Computers only understand binary numbers. Therefore, all that you see on your computer, for example, texts, images, audio, video, and so on need to be expressed in terms of binary numbers.
This is where encoding comes into play. An encoding is a set of standard rules that assign unique numeral values to each text character.
Python 2.x default encoding is ASCII (American Standard Code for Information Interchange). The ASCII character encoding is a 7-bit encoding that can encode 2 ^7 (128) characters.
Because ASCII encoding was developed in America, it encodes characters from the English alphabet, namely, the numbers 0-9, the letters a-z and A-Z, some common punctuation symbols, some teletype machine control codes, and a blank space.
It is here that Unicode encoding comes to our rescue. The following are the key features of Unicode encoding:
- It is a way to represent text without bytes
- It provides unique code point for each character of every language
- It defines more than a million code points, representing characters of all major scripts on the earth
- Within Unicode, there are several Unicode Transformation Formats (UTF)
- UTF-8 is one of the most commonly used encodings, where 8 means that 8-bit numbers are used in the encoding
- Python also supports UTF-16 encoding, but it's less frequently used, and UTF-32 is not supported by Python 2.x
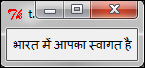
Say you want to display a Hindi character on a Tkinter Label widget. You would intuitively try to run a code like the following:
from Tkinter import * root = Tk() Label(root, text = " भारतमेंआपकास्वागतहै ").pack() root.mainloop()
If you try to run the previous code, you will get an error message as follows:
SyntaxError: Non-ASCII character 'xe0' in file 8.07.py on line 4, but no encoding declared; see http://www.Python.org/peps/pep-0263.html for details.
This means that Python 2.x, by default, cannot handle non-ASCII characters. Python standard library supports over 100 encodings, but if you are trying to use anything other than ASCII encoding you have to explicitly declare the encoding.
Fortunately, handling other encodings is very simple in Python. There are two ways in which you can deal with non-ASCII characters. They are described in the following sections:
The first way is to mark a string containing Unicode characters with the prefix u explicitly, as shown in the following code snippet (refer to 8.10 line encoding.py):
from Tkinter import * root = Tk() Label(root, text = u"भारतमेंआपकास्वागतहै").pack() root.mainloop()
When you try to run this program from IDLE, you get a warning message similar to the following one:
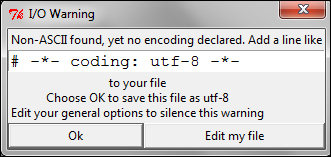
Simply click on Ok to save this file as UTF-8 and run this program to display the Unicode label.
Alternatively, you can explicitly declare the entire file to have UTF-8 encoding by including a header declaration in your source file in the following format:
# -*- coding: <encoding-name> -*-
More precisely, the header declaration must match the regular expression:
coding[:=]s*([-w.]+)
So, if you are dealing with UTF-8 characters, you will add the following header declaration in the first or second line of your Python program:
# -*- coding: utf-8 -*-
Simply by adding this header declaration, your Python program can now recognize Unicode characters. So, our code can be rewritten as (refer to 8.11 file encoding.py):
# -*- coding: utf-8 -*-
from Tkinter import *
root = Tk()
Label(root, text = "भारतमेंआपकास्वागतहै").pack()
root.mainloop()Both of the above code examples generate an interface similar to the one shown here: