
4.3 SYNCHRONIZATION AND MUTUAL EXCLUSION
Each process or thread operating on a shared variable has a segment of code called critical section, where the process operates on the shared variable by changing its value. When a process is executing its critical section, no other process on any processor is allowed to execute its critical section. Figure 4.6 shows a segment of code containing a critical section. When a process reaches the critical section code, it is allowed to enter it and to execute that code section only if it can acquire a lock. As soon as the process is done with the critical section, it releases the lock and proceeds to execute the code after the critical section. If two or more processes reach the critical section, only one process is allowed to acquire the lock. All other processes wait at the start of the critical section.
Figure 4.6 Segment of code showing a critical section within a normal code.

Dijkstra [36] and Knuth [132] showed that it is possible to provide synchronization and mutual exclusion using atomic read and write operations [37]. Atomic operations ensure that the memory read, modify, then write operation to a certain location is done without interference from other processors. This basic capability is provided by hardware and enables the construction of more elaborate software algorithms. Examples of low-level hardware atomic operations include memory load/store and test&set [38–40].
These low-level synchronization primitives can be used by software to build high-level atomic operations such as locks, semaphore, monitors, and barriers. One must be careful when a process or thread acquires a lock or barrier in a multiprocessor system. The process holding the lock must not be preempted so that other processes waiting to acquire the lock are not delayed. One solution is to provide a preemption-safe locking [41].
Synchronization processes or threads involve three events [37–39]:
Acquire: where a process or thread tries to acquire the synchronization primitive (e.g., a mutex or barrier)
Wait: where the thread efficiently waits for the synchronization primitive to become available.
Release: when a thread has finished its operation, it must inform other processes or threads that the synchronization primitive is available. This allows other threads to acquire the primitive or to proceed beyond past the synchronization event.
A process or thread waiting for a synchronization primitive to become available employs a waiting algorithm. Waiting algorithm could be implemented by busy-waiting or blocking. The latter choice does not waste central processing unit (CPU) resources but carries more overhead for suspending and resuming the thread. This is the reason why busy-waiting is more appropriate when the waiting period is short and the blocking is appropriate when the wait period is long [37]. Busy-waiting in multiprocessor systems does not scale well. The waiting processes actually will test the shared lock using the copies in their own caches. However, as soon as the lock is released, all processes become aware of this new condition and will use the interconnection network while attempting to access the released shared lock in the shared memory. This will lead to increased traffic on the interconnection network and to memory contention.
4.3.1 Synchronization: Locks
Any solution to the critical section problem requires a lock [40]. A lock essentially serializes access to a shared resource so that only one process or thread reads and modifies the variable at any given time. As we mentioned at the start of this section, a process must acquire the lock before it is allowed to enter the critical section as shown in Fig. 4.6. A lock is provided in hardware to simplify program development and to move some of the processing load off the operating system.
The critical section could be handled in a single processor using interrupt prevention when a process is operating on the shared variable. This solution is not practical in a multiprocessor system since all processors must be informed of the interrupt disable. Time will be wasted while this message is being broadcast among the processors.
A lock is provided in hardware by a special atomic TestAndSet () instruction. That instruction returns the value of the lock (the test part) and then sets the value of the lock to 1 upon completion.
The lock is a value in memory where the operation read–modified–write is performed atomically using that instruction. The atomic TestAndSet () function is implemented in hardware but a pseudocode is illustrated as follows [37, 40]:
1: boolean TestAndSet (boolean *lock)
2: {
3: boolean v = *lock; // Test (read) operation
4: *lock = TRUE; // Modify (set) and Write operations
5: return v;
6: }
Line 1 declares the function and defines its body.
Line 3 performs the test portion of the atomic instruction by reading the value of the lock.
Line 4 modifies the lock and updates the value of the lock. If the lock was originally TRUE, no harm is done by writing TRUE again. However, if the lock was FALSE, then the lock becomes available and the process is informed of this fact through the variable v. The process also atomically sets the lock to TRUE to make it unavailable to other processes.
Line 5 returns the original value of the lock to be used by the process to decide whether to enter the critical section or not.
The TestAndSet () function can now be used to by a process to control entering the critical section when the lock is available or when waiting for the lock to become available as follows:
1: Code before critical section
2:
3: // Attempt to acquire lock
4: while (TestAndSet (&lock))
5: ; // no action and continue testing lock
6:
7: // Start of critical section
8: critical section code
9: // End of critical section
10: lock = FALSE; // release lock
11:
12: Code after critical section
Line 1 represents the normal code just before the critical section.
Line 4 is where the process tests the value of the lock in an infinite WHILE loop. The loop ends if the lock value is FALSE and the process acquires the lock and proceeds to execute its critical section. Line 8 represents the critical section.
Line 10 releases the lock at the end of the critical section. Line 12 is the code after the critical section.
The similarity of processes attempting to acquire the lock and the medium access control (MAC) problem in computer communications or networks should be noted here. Table 4.4 summarizes the similarities between mutual exclusion and MAC in telecommunications.
Table 4.4 Similarities between Mutual Exclusion and MAC
| Mutual exclusion | MAC |
| Critical section | Transmitted packet |
| Process/thread | User/node |
| Lock | Channel |
| Lock acquired | Channel acquired by node |
| Lock available | Channel free |
| Lock unavailable | Channel busy |
| Release lock | End of transmission |
| Test lock | Check channel state |
| Busy-waiting | User in backoff mode |
4.3.2 Synchronization: Mutex
A mutex M is a binary number that can have the values 0 and 1, which proves useful in mutual exclusion. The mutex is initially given the value 1 to allow any thread that needs it to enter its critical section. When a thread acquires the mutex and enters its critical section, it locks it by decrementing its value. When the thread is finished with its critical section, it releases the mutex by incrementing its value. Any thread arriving at the critical region while the lock is in use will wait because the mutex is already at 0. The result is that at most, one thread can enter into the critical section and only after it leaves can another enter. This sort of locking strategy is often used to serialize code that accesses a shared global variable and to ensure mutual exclusion.
There are two basic atomic operations to apply to the mutex: wait() and signal(). The pseudocodes for these two operations are as follows:
1: wait (M) 1: signal (M)
2: while M <= 0 2: {
3: { 3: M++; // increment M
4: ; // do nothing 4: }
5: M– –; // decrement M if it is 1
6: }
wait() effectively prevents the thread from entering its critical section while the mutex M = 0. As soon as M = 1, the thread can proceed to execute its critical section.
In the thread library POSIX, the wait() function is implemented using the library call pthread mutex lock(mutex *M). The signal() function is implemented using the library call pthread mutex unlock(mutex *M).
The wait() and signal() functions can now be used by a process to control entering the critical section when the lock is available or when waiting for the lock to become available as follows:
1: Code before critical section
2:
3: // Attempt to acquire mutex
4: wait(M);
5: ; // no action and continue testing mutex
6:
7: // Start of critical section
8: critical section code
9: // End of critical section
10: signal(M); // release mutex
11:
12: Code after critical section
Needless to say, the programmer must ensure that the critical section is surrounded by the correct wait() and signal() function calls and in the correct order. Failure to do so will result in wrong results that are difficult to track down.
4.3.3 Synchronization: Barriers
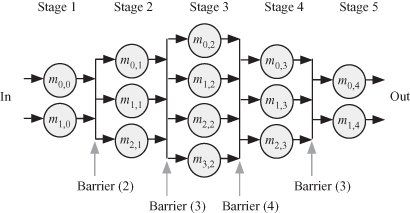
The examples of locks and mutexes we discussed in the previous two sections were used when several tasks or threads operated on shared variables in their critical sections. A synchronization barrier, on the other hand, is used when several independent tasks or threads are employed to perform several chores in parallel. There are no shared variables between those threads. The synchronization barrier is used for event synchronization where a specified number of tasks must be completed before the rest of the tasks are allowed to proceed. A barrier would be very useful to implement serial–parallel algorithms (SPAs) where several parallel tasks must be completed before moving on to the next state of algorithm execution. Figure 4.7 shows an example of a SPA where barriers are used between the parallel tasks. In the figure, we have the SPA consisting of five stages and we assumed that each task is to be executed by a thread. The number of parallel tasks executed at each stage varies from two to four. To ensure the tasks at each stage are completed before we move to the next task, we place barriers as shown. The command barrier(j) indicates that j tasks/threads must reach the barrier before the next set of tasks can proceed.
Figure 4.7 Example of using synchronization barriers in serial–parallel algorithms. Each task is to be executed by its own thread.
The POSIX thread library specifies the barrier object along with functions to create it and creates the threads that will use it for synchronization.
To initialize the barrier, the following routine is used [42]:
1: #include <pthread.h>
2: pthread barrier t barrier;
3: pthread barrierattr t attribute;
4: unsigned count;
5: int return value;
6: return value = pthread barrier init(&barrier, &attribute, count);
Line 1 adds the functions and data types associated with the pthread library. Line 2 defines barrier to be of the type barrier.
Line 3 defines attributes to be of type barrier attributes.
Lines 4 and 5 define other data types where count is the number of threads that must arrive at the barrier before they can proceed any further.
Line 6 initializes the barrier and returns the variable return value to monitor the success of the function call. The return value is zero for successful completion.
The threads being synchronized by the barrier include the following code:
1: Code before the barrier
2:
3: // Wait at the barrier
4: ret = pthread barrier wait(&barrier);
5:
6: Code after the barrier
where the type barrier was initialized using the pthread barrier init() routine.
4.3.4 Comparing the Synchronization Primitives
The most basic synchronization primitive is the lock and is the most efficient in its memory use and execution time [42]. The lock is essentially used to serialize access to a shared resource or shared variable.
The mutex uses more memory than a lock. The mutex must be acquired before the shared variable is modified. After a thread is finished with its critical section, it must release the mutex so that other threads can proceed with their critical sections.
The barrier is used as an event synchronization mechanism so that all threads arrive at a certain point before the rest of the code is executed.
4.4 PROBLEMS
4.1. A shared-memory parallel processor system has n processors and b shared memory modules with n ≤ b. Assume all processors need to update their caches by accessing the memory modules. Assume a uniform probability that a processor requests to access data from a particular memory module.
(1) What is the value of the probability that a processor requests to access data from a particular memory module?
(2) What is the probability that a memory access collision takes place for a particular memory module?
(3) What is the probability that a memory access collision takes place for the shared memory as a whole?
(4) What is the probability that a memory access collision takes place for the shared memory as a whole for the case when n > b?
4.2. What are the two main advantages for using the local cache in shared-memory multiprocessor systems?
4.3. Explain the two reasons for maintaining cache coherence in shared-memory multiprocessor systems.
4.4. A shared-memory system consists of n processors, one shared memory module, and a system-wide bus connecting all the components. Assume a as the probability that a processor requests access to the shared memory to update its cache at a given time step. What is the probability that a bus collision takes place?
4.5. Assume in a shared memory system that the probability that a data is not in the cache is α. And 1 − α is the probability the data are in the cache. What is the average memory access time?
4.6. The three Cs for single-processor cache misses were discussed in a previous chapter. Investigate if there are other causes for cache misses in a shared memory system.
4.7. Cache misses in a shared memory system show a “U” pattern versus block size for a fixed cache capacity. Explain why this behavior is expected.