
The theorem that Reverend Thomas Bayes came up with over 250 years ago uses fundamental probability theory to prescribe how probabilities or beliefs should change as relevant new information arrives. The following quote by – John Maynard Keynes captures the Bayesian mindset:
It relies on the conditional and total probability and the chain rule; see the references on GitHub for reviews of these concepts.
The belief concerns a single or vector of parameters θ (also called hypotheses). Each parameter can be discrete or continuous. θ could be a one-dimensional statistic like the (discrete) mode of a categorical variable or a (continuous) mean, or a higher dimensional set of values like a covariance matrix or the weights of a deep neural network.
A key difference of frequentist statistics is that Bayesian assumptions are expressed as probability distributions rather than parameter values. Consequently, while frequentist inference focuses on point estimates, Bayesian inference yields probability distributions.
Bayes' Theorem updates the beliefs about the parameters of interest by computing the posterior probability distribution from the following inputs, as shown in the following diagram:
- The prior distribution indicates how likely we consider each possible hypothesis.
- The likelihood function outputs the probability of observing a dataset given certain values for the θ parameters.
- The evidence measures how likely the observed data is given all possible hypotheses. Hence, it is the same for all parameter values and serves to normalize the numerator:
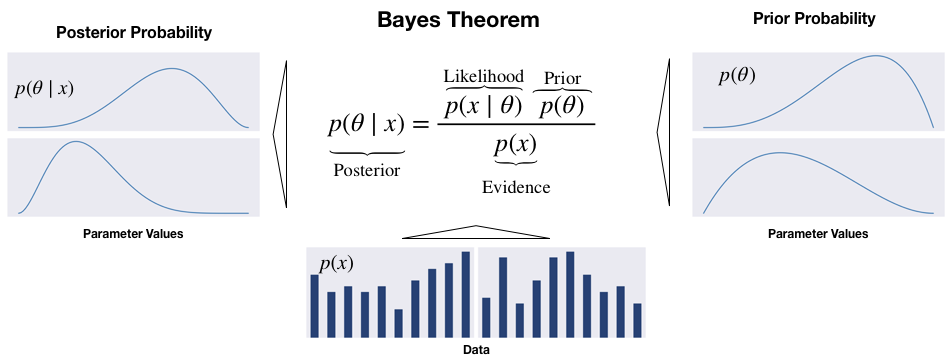
The posterior is the product of prior and likelihood, divided by the evidence, and reflects the updated probability distribution of the hypotheses, taking into account both prior assumptions and the data. Viewed differently, the product of the prior and the likelihood results from applying the chain rule to factorize the joint distribution of data and parameters.
With higher-dimensional, continuous variables, the formulation becomes more complex and involves (multiple) integrals. An alternative formulation uses odds to express the posterior odds as the product of the prior odds times the likelihood ratio (see the references for more details).