![14.6 DECIMATOR DAG FOR s2 = [1 −1]](https://imgdetail.ebookreading.net/cover/cover/software_development/EB9780470934630.jpg)
14.6 DECIMATOR DAG FOR s2 = [1 −1]
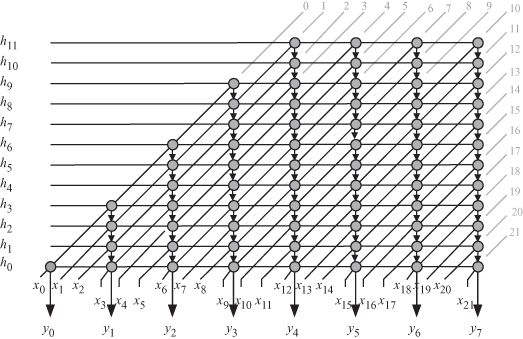
The DAG corresponding to s2 is shown in Fig. 14.6. The equitemporal planes are indicated by the gray lines and the time index values are indicated by the grayed numbers associated with the equitemporal planes. We note from the figure that a maximum of 12 tasks or nodes is active at any time step, which corresponds to the anti-aliasing filter length N. It should also be noted that the time values are associated with the high data rate of the decimator input.
Figure 14.6 M-to-1 decimator DAG for the case when M = 3, N = 12, and s2 = [1 − 1].
Chapters 10 and 11 explained that the projection operation assigns a node or a group of nodes in the DAG to a thread or processor. The number of assigned nodes determines the workload associated with each task. The operation also indicates the input and output data involved in the calculations. The projection operation controls the workload assigned to each thread/processor at each stage of the execution of the SPA. We have three possible valid projection vectors:
(14.18)
![]()
(14.19)
![]()
(14.20)
![]()
These projection directions correspond to the projection matrices
(14.21)
![]()
(14.22)
![]()
(14.23)
![]()
We consider only the design corresponding to d2a since the other two designs will be more complex and will not lead to a better task workload. A point in the DAG given by the coordinates p = [n k]t will be mapped into a point in ![]() given by
given by
(14.24)
![]()
Input samples are supplied to the nodes at the same time step. In that sense, the input samples are broadcast and the output samples are pipelined. We note, however, that each node is active once every M time steps. In order to reduce the number of nodes, we modify the linear projection operation above to employ a nonlinear projection operation:
(14.25)
![]()
Figure 14.7 shows the ![]() architecture for Design 2a. Figure 14.7a shows the
architecture for Design 2a. Figure 14.7a shows the ![]() where input samples are broadcast between the tasks and the partial results for the output samples are pipelined among the tasks. Note that the number of tasks required is N/M. Figure 14.7b shows the task detail. The workload of each task is simple in processing and control structures. Each task accepts input samples and forwards the inputs to the next task after a delay of M time steps. During each M time step, each task accumulates the partial results then loads the accumulated data to the parallel adder using a software barrier or a tristate buffer as shown on the left of the figure. All tasks pipeline the incoming data x(n) at the high data rate T and perform the filtering operation at the high data rate T also. The output is obtained from the rightmost task at times iMT.
where input samples are broadcast between the tasks and the partial results for the output samples are pipelined among the tasks. Note that the number of tasks required is N/M. Figure 14.7b shows the task detail. The workload of each task is simple in processing and control structures. Each task accepts input samples and forwards the inputs to the next task after a delay of M time steps. During each M time step, each task accumulates the partial results then loads the accumulated data to the parallel adder using a software barrier or a tristate buffer as shown on the left of the figure. All tasks pipeline the incoming data x(n) at the high data rate T and perform the filtering operation at the high data rate T also. The output is obtained from the rightmost task at times iMT.
Figure 14.7 ![]() for Design 2a for s2, d2a, N = 12, and M = 3. (a) Resulting
for Design 2a for s2, d2a, N = 12, and M = 3. (a) Resulting ![]() . (b) Task detail when the
. (b) Task detail when the ![]() is implemented in hardware systolic arrays.
is implemented in hardware systolic arrays.
