
Although you could wait for the GoogleBot crawler to find your site on the Web, a more proactive approach is to manually submit your site for inclusion in the Google web index. It’s an easy process—in fact, the easiest thing we’ll discuss in this chapter.
All you have to do is go to www.google.com/addurl/, shown in Figure 38.1. Enter the URL for your home page into the appropriate box (including the http://), add any comments you might have, and then click the Add URL button. That’s it; Google will now add your site to the GoogleBot crawl list, and your site will appear in the appropriate search results.
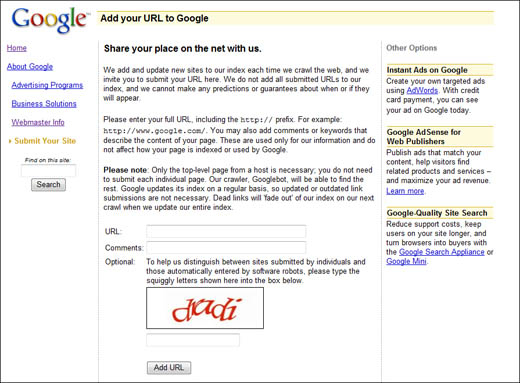
Note that you only have to add the top-level URL for your site; you don’t have to add URLs for any subsidiary pages. (For example, if your home page is http://www.homepage.com/index.html, enter only http://www.homepage.com.) GoogleBot will crawl the rest of your site once it finds the main URL.
If, for some reason, you want to remove your website from the Google index, the process is slightly more involved. What you need to do is place a special text file in the root directory of your website’s server. This file should be named robots.txt, and should include the following text:
User-agent: Googlebot
Disallow: /
This code tells the GoogleBot crawler not to crawl your site. If you want to remove your site from all search engines (by preventing all robots from crawling the site), include the following text instead:
User-agent: *
Disallow: /
If you only want to remove certain pages on your site from the Google index, insert the following text into the robots.txt file, replacing page.html with the filename of the specific page:
User-agent: Googlebot
Disallow: /page.html
Finally, you can use the robots.txt file to exclude all pages within a specific directory. To do this, insert the following text, replacing directory with the name of the directory:
User-agent: Googlebot
Disallow: /directory
There’s another, better way to get your site listed in the Google index. This method lets you submit the URLs for every page on your website, manage the status of your pages, and receive reports about the visibility of your pages on Google. You do this by submitting a sitemap—literally, a map of the URLs of your entire site—to Google Sitemaps.
Tip
To disallow other specific crawlers and spiders, see the (long) list at www.robotstxt.org/db.html.
Google Sitemaps serves two general purposes. First, it helps to keep Google informed of all the new and updated pages on your site—in other words, to improve the freshness of the Google index. Second, the program should help to increase the coverage of all your web pages in the Google index. The first goal benefits Google; the second benefits you; and both goals should benefit Google’s search users. Participation in Google Sitemaps is free.
Note
Google also has a separate Mobile Sitemaps program to add pages to its Mobile Web Index. Learn more information at www.google.com/webmasters/sitemaps/docs/en/mobile.html.
Note that the Google Sitemaps program supplements, rather than replaces, the usual methods of adding pages to the Google index. If you don’t participate in Google Sitemaps, your pages may still be discovered by the GoogleBot crawler, and you may still manually submit your site for inclusion in the Google index.
At first glance, creating a sitemap might seem daunting. Do you have to write down every URL on your site by hand?
Well, of course you don’t; the whole sitemap process can be automated. To that end, many third-party sitemap generator tools exist for just that purpose.
For most of these tools, generating a sitemap is as simple as entering your home page URL and then pressing a button. The tool then crawls your website and automatically generates a sitemap file; this typically takes just a few minutes. Once the sitemap file is generated, you can then submit it to Google Sitemaps, as we’ll discuss in short order.
Some of these sitemap tools are web-based, some are software programs, and most are free. The most popular of these tools include the following:
-
AutoMapIt (www.automapit.com)
-
AutoSitemap (www.autositemap.com)
-
G-Mapper (www.dbnetsolutions.co.uk/gmapper/)
-
GSiteCrawler (www.gsitecrawler.com)
-
Gsitemap (www.vigos.com/products/gsitemap/)
-
Site Magellan (www.sitemagellan.com)
-
SitemapsPal (www.sitemapspal.com)
-
SitemapDoc (www.sitemapdoc.com)
-
XML-Sitemaps.com (www.xml-sitemaps.com)
In most instances, you should name your sitemaps file sitemaps.xml and place it in the uppermost (root) directory of your website—although you can name and locate it differently, if you like.
Note
Google also offers its own free sitemap generator (www.google.com/webmasters/tools/docs/en/sitemap-generator.html)—although, to be honest, it’s not quite as user-friendly as some of the third-party tools available.
After you’ve created your sitemap, you have to let Google know about it. There are two ways to do this—the easy way and the hard way.
The hard way (which isn’t all that hard) is to reference your sitemap within your site’s robots.txt file, which should be located in the root directory of your website.
What you need to do is add the following line to your robots.txt file:
SITEMAP: www.sitename.com/sitemaps.xml
Naturally, you need to include the actual location of your sitemaps file. The preceding example works only if you have the file in your site’s root directory; if it’s in another directory, include that full path. Also, if you’ve named your sitemaps file something other than sitemaps.xml, use the actual name, instead.
The next time the GoogleBot spider crawls your site, it will read your robots.txt file, learn the location of your sitemaps file, and then read the information in that file. It will then crawl all the pages listed in the file, and submit information about each page to the search engine for indexing.
If all you’re interested in is Google reading your sitemap (fie on you, Yahoo!), then you can submit your sitemap directly to Google Sitemaps. This ensures that Google will know about your sitemap—and its contents.
Tip
The advantage of referencing your sitemap via the robots.txt file is that it makes your sitemap visible to searchbots from all the major search engines, not just Google. Every searchbot reads the robots.txt file and thus is directed to your sitemap.
To upload your sitemap to Google, follow these steps:
-
Upload your sitemap file to the highest-level directory (typically the root directory) on your web server.
-
Go to your Webmaster Tools Dashboard (www.google.com/webmasters/tools/dashboard).
-
If your site is not yet added to your Dashboard, do so now.
-
Click the Add a Sitemap link beside your site.
-
When prompted, select which type of sitemap you’re adding—for most web pages, that’s a general web sitemap.
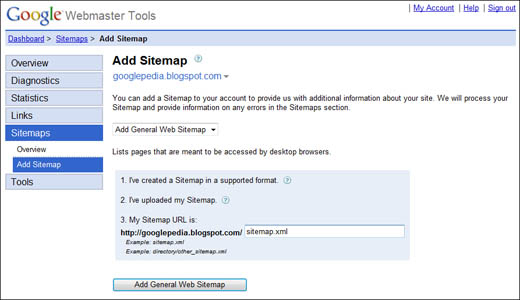
-
The Add Sitemap page now expands, as shown in Figure 38.2. Check that you’ve created the sitemap in a supported format and uploaded your sitemap to your website’s highest-level directory.
-
Enter the URL for the sitemap file.
-
Click the Add General Web Sitemap button.
Note
Even when you submit a complete sitemap, Google doesn’t guarantee that it will crawl or index all the URLs on your website. However, since Google uses the data in your sitemap to learn more about your site’s structure, it should improve the crawler schedule for your site, and ultimately improve the inclusion of your site’s page in Google’s search results.
Making sure your web pages are included in the Google search index is one thing; working to ensure a high PageRank within those results is something else. The process of tweaking your website to achieve higher search results on Google and other search sites is called search engine optimization (SEO), and it’s a major consideration for all big-time webmasters.
Tip
To learn more about search engine optimization in general, check out my companion book, The Complete Idiot’s Guide to Search Engine Optimization (Alpha Books, 2008).
To increase your site’s ranking in Google’s search results, you have to increase your site’s PageRank. There are a number of ways to do this, almost all of which involve manipulating the content and HTML code of your site. Read on to learn some of the most effective techniques.
Probably the biggest impact you can have on your site’s PageRank is to increase the number of sites that link to the pages on your site. (These are called inbound links.) As you learned back in Chapter 1, “Inside Google,” the PageRank rating is based on a complex and proprietary algorithm, which is heavily weighted in favor of inbound links to your site. The more sites that link to your site—and the higher the PageRank of those links sited—the higher your site’s PageRank will be.
To increase your PageRank, then, you want to get more higher-quality sites to link back to your site. And it’s not enough for those sites to have a high PageRank; they should also have content that is relative to your site. For example, if you have a site about NASCAR racing, you’ll get more oomph with a link from another NASCAR-related site than you would with a link from a site about Barbie dolls. Relevance matters.
The GoogleBot crawler can find more content on a web page and more web pages on a website if that content and those pages are in a clear hierarchical organization.
Let’s look at page organization first. You want to think of each web page as a mini-outline. The most important information should be in major headings, with lesser information in subheadings beneath the major headings. One way to do this is via standard HTML heading tags, like this:
<h1>Most important information
<h2>Less important information
<h3>Least important information
This approach is also appropriate for your entire site layout. Your home page should contain the most important information, with subsidiary pages branching out from that containing less important information—and even more subpages branching out from those. The most important info should be visible when a site is first accessed via the home page; additional info should be no more than a click or two away.
This hierarchical organization is easily seen when you create a sitemap for your users. (This is distinct from the sitemap you create for and submit to Google Sitemaps.) A visible sitemap, looking for all the world like a big outline, not only makes it easier for visitors to find information on your site, it also gives the GoogleBot crawler some very meaty information to process.
Just as important as a page’s layout is the page’s content. You want to make sure that each and every page on your site contains the keywords that users might use to search for your pages. If your site is all about drums, make sure your pages include words like drums, percussion, sticks, heads, drumset, cymbals, snare, and the like. Try to think through how you would search for this information, and work those keywords into your content.
Think about hierarchy and think about keywords, and then think about how these two concepts work together. That’s right, you want to place the most important keywords higher up on your page. The GoogleBot will only crawl so far, and you don’t want it to give up before key information is found. In addition, PageRank is partially determined by content; the more important the content looks to be on a page (as determined by placement on the page), the higher the PageRank will be.
Google also looks to highlighted text to determine what’s important on a page. It follows, then, that you should make an effort to format keywords on your page as bold or italic.
Here’s something you might not think about. At present, Google parses only text content; it can’t figure out what a picture or graphic is about, unless you describe it in the text. So, if you use graphic buttons or banners (instead of plain text) to convey important information, Google simply won’t see it. You need to put every piece of important information somewhere in the text of the page—even if it’s duplicated in a banner or graphic.
If you do use images on your site, make sure you use the <ALT> tag for each image, and assign meaningful keywords to the image via this tag. GoogleBot will read the <ALT> tag text; it can’t figure out what an image is without it.
Following on the previous tip, make sure that you link from one page to another on your site via text links—not via graphics or fancy JavaScript menus. Google will find and use the text links to crawl other pages on your site; if the links are non-text, GoogleBot might not be able to find the rest of your site.
When calculating PageRank, Google not only considers the visible content on a page; it also evaluates the content of key HTML tags—in particular, your site’s <META> tags. You want to make sure that you use <META> tags in your page’s code, and assign important keywords to each of those tags.
The <META> tag, which (along with the <TITLE> tag) is placed in the head of your HTML document, can be used to supply all sorts of information about your document. You can insert multiple <META> tags into the head of your document, and each tag can contain a number of different attributes. The two most important <META> attributes, when it comes to search index ranking, are DESCRIPTION and KEYWORDS. You use the first to provide a brief description of the page’s content; you use the second to list all the important keywords that might be used to search this page.
You use separate <META> tags to define different attributes, using the following format:
<META name="attribute" content="items">
Replace attribute with the name of the particular attribute, and items with the keywords or description of that attribute.
Note
There are many more <META> attributes than the ones listed here (such as CHANNEL, DATE, and so on), but neither Google nor most other search engines read them.
For example, to include a description of your web page, you’d enter this line of code:
<META name="DESCRIPTION" content="All about stamp collecting">
To add keywords that GoogleBot can index, enter this line of code:
<META name="KEYWORDS" content="stamps, stamp collecting, collectable
stamps, stamp history, stamp prices">
Note that you separate each keyword by a comma, and that a “keyword” can actually be a multiple-word phrase. You can include up to 10 keywords with this attribute.
You can include all three of these <META> attributes in the head of your HTML document, each in separate lines of code, one after another, like this:
<META name="DESCRIPTION" content="All about stamp collecting">
<META name="KEYWORDS" content="stamps, stamp collecting, collectable
stamps, stamp history, stamp prices">
Your page’s title is important because it’s one of the first places that Google’s searchbot looks to determine the content of your page. GoogleBot figures, hopefully rightly so, that the title accurately reflects what the page is about; for example, if you have a page titled “The Dutch Apple Pie Page,” that the page is about Dutch apple pies. Unless you mistakenly or purposefully mistitle your page, the searchbot will skim off keywords and phrases from the title to use in its search engine index.
In addition, when your page appears on Google’s search results page, the title is the search engine uses as the listing name. The title is also what appears in the favorites list when a visitor adds your site as a favorite.
For all these reasons, you need to get your most important keywords and phrases into your page’s title—which you do via the HTML <TITLE> tag. In fact, <TITLE> tag is just as important as the <META> tag—which is why you shouldn’t fall into the trap of assigning only your site name to the tag. Instead, the <TITLE> tag should contain two to three important keywords, followed by the site name.
Tip
What’s the ideal length of a title? There’s a 64-character limit (anything beyond that gets truncated), and you should probably pace your title to include anywhere from 3 to 10 words total. This makes the title both readable for users (short enough to scan) and useful for Google and other search engines (long enough to include a handful of keywords).
For example, if your stamp collecting site is called The Stamp Shop, you might use the following <TITLE> tag:
<TITLE>The Stamp Shop - Collecting, Prices, and History</TITLE>
This is a tough one. Most cutting-edge web designers have switched from standard heading tags (<H1>, <H2>, and so on) to Cascading Style Sheet (CSS) <DIV> and <SPAN> codes. That’s unfortunate, as Google looks for the old-fashioned heading tags to determine the content (and thus the PageRank) of your site. If you want to optimize your ranking in the Google index, you’ll switch back to the <H1> and <H2> tags for your page headings—and make sure you use the content of those tags wisely.
GoogleBot crawls the Web with some frequency, looking for pages that have changed or updated content. If your site hasn’t changed in awhile, this can affect your PageRank. So you’ll want to make sure you change your content on a regular basis; in particular, changing the content of your heading tags can have a big impact on how “fresh” Google thinks your site is.
Contrary to the previous advice, Google actually has a problem tracking some frequently updated content—in particular, the type of dynamic content generated by blogs, news sites, and the like. Put simply, GoogleBot doesn’t crawl dynamic pages as well as it does static pages. (It has to do with how long it takes some dynamic pages to load; spiders only allocate a certain amount of time per page before they move on to the next site to index.)
There are two solutions to this problem. One is to use a content management system (CMS) that loads fast enough to appease the GoogleBot crawler. The second solution is to publish your dynamic content as an RSS feed. This second solution is probably the best one, as Google does a really good job digesting RSS feeds to populate its search index. When in doubt, make sure that you generate an RSS feed for all your dynamic content.
I’ve saved the best SEO tip to the last. If you want to increase your Google PageRank, increase the quality of your site’s content. It’s simple: The better your site is, content-wise, the higher it will rank.
That’s right, when it comes to search rank, content is king. Google’s goal is to figure out what your site is all about so it can better answer its users search queries. The higher quality and more relevant your site’s content to a particular search, the more likely it is that Google will rank your site higher in its results.
So forget all about keywords and <META> tags for the time being, and focus on what it is your site does and says. If your site is about quilting, work to make it the most content-rich site about quilting you can. Don’t skimp on the content; the more and better content you have, the better.
Now that you know the things you can do to increase your site’s ranking, let’s take a quick look at the things you shouldn’t do—that is, things that can actually decrease your site’s PageRank.
There are some things you can do to your site that Google absolutely, positively won’t like. And when Google doesn’t like something, your PageRank suffers—or, worst-case scenario, you don’t show up in the search index at all.
What are some of these ill-considered techniques? Here’s a short list:
-
Long and complicated URLs. The shorter and more straightforward a page’s URL, the better. Google doesn’t like long URLs, nor does it like URLs that contain special characters. To that end, don’t use &id= as a parameter in your URLs; similarly, avoid the use of dynamic URLs. Google indexes only static URLs, not those that are dynamically generated. If your site does include dynamic pages, use a URL rewrite tool to turn your dynamic URLs into static ones.
-
Splash pages. Here’s the thing about splash pages (those introductory pages that appear before users can advance to your site’s true home page): Nobody likes ’em. Visitors don’t like them, because they make it longer to get into your site. And Google doesn’t like them, because they don’t include the types of internal links and menus found on a true home page; nor do they include much, if any, text content. (If there are no links to other pages from the first page that GoogleBot encounters, it won’t know about the other pages on your site.) So, you should make your site’s first page a traditional home page, not a splash page; both your visitors and the searchbots will be much happier.
-
High keyword density. Although keywords are good, too many of them are bad. (Google assumes that you’re including keywords just to get a high PageRank, instead of creating unique content for your users.) So don’t include too many keywords (especially repeated keywords) in your content or <META> code. If a page has too high a keyword density, Google will categorize your page as a doorway page—and penalize you accordingly.
-
Hidden text. This is when you disguise keywords or links by making them the same or similar color as the page background, using a tiny font size, or hiding them within the HTML code itself. Many webmasters think this is a clever way to stuff lots of keywords onto a page without looking as if they’re doing so. Unfortunately, you can’t trick a searchbot; GoogleBot sees hidden text just as easily as it does the regular text on your page—which means they’ll see all those keywords you’re trying to stuff. And, as you know, searchbots don’t like keyword stuffing.
-
Duplicate content. Here’s another false trick that too-savvy webmasters sometimes employ, to their own detriment—duplicating content on a site, in the hopes of increasing the number of hits in search engine results. This may be done by putting the same content on multiple pages, or via the use of multiple domains or subdomains. Unfortunately, duplicating content is a bad idea, as Google utilizes duplicate content filters that will identify and remove duplicate sites from their search results. When you duplicate your content, you run the risk that your main site or page will be filtered out—while the subsidiary content remains!
-
Bad outbound links. You know that the quality of your inbound links matters; did you know that the quality of your outbound links can also affect your search rankings? That’s right, Google considers the sites you link to as part of its page-ranking process—at least when it comes to overtly low-quality sites. For that reason, you don’t want to link to a site that’s been dropped or banned from a search engine’s index; you could get tarred by relation.
-
Images, videos, and animations. It’s a simple concept—searchbots read text (including HTML code); they can’t view images, videos, or Flash animations. Which means, of course, that creating an image- or animation-heavy page renders that page virtually invisible to Google’s spider. Your page might look great to visitors, but if GoogleBot can’t see it, it won’t get indexed. When in doubt, go with a text-based approach.
-
Big pages. Here’s another reason to go easy on web page images: GoogleBot doesn’t like big pages. More specifically, it doesn’t like long load times. If it takes too much time for all the elements on a page to load, GoogleBot will give up and move on to the next page in its queue—bad for you.
-
JavaScript code. As you’ve learned, Google’s spider reads text and HTML code—well, some HTML code. GoogleBot will ignore JavaScript code in your HTML, which means anything you have in a script won’t be indexed. This is particularly vexing if you use a JavaScript menu system; searchbots may not see all the internal links you have in your menus.
-
Too much code. Speaking of HTML code, don’t overdo it. Having more code than you do actual text on your page will cause GoogleBot to give up before your entire page is crawled. You should avoid employing too many code-heavy effects, such as nested tables or JavaScript effects. If your important text is buried under hundreds of lines of code, you’ll be at a disadvantage compared to a well-optimized site.
-
Messy code. One last thing when it comes to the coding of your site: Don’t create messy code. This is one instance where neatness counts; messy HTML can confuse Google’s searchbot and cause it to miss important content.
The previous section talked about things you might accidentally do that can adversely affect your PageRank rating. There are also some practices that sneaky web designers deliberately do to increase their page rank; Google takes issue with these practices, and can ban you from their index if you’re caught.
Note
Any attempt to influence search engine rank via misleading methods is referred to as search engine spamming or spamdexing. The practice of creating a website solely for the purpose of achieving a high PageRank is called Googleating (pronounced “Google-ating,” not “Google-eating”).
To that end, here are some of the more nefarious outlawed optimization practices:
-
Google bombing. Sometimes called Google washing or link bombing, this is an attempt to increase your PageRank by having a large number of sites link to a page by using identical anchor text. For example, you might register several domains and have them all link to a single site using the same anchor text for the links. Searching for the term used in the link anchor text will return the linked-to site high in the search results. (Google bombing often occurs in blogs, where a site owner will “bomb” multiple blog postings with replies linking to the owner’s site.)
-
Keyword stuffing. This is when you insert hidden, random text on a page to increase the keyword density, and thus increase the apparent relevancy of a page. For example, if your page is about trains, you might insert several lines of invisible text at the bottom of the page repeating the keyword train, over and over, or include multiple instances of the word train in a <META> tag. In the past, some search engines simply counted how often a keyword appeared on a page to determine relevance; today, Google employs algorithms to detect keyword stuffing. (A related technique is meta tag stuffing, where keywords are stuffed into HTML meta tags.)
-
Doorway pages. This is a web page that is low in actual content, instead stuffed with repeating keywords and phrases designed to increase the page’s search rank. Doorway pages typically require visitors to click a “click here to enter” link to enter the main website; in other instances, visitors to a doorway page are quickly redirected to another page.
-
Link farms. This is a group of web pages that all link to one another. The purpose of a link farm is to increase the number of links to a given site; since PageRank is at least partially driven by the number of linked-to pages, using a link farm can make it appear as though a large number of sites are linking to a given site.
-
Mirror websites. This is the hosting of multiple websites, all with the same content, but using different URLs. The goal is to increase the likelihood that any one (or more) of the mirror sites will appear on Google’s search results pages.
-
Cloaking. This is an attempt to mislead Google by serving up a different page to the GoogleBot crawler than will be seen by human visitors. This is sometimes used for code swapping, where one page is optimized to get a high ranking, and then swapped out for another page with different content.
-
Scraper sites. This is a site that “scrapes” results pages from Google and other search engines to create phony content for a website. A scraper site is typically full of clickable ads.