
MLE is an important general method to estimate the parameters of a statistical model. It relies on the likelihood function that computes how likely it is to observe the sample of output values for a given set of both input data as a function of the model parameters. The likelihood differs from probabilities in that it is not normalized to range from 0 to 1.
We can set up the likelihood function for the linear regression example by assuming a distribution for the error term, such as the standard normal distribution:
 .
.
This allows us to compute the conditional probability of observing a given output  given the corresponding input vector xi and the parameters,
given the corresponding input vector xi and the parameters, 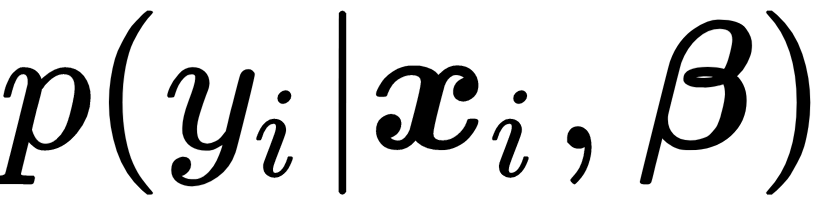 :
:
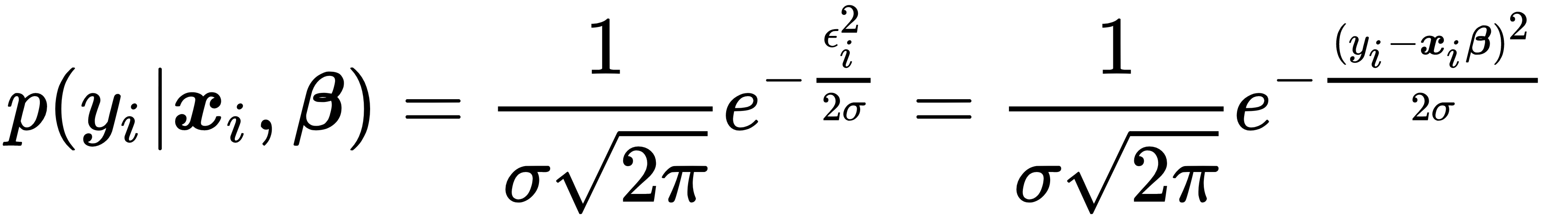
Assuming the output values are conditionally independent given the inputs, the likelihood of the sample is proportional to the product of the conditional probabilities of the individual output data points. Since it is easier to work with sums than with products, we apply the logarithm to obtain the log-likelihood function:

The goal of MLE is to maximize the probability of the output sample that has in fact been observed by choosing model parameters, taking the observed inputs as given. Hence, the MLE parameter estimate results from maximizing the (log) likelihood function:
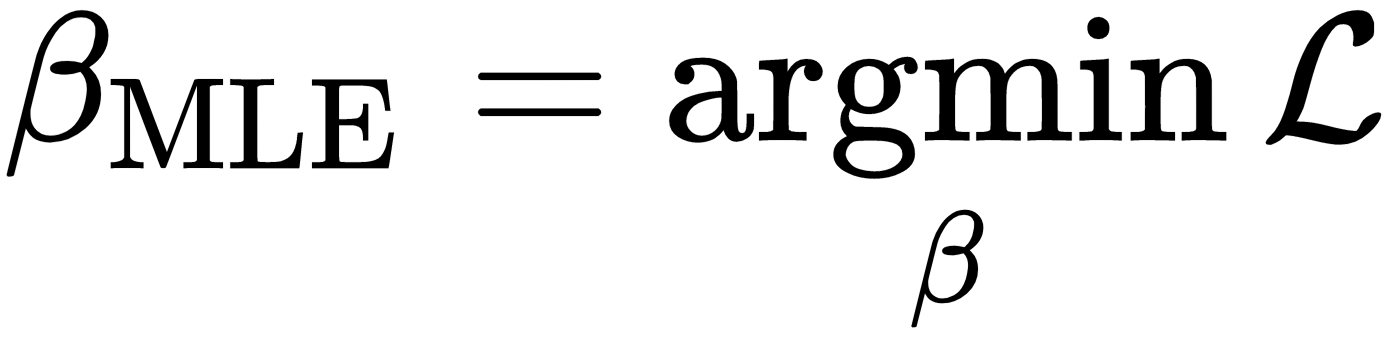
Due to the assumption of normal distribution, maximizing the log-likelihood function produces the same parameter solution as least squares because the only expression that depends on the parameters is squared residual in the exponent. For other distributional assumptions and models, MLE will produce different results, and in many cases, least squares is not applicable, as we will see later for logistic regression.