased lines, DSL lines, and cables carrying Internet traffic (using the TCP/IP protocol discussed in Chapter 5 of this Handbook). Dial-up connections are established between modems operating over regular voice lines sometimes referred to as plain old telephone service (POTS).
Where dial-up access to hardware still exists, for example, for maintenance of certain equipment, proper controls are essential to protect both the equipment and the integrity of other systems to which it might be connected. Dial-up ports may be reached by anyone with a phone, anywhere on the planet, and the practice of war-dialing to detect modems is still used by those seeking unauthorized access to an organization's network. (War dialing involves dialing blocks of numbers to find which ones respond as modems or fax machines. These numbers are recorded and may be dialed later in an attempt to gain unauthorized access to systems or services). It is advisable to:
- Compile a log of unauthorized attempts at entry, and use it to discourage further efforts.
- Compile a log of all accesses to sensitive data, and verify their appropriateness.
- Equip all terminals with internal identification generators or answer-back units, so that even a proper password would be rejected if sent from an unauthorized terminal. This technique may require the availability of an authorized backup terminal in the event of malfunction of the primary unit.
- Provide users with personal identification in addition to a password if the level of security requires it. The additional safeguard could be a magnetically striped or computerized plastic card to be inserted into a special reader. The value of such cards is limited since they can be used by anyone, whether authorized or not. For high-security requirements, other hardware-dependent biometric identifiers, such as handprints and voiceprints, should be considered.
- Where appropriate, utilize call-back equipment that prevents a remote station from entering a computer directly. Instead, the device dials the caller from an internal list of approved phone numbers to make the actual connection.
With proper password discipline, problems of accession, alteration, and data sabotage can be minimized. However, the quality of transmissions is highly variable. Built into the public telephone system is an automatic route-finding mechanism that directs signals through uncontrollable paths. The distance and the number of switching points traversed, and the chance presence of cross-talk, transients, and other noise products will have unpredictable effects on the incidence of errors. Parity systems, described earlier, are an effective means of reducing such errors.
4.9.2.2 Leased Lines.
Lines leased from a common carrier for the exclusive use of one subscriber are known as dedicated lines. Because they are directly connected between predetermined points, normally they cannot be reached through the dial-up network. Traditionally, leased lines were copper, but point-to-point fiber optic and coaxial cable lines can also be leased.
Wiretapping is a technically feasible method of accessing leased lines, but it is more costly, more difficult, and less convenient than dialing through the switched network. Leased lines are generally more secure than those that can be readily war-dialed.
To this increased level of security for leased lines is added the assurance of higher-quality reception. The problems of uncertain transmission paths and switching transients are eliminated, although other error sources are not. In consequence, parity checking remains a minimum requirement.
4.9.2.3 Digital Subscriber Lines.
Falling somewhere in between a leased line and plain old telephone service, (POTS), a digital subscriber line offers digital transmission locally over ordinary phone lines that can be used simultaneously for voice transmission. This is possible because ordinary copper phone lines can carry, at least for short distances, signals that are in a much higher frequency range than the human voice. A DSL modem is used by a computer to reach the nearest telephone company switch, at which point the data transmission enters the Internet backbone. Computers connected to the Internet over DSL communicate using TCP/IP and are said to be hosts rather than terminals. They are prone to compromise through a wide range of exploits. However, few if any of these threats are enabled by the DSL itself. As with leased lines, wiretapping is possible, but other attacks, such as exploiting weaknesses in TCP/IP implementations on host machines, are easier.
4.9.2.4 Cable Carriers.
Wherever cable television (TV) is available, the same optical fiber or coaxial cables that carry the TV signal also can be used to provide high-speed data communications. The advantages of this technology include download speeds that can, in the case of coaxial cables, exceed 50 megabits per second, or in the case of fiber optic cable, exceed 100 gigabits per second.
The disadvantages arise from the fact that connections to the carrier may be shared by other subscribers in the same locality. Unless the service provider limits access, perhaps in accordance with a quality-of-service agreement, multiple subscribers can be online simultaneously and thus slow down transmission speeds. Even more serious is the possibility of security breaches, since multiple computers within a neighborhood may be sharing part of a virtual local area network, and thus each is potentially accessible to every other node on that network. For this reason alone, cable connections should be firewalled. For details of firewalls and their uses, see Chapter 26 in this Handbook. Another reason for using firewalls is that cable connections are always on, providing maximal opportunity for hackers to access an unattended computer.
4.9.3 Wireless Communicationa.
Data transfers among multinational corporations have been growing very rapidly, and transoceanic radio and telephone lines have proved too costly, too slow, too crowded, and too error-prone to provide adequate service. An important alternative is the communications satellite. Orbiting above Earth, the satellite reflects ultra-high-frequency radio signals that can convey a television program or computer data with equal speed and facility.
For communications over shorter distances, the cost of common-carrier wired services has been so high as to encourage competitive technologies. One of these, the microwave radio link, is used in many networks. One characteristic of such transmissions is that they can be received only on a direct line-of-sight path from the transmitting or retransmitting antenna. With such point-to-point ground stations, it is sometimes difficult to position the radio beams where they cannot be intercepted; with satellite and wireless broadcast communications, it is impossible. This is a significant issue with wireless local area network technology based on the IEEE 802.11 standards and commonly known as WiFi (a brand name owned by the Wi-Fi Alliance; the term is short for wireless fidelity). The need for security is consequently greater, and scramblers or cryptographic encoders are essential for sensitive data transfers.
Because of the wide bandwidths at microwave frequencies, extremely fast rates of data transfer are possible. With vertical, longitudinal, and cyclical redundancy check characters, almost all errors can be detected, yet throughput remains high.
4.10 CRYPTOGRAPHY.
Competitive pressures in business, politics, and international affairs continually create situations where morality, privacy, and the laws all appear to give way before a compelling desire for gain. Information, for its own sake or for the price it brings, is an eagerly sought after commodity. We are accustomed to the sight of armored cars and armed guards transporting currency, yet often invaluable data are moved with few precautions. When the number of computers and competent technicians was small, the risk in careless handling of data resources was perhaps not great. Now, however, a very large population of knowledgeable computer people exists, and within it are individuals willing and able to use their knowledge for illegal ends. Others find stimulation and satisfaction in meeting the intellectual challenge that they perceive in defeating computer security measures.
Acquiring information in an unauthorized manner is relatively easy when data are communicated between locations. One method of discouraging this practice, or rendering it too expensive to be worth the effort, is cryptographic encoding of data prior to transmission. This technique is also useful in preserving the security of files within data storage devices. If all important files were stored on magnetic or optical media in cryptographic cipher only, the incidence of theft and resale would unquestionably be less.
Many types of ciphers might be used, depending on their cost and the degree of security required. Theoretically, any code can be broken, given enough time and equipment. In practice, if a cipher cannot be broken fairly quickly, the encoded data are likely to become valueless. However, since the key itself can be used to decipher later messages, it is necessary that codes or keys be changed frequently.
For further information on cryptography, refer to Chapter 7 in this Handbook.
4.11 BACKUP.
As with most problems, the principal focus in computer security ought to be on prevention rather than on cure. No matter how great the effort, however, complete success can never be guaranteed. There are four reasons for this being so:
- Not every problem can be anticipated.
- Where the cost of averting a particular loss exceeds that of recovery, preventive measures may not be justified.
- Precautionary measures, carried to extremes, can place impossible constraints on the efficiency and productivity of an operation. It may be necessary, therefore, to avoid such measures aimed at events whose statistical probability of occurrence is small.
- Even under optimum conditions, carefully laid plans may go astray. In the real world of uncertainty and human fallibility, where there is active or inadvertent interference, it is almost a certainty that at one time or another, the best of precautionary measures will prove to be ineffective.
Recognizing the impossibility of preventing all undesired actions and events, it becomes necessary to plan appropriate means of recovering from them. Such plans must include backup for personnel, hardware, power, physical facilities, data, and software. Data backups are discussed more fully in Chapter 57 of this Handbook.
Responding to emergencies is described in Chapters 56 of this Handbook and business continuity planning and disaster recovery are discussed in Chapter 58 and 59.
Backup plans should be evaluated with respect to:
- The priorities established for each application, to ensure that they are properly assigned and actually observed.
- The time required to restore high-priority applications to full functioning status.
- The degree of assurance that plans actually can be carried out when required. For important applications, alternative plans should be available in the event that the primary plan cannot be implemented.
- The degree of security and data integrity that will exist if backup plans actually are put into effect.
- The extent to which changing internal or external conditions are noted, and the speed with which plans are modified to reflect such changes.
The assignment of priorities in advance of an actual emergency is an essential and critically important process. In most organizations, new applications proliferate, while old ones are rarely discarded. If backup plans attempt to encompass all jobs, they are likely to accomplish none. Proper utilization of priorities will permit realistic scheduling, with important jobs done on time and at acceptable costs.
4.11.1 Personnel.
The problems of everyday computer operation require contingency plans for personnel on whose performance hardware functioning depends. Illnesses, vacations, dismissals, promotions, resignations, overtime, and extra shifts are some of the reasons why prudent managers are continuously concerned with the problem of personnel backup. The same practices that work for everyday problems can provide guidelines for emergency backup plans. This subject is covered more fully in Chapter 45 of this Handbook.
4.11.2 Hardware.
Hardware backup for data centers can take several forms:
- Multiple processors at the same site to protect against loss of service due to breakdown of one unit
- Duplicate installations at nearby facilities of the same company
- Maintaining programs at a compatible service bureau, on a test or standby basis
- A contract for backup at a facility dedicated to disaster recovery
- A reciprocal agreement with a similar installation at another company
The probability of two on-site processors both being down at the same time due to internal faults is extremely small. Consequently, most multiple installations rarely fall behind on mission-critical applications. However, this type of backup offers no protection against power failure, fire, vandalism, or any disaster that could strike two or more processors at once. The disasters of September 11, 2001, proved that even a highly unlikely event actually could occur. With duplicate processors at different but commonly owned sites, there is little chance of both being affected by the same forces. Although the safety factor increases with the distance separating them, the difficulty of transporting people and data becomes greater. An alternate site must represent a compromise between these conflicting objectives. Furthermore, complete compatibility of hardware and software will have to be preserved, even though doing so places an undue operational burden on one of the installations. Shortly after September 11, a number of financial firms were back in operation with their alternative computer sites across the Hudson River.
The backup provided by service bureaus can be extremely effective, particularly if the choice of facility is carefully made. Although progressive service bureaus frequently improve both hardware and software, they almost never do so in a way that would cause compatibility problems for their existing customers. Once programs have been tested, they can be stored off-line on tape or disk at little cost. Updated masters can be rotated in the service bureau library, providing off-site data backup as well as the ability to become fully operational at once.
Effective hardware backup is also available at independent facilities created expressly for that purpose. In one type of facility, there are adequate space, power, air conditioning, and communication lines to accommodate a very large system. Most manufacturers are able to provide almost any configuration on short notice when disaster strikes a valued customer. The costs for this type of base standby facility are shared by a number of users so that expenses are minimal until an actual need arises. However, if two or more sharers are geographically close, their facilities may be rendered inoperative by the same fire, flood, or power failure. Before contracting for such a facility, it is necessary to analyze this potential problem; the alternative is likely to be a totally false sense of security. Several firms whose facilities were damaged or destroyed on September 11 were provided with complete replacement equipment by their vendors within a short time.
Another type of backup facility is already equipped with computers, disk and tape drives, printers, terminals, and communications lines so that it can substitute instantly for an inoperative system. The standby costs for this service are appreciably more than for a base facility, but the assurance of recovery in the shortest possible time is far greater. Here, too, it would be prudent to study the likelihood of more than one customer requiring the facility at the same time and to demand assurance that one's own needs will be met without fail. Several companies successfully availed themselves of this type of backup and disaster recovery after September 11.
Backup by reciprocal agreement was for many years an accepted practice, although not often put to the test. Unfortunately, many managers still rely on this outmoded safeguard. One has only to survive a single major change of operating system software to realize that when it occurs, neither the time nor the inclination is available to modify and test another company's programs. Even the minor changes in hardware and software that continuously take place in most installations could render them incompatible. At the same time, in accordance with Parkinson's Law, workloads always expand to fill the available time and facilities. In consequence, many who believe that they have adequate backup will get little more than an unpleasant surprise, should they try to avail themselves of the privilege.
4.11.3 Power.
The one truly indispensable element of any data processing installation is electric power. Backing up power to PCs and small servers by uninterruptible power supplies is reasonable in cost and quite effective. For mainframes and large servers, several types of power backup are available. The principal determinant in selection should be the total cost of anticipated downtime and reruns versus the cost of backup to eliminate them. Downtime and rerun time may be extrapolated from records of past experience.
Problems due to electrical power may be classified by type and by the length of time that they persist. Power problems as they affect computers consist of variations in amplitude, frequency, and waveform, with durations ranging from fractions of a millisecond to minutes or hours. Long-duration outages usually are due to high winds, ice, lightning, vehicles that damage power lines, or equipment malfunctions that render an entire substation inoperative. For mainframes in data centers, it is usually possible, although costly, to contract for power to be delivered from two different substations, with one acting as backup.
Another type of protection is afforded by gasoline or diesel motor generators. Controls are provided that sense a power failure and automatically start the motor. Full speed is attained in less than a minute, and the generator's output can power a computer for days if necessary.
The few seconds' delay in switching power sources is enough to abort programs running on the computer and to destroy data files. To avoid this, the “uninterruptible” power supply was designed. In one version, the AC power line feeds a rectifier that furnishes direct current to an inverter. The inverter in turn drives a synchronous motor coupled to an alternator whose AC output powers the computer. While the rectifier is providing DC to the inverter, it also charges a large bank of heavy-duty batteries. As soon as a fault is detected on the main power line, the batteries are instantaneously and automatically switched over to drive the synchronous motor. Because the huge drain on the batteries may deplete them in a few minutes, a diesel generator must also be provided. The advantages of this design are:
- Variations in line frequency, amplitude, and waveform do not get through to the computer.
- Switchover from power line to batteries is undetectable by the computer. Programs keep running, and no data are lost.
- Millisecond spikes and other transients that may be responsible for equipment damage, and undetected data loss are completely suppressed.
A fuller treatment of physical threats is presented in Chapters 22 and 23 of this Handbook.
4.11.4 Testing.
The most important aspect of any backup plan is its effectiveness. Will it work? It would be a mistake to wait for an emergency to find out. The only sensible alternative is systematic testing.
One form of test is similar to a dress rehearsal, with the actual emergency closely simulated. In this way the equipment, the people, and the procedures can all be exercised, until practice assures proficiency. Periodically thereafter the tests should be repeated, so that changes in hardware, software, and personnel will not weaken the backup capability.
4.12 RECOVERY PROCEDURES.
The procedures required to recover from any system problem will depend on the nature of the problem and on the backup measures that were in place. Hardware recovery ranges from instantaneous and fully automatic, through manual repair or replacement of components, to construction, equipping, and staffing of an entirely new data center. Chapters 58 and 59 of this Handbook provide extensive information about these issues.
Almost every data center is a collection of equipment, with options, modifications, additions, and special features. Should it become necessary to replace the equipment, a current configuration list must be on hand and the procedures for reordering established in advance. An even better practice would be to keep a current list of desired equipment that could be used as the basis for replacement. Presumably, the replacements would be faster and more powerful, but additional time should be scheduled for training and conversion.
4.13 MICROCOMPUTER CONSIDERATIONS.
Four factors operate to intensify the problems of hardware security as they relate to small computers:
- Accessibility
- Knowledge
- Motivation
- Opportunity
4.13.1 Accessibility.
Accessibility is a consequence of operating small computers in a wide-open office environment rather than in a controlled data center. No security guards, special badges, man-traps, cameras, tape librarians, or shift supervisors limit access to equipment or data media in the office, as they do in a typical data center.
4.13.2 Knowledge.
Knowledge, and its lack, is equally dangerous. On one hand, as personal computers pervade the office environment, technical knowledge becomes widely disseminated. Where once this knowledge was limited to relatively few computer experts who could be controlled rather easily, its growing universality now makes control extremely difficult, if not impossible. On the other hand, when computers are operated by people with minimal knowledge and skills, the probability of security breaches through error and inadvertence is greatly increased.
4.13.3 Motivation.
Motivation exists in numerous forms. It is present wherever valuable assets can be diverted for personal gain; it arises when real or fancied injustice creates a desire for revenge; and it can simply be a form of self-expression.
The unauthorized diversion of corporate assets always has provided opportunities for theft; now, with many employees owning computers at home, the value of stolen equipment, programs, and data can be realized without the involvement of third parties. When a third party is added to the equation and the thriving market in purloined personal data is factored in, the potential for data theft, a low-risk/high-return crime, is greatly increased.
Computers and networks are also a target for sabotage as well as data theft. The reliance upon such systems by governments, the military, large corporations, and other perceived purveyors of social or economic ills, means that criminal acts are likely to continue. Because personal computers are now part of these systems, they are also a link to any policy or practice of which one or more groups of people disapprove. The motivation for sabotaging personal computers is more likely in the near term to increase than it is to disappear.
A third motivation for breaching computer security is the challenge and excitement of doing so. Whether trying to overcome technical hurdles, to break the law with impunity or merely to trespass on forbidden ground, some hackers find these challenges irresistible, and they become criminal hackers. To view such acts with amused tolerance or even mild disapproval is totally inconsistent with the magnitude of the potential damage and the sanctity of the trust barriers that are crossed. Since the technology exists to lock out all but the most determined and technically proficient criminal hacker, failure to protect sensitive systems is increasingly viewed as negligence.
4.13.4 Opportunity.
With so many personal computers in almost every office, with virtually no supervision during regular hours, and certainly none at other times, opportunities are plentiful for two types of security breaches: intentional by those with technical knowledge and unintentional by those without.
4.13.5 Threats to Microcomputers.
Among the most significant threats to microcomputers are those pertaining to:
- Physical damage
- Theft
- Electrical power
- Static electricity
- Data communications
- Maintenance and repair
4.13.5.1 Physical Damage.
Microcomputers and their peripheral devices are not impervious to damage. Disk drives are extremely susceptible to failure through impact; keyboards cannot tolerate dirt or rough handling. It is essential that computers be recognized as delicate instruments and that they be treated accordingly.
Even within an access-controlled data center, where food and drinks are officially banned, it is not uncommon for a cup of coffee to be spilled when set on or near operating equipment. In an uncontrolled office environment, it is rare that one does not see personal computers in imminent danger of being doused with potentially damaging liquids. The problem is compounded by the common practice of leaving unprotected media such as CDs and DVDs lying about on the same surface where food and drink could easily reach them. Although it may not be possible to eliminate these practices entirely, greater discipline will protect data media and equipment from contamination.
As mentioned in the section on heat, damage also can result from blocking vents necessary for adequate cooling. Such vents can be rendered ineffective by placing the equipment too close to a wall or, in the case of laptops, on soft surfaces, such as carpets, that block vents on the base of the machine. Vents on top of computer housings and cathode ray tube–style displays are too often covered by papers or books that prevent a free flow of cooling air. As a result, the internal temperature of the equipment increases, so that marginal components malfunction, intermittent contacts open, errors are introduced, and eventually the system malfunctions or halts.
4.13.5.2 Theft.
The opportunities for theft of personal computers and their data media are far greater than for their larger counterparts. Files containing proprietary information or expensive programs are easily copied to removable media as small as a postage stamp and taken from the premises without leaving a trace. External disk drives are small enough to be carried out in a purse or an attaché case, and new thumb-size USB drives look like key fobs to the uninitiated. The widespread practice of taking portable computers home for evening or weekend work eventually renders even the most conscientious guards indifferent. In offices without guards, the problem is even more difficult. Short of instituting a police state of perpetual surveillance, what is to be done to discourage theft? Equipment can be chained or bolted to desks, or locked within cabinets built for the purpose. Greater diligence in recording and tracking serial numbers, more frequent inventories, and a continuing program of education can help. Most of all, it is essential that the magnitude of the problem be recognized at a sufficiently high management level so that adequate resources are applied to its solution. Otherwise, there will be a continuing drain of increasing magnitude on corporate profitability.
4.13.5.3 Power.
Even in a controlled data center, brownouts, blackouts, voltage spikes, sags and surges, and other electrical power disturbances represent a threat. The situation is much worse in a typical office, where personal computers are plugged into existing outlets with little or no thought to the consequences of bad power.
Some of the rudimentary precautions that should be taken are:
- Eliminating, or at least controlling, the use of extension cords, cube taps, and multiple outlet strips. Each unit on the same power line may reduce the voltage available to all of the others, and each may introduce noise on the line.
- Providing line voltage regulators and line conditioners where necessary to maintain power within required limits.
- Banning the use of vacuum cleaners or other electrical devices plugged into the same power line as computers or peripheral devices. Such devices produce a high level of electrical noise, in addition to voltage sags and surges.
- Connecting all ground wires properly. This is especially important in older offices equipped with two-prong outlets that require adapter plugs. The third wire of the plug must be connected to a solid earth ground for personnel safety, as well as for reduction of electrical noise.
In addition, the use of uninterruptible power supplies (UPSs) is highly recommended for all computers and ancillary equipment. These devices are available in capacities from about 200 watts for PCs to virtually unlimited sizes for mainframes. While the power line is operational, a UPS is capable of conditioning the line by removing electrical noise, sags, spikes, and surges. When line voltage drops below a preset value, or when power is completely lost, the UPS converts DC from its internal batteries to the AC required to supply the associated equipment.
Depending on its rating and the load, the UPS may provide standby power for several minutes to several hours. This is enough time to shut down a computer normally, or in the case of large installations, to have a motor generator placed online.
The services of a qualified electrician should be utilized wherever there is a possibility of electric power problems.
4.13.5.4 Static Electricity.
After one walks across a carpeted floor on a dry day, the spark that leaps from fingertip to computer may be mildly shocking to a person, but to the computer it can cause serious loss of memory, degradation of data, and even component destruction. These effects are even more likely when people touch components inside a computer without proper grounding.
To prevent this, several measures are available:
- Use a humidifier to keep the humidity above 20 percent relative.
- Remove ordinary carpeting. Replace, if desired, with static-free types.
- Use an antistatic mat beneath chairs and desks.
- Use a grounding strip near each keyboard.
- Wear a grounding bracelet when installing or repairing the components of any electronic equipment.
Touching the grounding strip before operating the computer will drain any static electricity charge through the attached ground wire, as will spraying the equipment periodically with an antistatic spray.
Some combination of these measures will protect personnel, equipment, and data from the sometimes obscure, but always real, dangers of static electricity.
4.13.5.5 Data Communications.
Although personal computers perform significant functions in a stand-alone mode, their utility is greatly enhanced by communications to mainframes, to information utilities, and to other small computers, remotely via phone lines or the Internet, or through local area networks. All of the security issues that surround mainframe communications apply to personal computers, with added complications.
Until the advent of personal computers, almost all terminals communicating with mainframes were “dumb.” That is, they functioned much like teletype machines, with the ability only to key in or print out characters, one at a time. In consequence, it was much more difficult to breach mainframe security, intentionally or accidentally, than it is with today's fully intelligent personal computers.
The image of thousands of dedicated hackers dialing up readily available computer access numbers, or probing Internet addresses, for illicit fun and games, or for illegal financial gain, is no less disturbing than it is real. Countermeasures are available, including:
- Two-way encryption (see Chapter 7)
- Frequent password changes (see Chapter 28)
- Automatic call-back before logging on
- Investigation of unsuccessful logons
- Monitoring of hackers' bulletin boards (see Chapters 12 and 15)
- Firewalls to restrict traffic into and out of the computer (see Chapter 26)
- Antivirus software (see Chapter 41)
Legislation that makes directors and senior officers personally liable for any corporate losses that could have been prevented should have a marked effect on overcoming the current inertia. Prudence dictates that preventive action be taken before, rather than corrective action after, such losses are incurred.
4.13.6 Maintenance and Repair.
A regular program of preventive maintenance should be observed for every element of a personal computer system. This should include scheduled cleaning of disk drives and their magnetic heads, keyboards, and printers. A vital element of any preventive maintenance program is the frequent changing of air filters in every piece of equipment. If this is not done, the flow of clean, cool air will be impeded, and failure will almost surely result.
Maintenance options for personal computers, in decreasing order of timeliness, include:
- On-site management by regular employees
- On-site maintenance by third parties under an annual agreement
- On-call repair, with or without an agreement
- Carry-in service
- Mail-in service
As personal computers are increasingly applied to functions that affect the very existence of a business, their maintenance and repair will demand more management attention. Redundant equipment and on-site backup will always be effective, but the extended time for off-site repairs will no longer be acceptable. For most business applications, “loaners” or “swappers” should be immediately available, so that downtime will be held to an absolute minimum. Management must assess the importance of each functioning personal computer and select an appropriate maintenance and repair policy.
Accessibility, knowledge, motivation, and opportunity are the special factors that threaten every personal computer installation. Until each of these factors has been addressed, no system can be considered secure.
4.14 CONCLUSION.
This chapter has dealt principally with the means by which hardware elements of a data processing system affect the security and integrity of its operations. Many safeguards are integral parts of the equipment itself; others require conscious effort, determination, and commitment.
An effective security program, —one that provides both decreased likelihood of computer catastrophe and mitigation of the consequences of damage, —cannot be designed or implemented without considerable expenditures of time and money. As with other types of loss avoidance, the premium should be evaluated against the expected costs. Once a decision has been made, however, this equivalent to an insurance policy should not be permitted to lapse. The premiums must continue to be paid in the form of periodic testing, continuous updating, and constant vigilance.
For more detailed information about risk management, see Chapter 62 in this Handbook. For a discussion of insurance policies against information systems disasters of all kinds, see Chapter 60.
4.15 HARDWARE SECURITY CHECKLIST
Mainframes
- Are security and integrity requirements considered when selecting new equipment?
- Is a schedule of preventive maintenance enforced?
- Is a log kept of all computer malfunctions and unscheduled downtime?
- Is there an individual with responsibility for reviewing the log and initiating action?
- Are parity checks used wherever possible?
- Is there an established procedure for recording parity errors and recovering from them?
- Are forward-acting or error-correcting codes used when economically justified?
- Do operators follow prescribed procedures after a read error or other machine check halt?
- Are all operator interventions logged and explained?
- Is a job log maintained, and is it compared regularly with an authorized run list?
- Is the interval timer used to prevent excessively long runs?
- Are storage protect features such as data locks and read-only paging used?
- Are keys to software data locks adequately protected?
- Are precautions taken to prevent loss of data from volatile memory during power interruptions?
- Are standard internal and external tape and disk labeling procedures enforced?
- Are write-enable protection rings always removed from tape reels immediately after use?
- Is there a rule that new tapes and disks must be tested or certified prior to use? At regular intervals thereafter?
- Are tapes and disks refinished or replaced before performance is degraded?
- Are air conditioners adequate for peak thermal loads? Are air conditioners backed up?
- Is there a schedule for frequent filter changes?
- Have all static electricity generators been disabled?
- Have all sources of water damage been eliminated?
- Is good housekeeping enforced throughout the facility?
- Is access to data terminals restricted?
- Are terminals and surrounding areas examined frequently to detect passwords carelessly left about?
- Is a log maintained of unsuccessful attempts to enter the computer from terminals?
- Is the log used to prevent further attempts?
- Is a log maintained of all successful entries to sensitive data?
- Is the log used to verify authorizations?
- Are terminals equipped with automatic identification generators?
- Are test procedures adequate to assure high-quality data transmissions?
- Is cryptography or scrambling used to protect sensitive data?
- Has a complete backup plan been formulated? Is it updated frequently?
- Does the backup plan include training, retraining, and cross-training of personnel?
- Is on-site backup available for the central processing unit? For peripherals?
- Does your backup site advise you of all changes to its hardware configuration and operating system?
- Does your backup site have enough free time available to accommodate your emergency needs?
- Do you monitor power-line voltage and frequency?
- Are the effects of brownouts, dimouts, and blackouts known?
- Is advance warning available, and if so, is there a checklist of actions to be taken?
- Are power correctors in use? Voltage regulators? Line conditioners? Lightning spark gaps?
- Is backup power available? Dual substation supply? Motor generators? Uninterruptible power supplies?
- Does your equipment provide automatic restart and recovery after a power failure?
- Are backup plans tested realistically? At frequent intervals?
Microcomputers
In addition to the appropriate items just listed:
- Are removable disks always kept in a closed container when not actually mounted in a disk drive?
- Is it forbidden to put food or drink on or near computer equipment?
- Are personal computers securely fastened to prevent dropping or theft?
- Are air vents kept free?
- Are accurate inventories maintained?
- Is electrical power properly wired?
- Are uninterruptable power supplies in place?
- Has static electricity been eliminated?
- Are data communications secure?
- Is there an effective maintenance plan?
4.16 FURTHER READING
Ayers, J. E. Digital Integrated Circuits: Analysis and Design. Boca Raton, FL: CRC Press, 2003. (Second edition scheduled for publication in 2009.)
Clements, A. Principles of Computer Hardware, 4th ed. New York: Oxford University Press, 2006.
Horak, R. Telecommunications and Data Communications Handbook. Hoboken, NJ: Wiley-Interscience, 2007.
Kerns, D. V. Essentials of Electrical and Computer Engineering, 2nd ed. Upper Saddle River, NJ: Prentice-Hall, 2004.
Pattern, D. A., and J. L. Hennessy. Computer Organization and Design: The Hardware Software Interface, 3rd ed. Los Angeles: Morgan Kaufmann, 2007.
Stallings, W. Computer Organization and Architecture: Designing for Performance, 7th ed. Upper Saddle River, NJ: Prentice-Hall, 2005.