
Cache-Oblivious Data Structures*
Lars Arge
University of Aarhus
Gerth Stølting Brodal
University of Aarhus
Rolf Fagerberg
University of Southern Denmark
Density Based•Exponential Tree Based
Merge Based Priority Queue: Funnel Heap•Exponential Level Based Priority Queue
35.52d Orthogonal Range Searching
Cache-Oblivious kd-Tree•Cache-Oblivious Range Tree
The memory system of most modern computers consists of a hierarchy of memory levels, with each level acting as a cache for the next; for a typical desktop computer the hierarchy consists of registers, level 1 cache, level 2 cache, level 3 cache, main memory, and disk. One of the essential characteristics of the hierarchy is that the memory levels get larger and slower the further they get from the processor, with the access time increasing most dramatically between main memory and disk. Another characteristic is that data is moved between levels in large blocks. As a consequence of this, the memory access pattern of an algorithm has a major influence on its practical running time. Unfortunately, the RAM model (Figure 35.1) traditionally used to design and analyze algorithms is not capable of capturing this, since it assumes that all memory accesses take equal time.
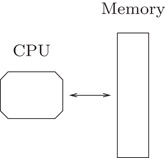
Figure 35.1The RAM model.
Because of the shortcomings of the RAM model, a number of more realistic models have been proposed in recent years. The most successful of these models is the simple two-level I/O-model introduced by Aggarwal and Vitter [1] (Figure 35.2). In this model the memory hierarchy is assumed to consist of a fast memory of size M and a slower infinite memory, and data is transfered between the levels in blocks of B consecutive elements. Computation can only be performed on data in the fast memory, and it is assumed that algorithms have complete control over transfers of blocks between the two levels. We denote such a transfer a memory transfer. The complexity measure is the number of memory transfers needed to solve a problem. The strength of the I/O model is that it captures part of the memory hierarchy, while being sufficiently simple to make design and analysis of algorithms feasible. In particular, it adequately models the situation where the memory transfers between two levels of the memory hierarchy dominate the running time, which is often the case when the size of the data exceeds the size of main memory. Agarwal and Vitter showed that comparison based sorting and searching require Θ(SortM,B(N))=Θ(NBlogM/BNB)
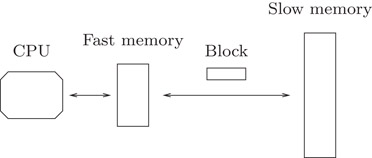
Figure 35.2The I/O model.
More elaborate models of multi-level memory than the I/O-model have been proposed (see, e.g., [3] for an overview) but these models have been less successful, mainly because of their complexity. A major shortcoming of the proposed models, including the I/O-model, have also been that they assume that the characteristics of the memory hierarchy (the level and block sizes) are known. Very recently however, the cache-oblivious model, which assumes no knowledge about the hierarchy, was introduced by Frigo et al. [4]. In essence, a cache-oblivious algorithm is an algorithm formulated in the RAM model but analyzed in the I/O model, with the analysis required to hold for any B and M. Memory transfers are assumed to be performed by an off-line optimal replacement strategy. The beauty of the cache-oblivious model is that since the I/O-model analysis holds for any block and memory size, it holds for all levels of a multi-level memory hierarchy (see [4] for details). In other words, by optimizing an algorithm to one unknown level of the memory hierarchy, it is optimized on all levels simultaneously. Thus the cache-oblivious model is effectively a way of modeling a complicated multi-level memory hierarchy using the simple two-level I/O-model.
Frigo et al. [4] described optimal Θ(SortM, B(N)) memory transfer cache-oblivious algorithms for matrix transposition, fast Fourier transform, and sorting; Prokop also described a static search tree obtaining the optimal O(logB N) transfer search bound [5]. Subsequently, Bender et al. [6] described a cache-oblivious dynamic search trees with the same search cost, and simpler and improved cache-oblivious dynamic search trees were then developed by several authors [7–10]. Cache-oblivious algorithms have also been developed for, for example, problems in computational geometry [7,11,12], for scanning dynamic sets [7], for layout of static trees [13], for partial persistence [7], and for a number of fundamental graph problems [14] using cache-oblivious priority queues [14,15]. Most of these results make the so-called tall cache assumption, that is, they assume that M > Ω(B2); we make the same assumption throughout this chapter.
Empirical investigations of the practical efficiency of cache-oblivious algorithms for sorting [16], searching [9,10,17] and matrix problems [4] have also been performed. The overall conclusion of these investigations is that cache-oblivious methods often outperform RAM algorithms, but not always as much as algorithms tuned to the specific memory hierarchy and problem size. On the other hand, cache-oblivious algorithms perform well on all levels of the memory hierarchy, and seem to be more robust to changing problem sizes than cache-aware algorithms.
In the rest of this chapter we describe some of the most fundamental and representative cache-oblivious data structure results. In Section 35.2 we discuss two fundamental primitives used to design cache-oblivious data structures. In Section 35.3 we describe two cache-oblivious dynamic search trees, and in Section 35.4 two priority queues. Finally, in Section 35.5 we discuss structures for 2-dimensional orthogonal range searching.
The most fundamental cache-oblivious primitive is scanning—scanning an array with N elements incurs Θ(NB)
Apart from algorithms and data structures that only utilize scanning, most cache-oblivious results use recursion to obtain efficiency; in almost all cases, the sizes of the recursive problems decrease double-exponentially. In this section we describe two of the most fundamental such recursive schemes, namely the van Emde Boas layout and the k-merger.
One of the most fundamental data structures in the I/O-model is the B-tree [18]. A B-tree is basically a fanout Θ(B) tree with all leaves on the same level. Since it has height O(logB N) and each node can be accessed in O(1) memory transfers, it supports searches in O(logB N) memory transfers. It also supports range queries, that is, the reporting of all K elements in a given query range, in O(logBN+KB)
35.2.1.1Layout
For simplicity, we only consider complete binary trees. A binary tree is complete if it has N = 2h − 1 nodes and height h for some integer h. The basic idea in the van Emde Boas layout of a complete binary tree T
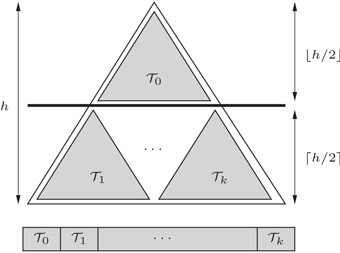
Figure 35.3The van Emde Boas layout.
35.2.1.2Search
To analyze the number of memory transfers needed to perform a search in T
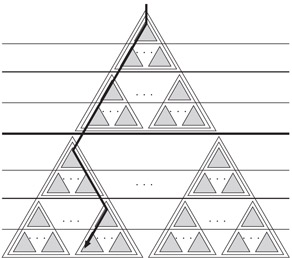
Figure 35.4A search path.
35.2.1.3Range query
To analyze the number of memory transfers needed to answer a range query [x1, x2] on T
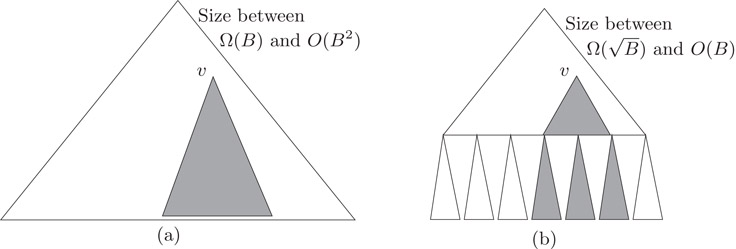
Figure 35.5Traversing tree Tv
Theorem 35.1
Let T
Note that the navigation from node to node in the van Emde Boas layout is straight-forward if the tree is implemented using pointers. However, navigation using arithmetic on array indexes is also possible [9]. This avoids the use of pointers and hence saves space.
The constant in the O(logB N) bound for searching in Theorem 35.1 can be seen to be four. Further investigations of which constants are possible for cache-oblivious comparison based searching appear in [20].
In the I/O-model the two basic optimal sorting algorithms are multi-way versions of Mergesort and distribution sorting (Quicksort) [1]. Similarly, Frigo et al. [4] showed how both merge based and distribution based optimal cache-oblivious sorting algorithms can be developed. The merging based algorithm, Funnelsort, is based on a so-called k-merger. This structure has been used as a basic building block in several cache-oblivious algorithms. Here we describe a simplified version of the k-merger due to Brodal and Fagerberg [12].
35.2.2.1Binary mergers and merge trees
A binary merger merges two sorted input streams into a sorted output stream: In one merge step an element is moved from the head of one of the input streams to the tail of the output stream; the heads of the input streams, as well as the tail of the output stream, reside in buffers of a limited capacity.
Binary mergers can be combined to form binary merge trees by letting the output buffer of one merger be the input buffer of another—in other words, a binary merge tree is a binary tree with mergers at the nodes and buffers at the edges, and it is used to merge a set of sorted input streams (at the leaves) into one sorted output stream (at the root). Refer to Figure 35.6 for an example.
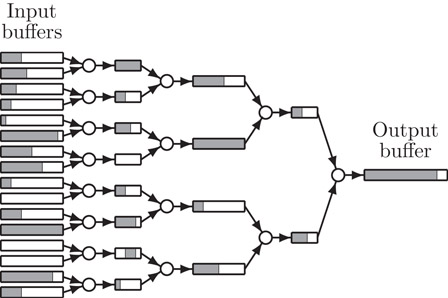
Figure 35.6A 16-merger consisting of 15 binary mergers. Shaded parts represent elements in buffers.
An invocation of a binary merger in a binary merge tree is a recursive procedure that performs merge steps until the output buffer is full (or both input streams are exhausted); if an input buffer becomes empty during the invocation (and the corresponding stream is not exhausted), the input buffer is recursively filled by an invocation of the merger having this buffer as output buffer. If both input streams of a merger get exhausted, the corresponding output stream is marked as exhausted. A procedure FILL(v) performing an invocation of a binary merger v is shown in Figure 35.7 (ignoring exhaustion issues). A single invocation FILL(r) on the root r of a merge tree will merge the streams at the leaves of the tree.

Figure 35.7Invocation of binary merger v.
35.2.2.2k-merger
A k-merger is a binary merge tree with specific buffer sizes. For simplicity, we assume that k is a power of two, in which case a k-merger is a complete binary tree of k − 1 binary mergers. The output buffer at the root has size k3, and the sizes of the rest of the buffers are defined recursively in a manner resembling the definition of the van Emde Boas layout: Let i = log k be the height of the k-merger. We define the top tree to be the subtree consisting of all mergers of depth at most ⌈i/2⌉, and the bottom trees to be the subtrees rooted in nodes at depth ⌈i/2⌉ + 1. We let the edges between the top and bottom trees have buffers of size k3/2, and define the sizes of the remaining buffers by recursion on the top and bottom trees. The input buffers at the leaves hold the input streams and are not part of the k-merger definition. The space required by a k-merger, excluding the output buffer at the root, is given by S(k) = k1/2 · k3/2 + (k1/2 + 1) · S(k1/2), which has the solution S(k) = Θ(k2).
We now analyze the number of memory transfers needed to fill the output buffer of size k3 at the root of a k-merger. In the recursive definition of the buffer sizes in the k-merger, consider the first level where the subtrees (excluding output buffers) have size less than M/3; if ˉk
We charge an element O(1/B) memory transfers each time it is inserted into a large buffer. Since ˉk=Ω(M1/4)
Theorem 35.2
Excluding the output buffers, the size of a k-merger is O(k2) and it performs O(k3BlogMk3+k)
35.2.2.3Funnelsort
The cache-oblivious sorting algorithm Funnelsort is easily obtained once the k-merger structure is defined: Funnelsort breaks the N input elements into N1/3 groups of size N2/3, sorts them recursively, and then merges the sorted groups using an N1/3-merger.
Funnelsort can be analyzed as follows: Since the space usage of a k-merger is sub-linear in its output, the elements in a recursive sort of size M/3 only need to be loaded into memory once during the entire following recursive sort. For k-mergers at the remaining higher levels in the recursion tree, we have k3 ≥ M/3 ≥ B2, which implies k2 ≥ B4/3 > B and hence k3/B > k. By Theorem 35.2, the number of memory transfers during a merge involving N′ elements is then O(logM(N′)/B) per element. Hence, the total number of memory transfers per element is
Since logM x = Θ(logM/B x) when B2 ≤ M/3, we have the following theorem.
Theorem 35.3
Funnelsort sorts N element using O(SortM, B(N)) memory transfers.
In the above analysis, the exact (tall cache) assumption on the size of the fast memory is B2 ≤ M/3. In [12] it is shown how to generalize Funnelsort such that it works under the weaker assumption B1 + ɛ ≤ M, for fixed ɛ > 0. The resulting algorithm incurs the optimal O(SortM, B(N)) memory transfers when B1 + ɛ = M, at the price of incurring O(1/ɛ · SortM, B(N)) memory transfers when B2 ≤ M. It is shown in [21] that this trade-off is the best possible for comparison based cache-oblivious sorting.
The van Emde Boas layout of a binary tree provides a static cache-oblivious version of B-trees. The first dynamic solution was given Bender et al. [6], and later several simplified structures were developed [7–10]. In this section, we describe two of these structures [7,9].
In this section we describe the dynamic cache-oblivious search tree structure of Brodal et al. [9]. A similar proposal was given independently by Bender et al. [8].
The basic idea in the structure is to embed a dynamic binary tree of height log N + O(1) into a static complete binary tree, that is, in a tree with 2h − 1 nodes and height h, which in turn is embedded into an array using the van Emde Boas layout. Refer to Figure 35.8.
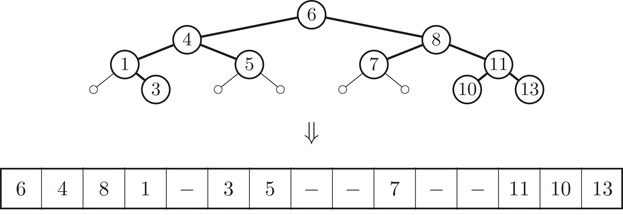
Figure 35.8Illustration of embedding a height H tree into a complete static tree of height H, and the van Emde Boas layout of this tree.
To maintain the dynamic tree we use techniques for maintaining small height in a binary tree developed by Andersson and Lai [22]; in a different setting, similar techniques has also been given by Itai et al. [23]. These techniques give an algorithm for maintaining height log N + O(1) using amortized O(log2N) time per update. If the height bound is violated after performing an update in a leaf l, this algorithm performs rebalancing by rebuilding the subtree rooted at a specific node v on the search path from the root to l. The subtree is rebuilt to perfect balance in time linear in the size of the subtree. In a binary tree of perfect balance the element in any node v is the median of all the elements stored in the subtree Tv
35.3.1.1Structure
As mentioned, the data structure consists of a dynamic binary tree T
In order to present the update and query algorithms, we define the density ρ(u) of a node u as |Tu|/|T′u|, where |Tu| and |T′u| are the number of nodes in the trees rooted in u in T
35.3.1.2Updates
To insert a new element into the structure we first locate the position in T
We can delete an element from the structure in a similar way: We first locate the node w in T
Similar to the proof of Andersson and Lai [22] and Itai et al. [23] that updates are performed in O(log2N) time, Brodal et al. [9] showed that using the above algorithms, updates can be performed in amortized O(logB N + (log2N)/B) memory transfers.
35.3.1.3Range queries
In Section 35.2, we discussed how a range query can be answered in O(logBN+KB)
Theorem 35.4
There exists a linear size cache-oblivious data structure for storing N elements, such that updates can be performed in amortized O(logB N + (log2N)/B) memory transfers and range queries in O(logBN+KB)
Using the method for moving between nodes in a van Emde Boas layout using arithmetic on the node indices rather than pointers, the above data structure can be implemented as a single size O(N) array of data elements. The amortized complexity of updates can also be lowered to O(logB N) by changing leaves into pointers to buckets containing Θ(log N) elements each. With this modification a search can still be performed in O(logB N) memory transfers. However, then range queries cannot be answered efficiently, since the O(KlogN)
The second dynamic cache-oblivious search tree we consider is based on the so-called exponential layout of Bender et al. [7]. For simplicity, we here describe the structure slightly differently than in [7].
35.3.2.1Structure
Consider a complete balanced binary tree T
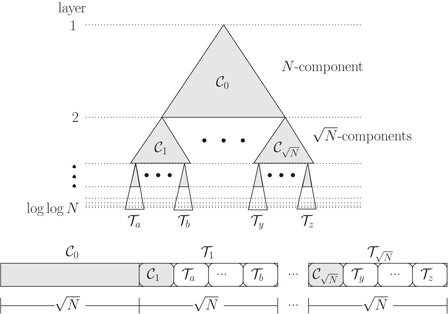
Figure 35.9Components and exponential layout.
By slightly relaxing the requirements on the layout described above, we are able to maintain it dynamically: We define an exponential layout of a balanced binary tree T
35.3.2.2Search
Even with the modified definition of the exponential layout, we can traverse any root-to-leaf path in T
35.3.2.3Updates
To perform an insertion in T
Deletions can easily be handled in O(logB N) memory transfers using global rebuilding: To delete the element in a leaf l of T
Bender et al. [7] showed how to modify the update algorithms to perform updates “lazily” and obtain worst case O(logB N) bounds.
35.3.2.4Reducing space usage
To reduce the space of the layout of a tree T
Theorem 35.5
The exponential layout of a search tree T
Note that the analogue of Theorem 35.1 does not hold for the exponential layout, that is, it does not support efficient range queries. The reason is partly that the √X
A priority queue maintains a set of elements with a priority (or key) each under the operations INSERT and DELETEMIN, where an INSERT operation inserts a new element in the queue, and a DELETEMIN operation finds and deletes the element with the minimum key in the queue. Frequently we also consider a DELETE operation, which deletes an element with a given key from the priority queue. This operation can easily be supported using INSERT and DELETEMIN: To perform a DELETE we insert a special delete-element in the queue with the relevant key, such that we can detect if an element returned by a DELETEMIN has really been deleted by performing another DELETEMIN.
A balanced search tree can be used to implement a priority queue. Thus the existence of a dynamic cache-oblivious B-tree immediately implies the existence of a cache-oblivious priority queue where all operations can be performed in O(logB N) memory transfers, where N is the total number of elements inserted. However, it turns out that one can design a priority queue where all operations can be performed in Θ(SortM,B(N)/N)=O(1BlogM/BNB)
35.4.1Merge Based Priority Queue: Funnel Heap
The cache-oblivious priority queue Funnel Heap due to Brodal and Fagerberg [15] is inspired by the sorting algorithm Funnelsort [4,12]. The structure only uses binary merging; essentially it is a heap-ordered binary tree with mergers in the nodes and buffers on the edges.
35.4.1.1Structure
The main part of the Funnel Heap structure is a sequence of k-mergers (Section 35.2.2) with double-exponentially increasing k, linked together in a list using binary mergers; refer to Figure 35.10. This part of the structure constitutes a single binary merge tree. Additionally, there is a single insertion buffer I.
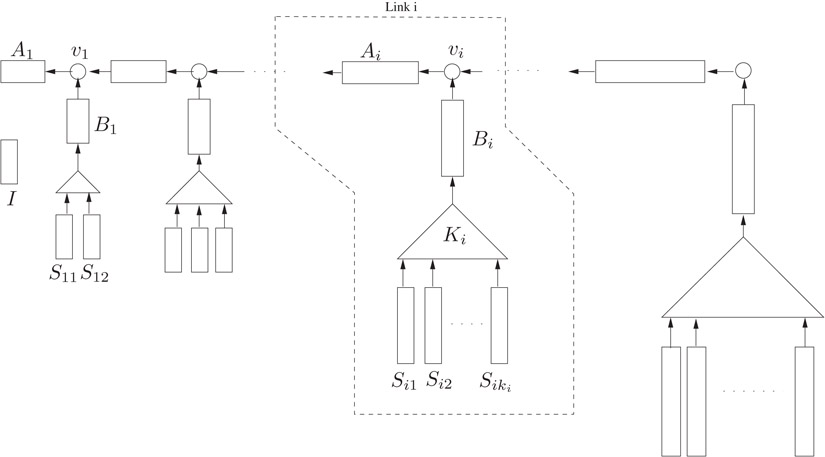
Figure 35.10Funnel Heap: Sequence of k-mergers (triangles) linked together using buffers (rectangles) and binary mergers (circles).
More precisely, let ki and si be values defined inductively by
(k1,s1)=(2,8),si+1=si(ki+1),ki+1=⌈⌈si+11/3⌉⌉, |
(35.1) |
|---|
where ⌈⌈x⌉⌉ denotes the smallest power of two above x, that is, ⌈⌈x⌉⌉ = 2⌈ log x⌉. We note that si1/3 ≤ ki < 2si1/3, from which si4/3 < si + 1 < 3si4/3 follows, so both si and ki grow double-exponentially: si+1=Θ(s4/3i)
A Funnel Heap consists of a linked list with link i containing a binary merger vi, two buffers Ai and Bi, and a ki-merger Ki having ki input buffers Si1,…, Siki. We refer to Bi, Ki, and Si1,…, Siki as the lower part of the link. The size of both Ai and Bi is k3i
Invariant 35.1
For link i, Sici,…, Siki are empty.
Invariant 35.2
On any path in the merge tree from some buffer to the root buffer A1, elements appear in decreasing order.
Invariant 35.3
Elements in buffer I appear in sorted order.
Invariant 35.2 can be rephrased as the entire merge tree being in heap order. It implies that in all buffers in the merge tree, the elements appear in sorted order, and that the minimum element in the queue will be in A1 or I, if buffer A1 is non-empty. Note that an invocation (Figure 35.7) of any binary merger in the tree maintains the invariants.
35.4.1.2Layout
The Funnel Heap is laid out in consecutive memory locations in the order I, link 1, link 2,…, with link i being laid out in the order ci, Ai, vi, Bi, Ki, Si1, Si2,…, Siki.
35.4.1.3Operations
To perform a DELETEMIN operation we compare the smallest element in I with the smallest element in A1 and remove the smallest of these; if A1 is empty we first perform an invocation of v1. The correctness of this procedure follows immediately from Invariant 35.2.
To perform an INSERT operation we insert the new element among the (constant number of) elements in I, maintaining Invariant 35.3. If the number of elements in I is now s1, we examine the links in order to find the lowest index i for which ci ≤ ki. Then we perform the following SWEEP(i) operation.
In SWEEP(i), we first traverse the path p from A1 to Sici and record how many elements are contained in each encountered buffer. Then we traverse the part of p going from Ai to Sici, remove the elements in the encountered buffers, and form a sorted stream σ1 of the removed elements. Next we form another sorted stream σ2 of all elements in links 1,…, i − 1 and in buffer I; we do so by marking Ai temporarily as exhausted and calling DELETEMIN repeatedly. We then merge σ1 and σ2 into a single stream σ, and traverse p again while inserting the front (smallest) elements of σ in the buffers on p such that they contain the same numbers of elements as before we emptied them. Finally, we insert the remaining elements from σ into Sici, reset cl to one for l = 1,2,…, i − 1, and increment ci.
To see that SWEEP(i) does not insert more than the allowed si elements into Sici, first note that the lower part of link i is emptied each time ci is reset to one. This implies that the lower part of link i never contains more than the number of elements inserted into Si1, Si2,…, Siki by the at most ki SWEEP(i) operations occurring since last time ci was reset. Since si=s1+∑i−1j=1kjsj
Clearly, SWEEP(i) maintains Invariants 35.1 and 35.3, since I and the lower parts of links 1,…, i − 1 are empty afterwards. Invariant 35.2 is also maintained, since the new elements in the buffers on p are the smallest elements in σ, distributed such that each buffer contains exactly the same number of elements as before the SWEEP(i) operation. After the operation, an element on this path can only be smaller than the element occupying the same location before the operation, and therefore the merge tree is in heap order.
35.4.1.4Analysis
To analyze the amortized cost of an INSERT or DELETEMIN operation, we first consider the number of memory transfers used to move elements upwards (towards A1) by invocations of binary mergers in the merge tree. For now we assume that all invocations result in full buffers, that is, that no exhaustions occur. We imagine charging the cost of filling a particular buffer evenly to the elements being brought into the buffer, and will show that this way an element from an input buffer of Ki is charged O(1BlogM/Bsi)
Our proof rely on the optimal replacement strategy keeping as many as possible of the first links of the Funnel Heap in fast memory at all times. To analyze the number of links that fit in fast memory, we define Δi to be the sum of the space used by links 1 to i and define iM to be the largest i for which Δi ≤ M. By the space bound for k-mergers in Theorem 35.2 we see that the space used by link i is dominated by the Θ(si ki) = Θ(ki4) space use of Si1,…, Siki. Since ki+1=Θ(k4/3i)
Now consider an element in an input buffer of Ki. If i ≤ iM the element will not get charged at all in our charging scheme, since no memory transfers are used to fill buffers in the links that fit in fast memory. So assume i > iM. In that case the element will get charged for the ascent through Ki to Bi and then through vj to Aj for j = i, i − 1,…, iM. First consider the cost of ascending through Ki: By Theorem 35.2, an invocation of the root of Ki to fill Bi with k3i
We imagine maintaining the credit invariant that each element in a buffer holds enough credits to be able to pay for the ascent from its current position to A1, at the cost analyzed above. In particular, an element needs O(1BlogM/Bsi)
A SWEEP(i) operation also incurs memory transfers by itself; we now bound these. In the SWEEP(i) operation we first form σ1 by traversing the path p from A1 to Sici. Since the links are laid out sequentially in memory, this traversal at most constitutes a linear scan of the consecutive memory locations containing A1 through Ki. Such a scan takes O((Δi − 1 + |Ai| + |Bi| + |Ki|)/B) = O(ki3/B) = O(si/B) memory transfers. Next we form σ2 using DELETEMIN operations; the cost of which is paid for by the credits placed on the elements. Finally, we merge of σ1 and σ2 into σ, and place some of the elements in buffers on p and some of the elements in Sici. The number of memory transfers needed for this is bounded by the O(si/B) memory transfers needed to traverse p and Sici. Hence, the memory transfers incurred by the SWEEP(i) operation itself is O(si/B).
After the SWEEP(i) operation, the credit invariant must be reestablished. Each of the O(si) elements inserted into Sici must receive O(1BlogM/Bsi)
To actually account for exhaustions, that is, the memory transfers incurred when filling buffers that become exhausted, we note that filling a buffer partly incurs at most the same number of memory transfers as filling it entirely. This number was analyzed above to be O(|Ai|/B) for Ai and O(|Bi|BlogM/Bsi)
Overall we have shown that we can account for all memory transfers if we attribute O(siBlogM/Bsi)
where the last equality follows from the tall cache assumption M = Ω(B2).
Finally, we bound the space use of the entire structure. To ensure a space usage linear in N, we create a link i when it is first used, that is, when the first SWEEP(i) occurs. At that point in time, ci, Ai, vi, Bi, Ki, and Si1 are created. These take up Θ(si) space combined. At each subsequent SWEEP(i) operation, we create the next input buffer Sici of size si. As noted above, each SWEEP(i) is preceded by at least si insertions, from which an O(N) space bound follows. To ensure that the entire structure is laid out in consecutive memory locations, the structure is moved to a larger memory area when it has grown by a constant factor. When allocated, the size of the new memory area is chosen such that it will hold the input buffers Sij that will be created before the next move. The amortized cost of this is O(1/B) per insertion.
Theorem 35.6
Using Θ(M) fast memory, a sequence of N INSERT, DELETEMIN, and DELETE operations can be performed on an initially empty Funnel Heap using O(N) space in O(1BlogM/BNB)
Brodal and Fagerberg [15] gave a refined analysis for a variant of the Funnel Heap that shows that the structure adapts to different usage profiles. More precisely, they showed that the ith insertion uses amortized O(1BlogM/BNiB)
35.4.2Exponential Level Based Priority Queue
While the Funnel Heap is inspired by Mergesort and uses k-mergers as the basic building block, the exponential level priority queue of Arge et al. [14] is somewhat inspired by distribution sorting and uses sorting as a basic building block.
35.4.2.1Structure
The structure consists of Θ(log log N) levels whose sizes vary from N to some small size c below a constant threshold ct; the size of a level corresponds (asymptotically) to the number of elements that can be stored within it. The i’th level from above has size N(2/3)i − 1 and for convenience we refer to the levels by their size. Thus the levels from largest to smallest are level N, level N2/3, level N4/9,…, level X9/4, level X3/2, level X, level X2/3, level X4/9,…, level c9/4, level c3/2, and level c. In general, a level can contain any number of elements less than or equal to its size, except level N, which always contains Θ(N) elements. Intuitively, smaller levels store elements with smaller keys or elements that were more recently inserted. In particular, the minimum key element and the most recently inserted element are always in the smallest (lowest) level c. Both insertions and deletions are initially performed on the smallest level and may propagate up through the levels.
Elements are stored in a level in a number of buffers, which are also used to transfer elements between levels. Level X consists of one up buffer uX that can store up to X elements, and at most X1/3 down buffers dX1,…,dXX1/3
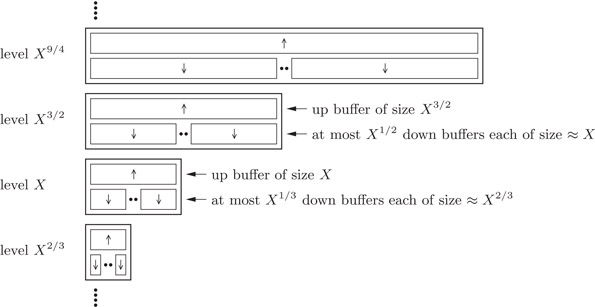
Figure 35.11Levels X2/3, X, X3/2, and X9/4 of the priority queue data structure.
We maintain three invariants about the relationships between the elements in buffers of various levels:
Invariant 35.4
At level X, elements are sorted among the down buffers, that is, elements in dXi
The element with largest key in each down buffer dXi
Invariant 35.5
At level X, the elements in the down buffers have smaller keys than the elements in the up buffer.
Invariant 35.6
The elements in the down buffers at level X have smaller keys than the elements in the down buffers at the next higher level X3/2.
The three invariants ensure that the keys of the elements in the down buffers get larger as we go from smaller to larger levels of the structure. Furthermore, an order exists between the buffers on one level: keys of elements in the up buffer are larger than keys of elements in down buffers. Therefore, down buffers are drawn below up buffers on Figure 35.11. However, the keys of the elements in an up buffer are unordered relative to the keys of the elements in down buffers one level up. Intuitively, up buffers store elements that are “on their way up,” that is, they have yet to be resolved as belonging to a particular down buffer in the next (or higher) level. Analogously, down buffers store elements that are “on their way down”—these elements are by the down buffers partitioned into several clusters so that we can quickly find the cluster of smallest key elements of size roughly equal to the next level down. In particular, the element with overall smallest key is in the first down buffer at level c.
35.4.2.2Layout
The priority queue is laid out in memory such that the levels are stored consecutively from smallest to largest with each level occupying a single region of memory. For level X we reserve space for exactly 3X elements: X for the up buffer and 2X2/3 for each possible down buffer. The up buffer is stored first, followed by the down buffers stored in an arbitrary order but linked together to form an ordered linked list. Thus O(∑log3/2logcNi=0N(2/3)i)=O(N)
35.4.2.3Operations
To implement the priority queue operations we use two general operations, push and pull. Push inserts X elements into level X3/2, and pull removes the X elements with smallest keys from level X3/2 and returns them in sorted order. An INSERT or a DELETEMIN is performed simply by performing a push or pull on the smallest level c.
Push. To push X elements into level X3/2, we first sort the X elements cache-obliviously using O(1+XBlogM/BXB)![]() as soon as we encounter an element with larger key than the pivot of
as soon as we encounter an element with larger key than the pivot of ![]() . Elements with larger keys than the pivot of the last down buffer are inserted in the up buffer uX3/2. Scanning through the X elements take O(1+XB)
. Elements with larger keys than the pivot of the last down buffer are inserted in the up buffer uX3/2. Scanning through the X elements take O(1+XB)
During the distribution of elements a down buffer may run full, that is, contain 2X elements. In this case, we split the buffer into two down buffers each containing X elements using O(1+XB)
If the up buffer runs full during the above process, that is, contains more than X3/2 elements, we recursively push all of these elements into the next level up. Note that after such a recursive push, X3/2 elements have to be inserted (pushed) into the up buffer of level X3/2 before another recursive push is needed.
Overall we can perform a push of X elements from level X into level X3/2 in O(X1/2+XBlogM/BXB)
Pull. To describe how to pull the X smallest keys elements from level X3/2, we first assume that the down buffers contain at least 32X![]() ,
, ![]() , and
, and ![]() contain the between 32X
contain the between 32X
In the case where the down buffers contain fewer than 32X
35.4.2.4Analysis
To analyze the amortized cost of an INSERT or DELETEMIN operation, we consider the total number of memory transfers used to perform push and pull operations during N2
The total cost of N2
Above we argued that a push or pull charged to level X uses O(X1/2+XBlogM/BXB)
Finally, since each of the O(N/X) push and pull operations charged to level X (X > B2) uses O(XBlogM/BXB)
Theorem 35.7
Using Θ(M) fast memory, N INSERT, DELETEMIN, and DELETE operations can be performed on an initially empty exponential level priority queue using O(N) space in O(1BlogM/BNB)
35.52d Orthogonal Range Searching
As discussed in Section 35.3, there exist cache-oblivious B-trees that support updates and queries in O(logB N) memory transfers (e.g., Theorem 35.5); several cache-oblivious B-tree variants can also support (one-dimensional) range queries in O(logBN+KB)
In this section we discuss cache-oblivious data structures for two-dimensional orthogonal range searching, that is, structures for storing a set of N points in the plane such that the points in a axis-parallel query rectangle can be reported efficiently. In Section 35.5.1 we first discuss a cache-oblivious version of a kd-tree. This structure uses linear space and answers queries in O(√N/B+KB)
35.5.1.1Structure
The cache-oblivious kd-tree is simply a normal kd-tree laid out in memory using the van Emde Boas layout. This structure, proposed by Bentley [25], is a binary tree of height O(log N) with the N points stored in the leaves of the tree. The internal nodes represent a recursive decomposition of the plane by means of axis-orthogonal lines that partition the set of points into two subsets of equal size. On even levels of the tree the dividing lines are horizontal, and on odd levels they are vertical. In this way a rectangular region Rv is naturally associated with each node v, and the nodes on any particular level of the tree partition the plane into disjoint regions. In particular, the regions associated with the leaves represent a partition of the plane into rectangular regions containing one point each. Refer to Figure 35.12.
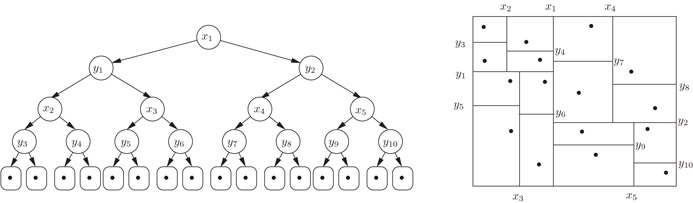
Figure 35.12kd-tree and the corresponding partitioning.
35.5.1.2Query
An orthogonal range query Q on a kd-tree T
If the kd-tree T
35.5.1.3Construction
In the RAM model, a kd-tree on N points can be constructed recursively in O(N log N) time; the root dividing line is found using an O(N) time median algorithm, the points are distributed into two sets according to this line in O(N) time, and the two subtrees are constructed recursively. Since median finding and distribution can be performed cache-obliviously in O(N/B) memory transfers [4,5], a cache-oblivious kd-tree can be constructed in O(NBlogN)
35.5.1.4Updates
In the RAM model a kd-tree T
Deletes in a cache-oblivious kd-tree is basically done as in the RAM version. However, to still be able to load a subtree Tv
Theorem 35.8
There exists a cache-oblivious (kd-tree) data structure for storing a set of N points in the plane using linear space, such that an orthogonal range query can be answered in O(√N/B+KB)
35.5.2Cache-Oblivious Range Tree
The main part of the cache-oblivious range tree structure for answering (four-sided) orthogonal range queries is a structure for answering three-sided queries Q = [xl, xr] × [yb,∞), that is, for finding all points with x-coordinates in the interval [xl, xr] and y-coordinates above yb. Below we discuss the two structures separately.
35.5.2.1Three-Sided Queries
35.5.2.1.1Structure
Consider dividing the plane into √N
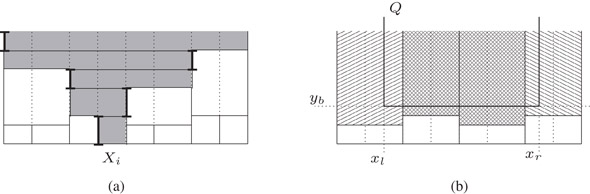
Figure 35.13(a) Active intervals of buckets spanning slab Xi; (b) Buckets active at yb.
After defining the 2√N−1
35.5.2.1.2Layout
The layout of the structure in memory consists of O(N) memory locations containing T
35.5.2.1.3Query
To answer a three-sided query Q, we consider the buckets whose active y-interval contain yb. These buckets are non-overlapping and together they contain all points in Q, since they span all slabs and have bottom y-boundary below yb. We report all points that satisfy Q in each of the buckets with x-range completely between xl and xr. At most two other buckets bl and br—the ones containing xl and xr—can contain points in Q, and we find these points recursively by advancing the query to Sl
We find the buckets bl and br that need to be queried recursively and report the points in the completely spanned buckets as follows. We first query T
Theorem 35.9
There exists a cache-oblivious data structure for storing N points in the plane using O(N log N) space, such that a three-sided orthogonal range query can be answered in O(logBN+KB)
35.5.2.2Four-sided queries
Using the structure for three-sided queries, we can construct a cache-oblivious range tree structure for four-sided orthogonal range queries in a standard way. The structure consists of a cache-oblivious B-tree T
To answer an orthogonal range query Q, we search down T
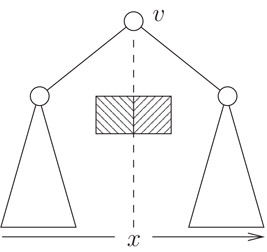
Figure 35.14Answering a four-sided query in v using two three-sided queries in v’s children.
Theorem 35.10
There exists a cache-oblivious data structure for storing N points in the plane using O(N log2N) space, such that an orthogonal range query can be answered in O(logBN+KB)
Lars Arge was supported in part by the National Science Foundation through ITR grant EIA–0112849, RI grant EIA–9972879, CAREER grant CCR–9984099, and U.S.–Germany Cooperative Research Program grant INT–0129182.
Gerth Stølting Brodal was supported by the Carlsberg Foundation (contract number ANS-0257/20), BRICS (Basic Research in Computer Science, www.brics.dk, funded by the Danish National Research Foundation), and the Future and Emerging Technologies programme of the EU under contract number IST-1999-14186 (ALCOM-FT).
Rolf Fagerberg was supported by BRICS (Basic Research in Computer Science, www.brics.dk, funded by the Danish National Research Foundation), and the Future and Emerging Technologies programme of the EU under contract number IST-1999-14186 (ALCOM-FT). Part of this work was done while at University of Aarhus.
1.A. Aggarwal and J. S. Vitter. The input/output complexity of sorting and related problems. Communications of the ACM, 31(9):1116–1127, Sept. 1988.
2.L. Arge. External memory data structures. In J. Abello, P. M. Pardalos, and M. G. C. Resende, editors, Handbook of Massive Data Sets, pages 313–358. Kluwer Academic Publishers, 2002.
3.J. S. Vitter. External memory algorithms and data structures: Dealing with massive data. ACM Computing Surveys, 33(2):209–271, June 2001.
4.M. Frigo, C. E. Leiserson, H. Prokop, and S. Ramachandran. Cache-oblivious algorithms. In Proc. 40th Annual IEEE Symposium on Foundations of Computer Science, pages 285–298. IEEE Computer Society Press, 1999.
5.H. Prokop. Cache-oblivious algorithms. Master’s thesis, Massachusetts Institute of Technology, Cambridge, MA, June 1999.
6.M. A. Bender, E. D. Demaine, and M. Farach-Colton. Cache-oblivious B-trees. In Proc. 41st Annual IEEE Symposium on Foundations of Computer Science, pages 339–409. IEEE Computer Society Press, 2000.
7.M. A. Bender, R. Cole, and R. Raman. Exponential structures for cache-oblivious algorithms. In Proc. 29th International Colloquium on Automata, Languages, and Programming, volume 2380 of Lecture Notes in Computer Science, pages 195–207. Springer, 2002.
8.M. A. Bender, Z. Duan, J. Iacono, and J. Wu. A locality-preserving cache-oblivious dynamic dictionary. In Proc. 13th Annual ACM-SIAM Symposium on Discrete Algorithms, pages 29–38. SIAM, 2002.
9.G. S. Brodal, R. Fagerberg, and R. Jacob. Cache oblivious search trees via binary trees of small height. In Proc. 13th Annual ACM-SIAM Symposium on Discrete Algorithms, pages 39–48. SIAM, 2002.
10.N. Rahman, R. Cole, and R. Raman. Optimized predecessor data structures for internal memory. In Proc. 3rd Workshop on Algorithm Engineering, volume 2141 of Lecture Notes in Computer Science, pages 67–78. Springer, 2001.
11.P. K. Agarwal, L. Arge, A. Danner, and B. Holland-Minkley. Cache-oblivious data structures for orthogonal range searching. In Proc. 19th ACM Symposium on Computational Geometry, pages 237–245. ACM Press, 2003.
12.G. S. Brodal and R. Fagerberg. Cache oblivious distribution sweeping. In Proc. 29th International Colloquium on Automata, Languages, and Programming, volume 2380 of Lecture Notes in Computer Science, pages 426–438. Springer, 2002.
13.M. Bender, E. Demaine, and M. Farach-Colton. Efficient tree layout in a multilevel memory hierarchy. In Proc. 10th Annual European Symposium on Algorithms, volume 2461 of Lecture Notes in Computer Science, pages 165–173. Springer, 2002. Full version at http://www.cs.sunysb.edu/bender/pub/treelayout-full.ps.
14.L. Arge, M. Bender, E. Demaine, B. Holland-Minkley, and J. I. Munro. Cache-oblivious priority-queue and graph algorithms. In Proc. 34th ACM Symposium on Theory of Computation, pages 268–276. ACM Press, 2002.
15.G. S. Brodal and R. Fagerberg. Funnel heap - a cache oblivious priority queue. In Proc. 13th International Symposium on Algorithms and Computation, volume 2518 of Lecture Notes in Computer Science, pages 219–228. Springer, 2002.
16.G. S. Brodal, R. Fagerberg, and K. Vinther. Engineering a cache-oblivious sorting algorithm. In Proc. 6th Workshop on Algorithm Engineering and Experiments, 2004.
17.R. E. Ladner, R. Fortna, and B.-H. Nguyen. A comparison of cache aware and cache oblivious static search trees using program instrumentation. In Experimental Algorithmics, From Algorithm Design to Robust and Efficient Software (Dagstuhl seminar, September 2000), volume 2547 of Lecture Notes in Computer Science, pages 78–92. Springer, 2002.
18.R. Bayer and E. McCreight. Organization and maintenance of large ordered indexes. Acta Informatica, 1:173–189, 1972.
19.P. van Emde Boas. Preserving order in a forest in less than logarithmic time and linear space. Information Processing Letters, 6:80–82, 1977.
20.M. A. Bender, G. S. Brodal, R. Fagerberg, D. Ge, S. He, H. Hu, J. Iacono, and A. López-Ortiz. The cost of cache-oblivious searching. In Proc. 44th Annual IEEE Symposium on Foundations of Computer Science, pages 271–282. IEEE Computer Society Press, 2003.
21.G. S. Brodal and R. Fagerberg. On the limits of cache-obliviousness. In Proc. 35th ACM Symposium on Theory of Computation, pages 307–315. ACM Press, 2003.
22.A. Andersson and T. W. Lai. Fast updating of well-balanced trees. In Proc. 2nd Scandinavian Workshop on Algorithm Theory, volume 447 of Lecture Notes in Computer Science, pages 111–121. Springer, 1990.
23.A. Itai, A. G. Konheim, and M. Rodeh. A sparse table implementation of priority queues. In Proc. 8th International Colloquium on Automata, Languages, and Programming, volume 115 of Lecture Notes in Computer Science, pages 417–431. Springer, 1981.
24.K. V. R. Kanth and A. K. Singh. Optimal dynamic range searching in non-replicating index structures. In Proc. International Conference on Database Theory, volume 1540 of Lecture Notes in Computer Science, pages 257–276. Springer, 1999.
25.J. L. Bentley. Multidimensional binary search trees used for associative searching. Communication of the ACM, 18:509–517, 1975.
26.J. L. Bentley. Decomposable searching problems. Information Processing Letters, 8(5):244–251, 1979.
27.L. Arge, G. S. Brodal, and R. Fagerberg. Improved cache-oblivious two-dimensional orthogonal range searching. Unpublished results, 2004.
*This chapter has been reprinted from first edition of this Handbook, without any content updates.