
CHAPTER 7
Databases, Data Warehousing, Data Mining, and Cloud Computing for Healthcare
Alex Mu-Hsing Kuo
In this chapter, you will learn how to
• Explain what a database is and why it is important in healthcare information technology
• Explain what data warehousing and data mining are
• Develop and manage a web-based database application, a data warehouse system, or a data mining project
• Identify how cloud computing can be used for large-scale database management purposes
• Identify and explain issues for developing database applications, data warehouse systems, clouds, or data mining projects in healthcare
Healthcare Databases
Healthcare is the most data-intensive industry in the world.1, 2 Patient information stored in health information technology (HIT), including electronic health records (EHRs), can be used by healthcare professionals for patient care, for treatment advice, and for surveillance of a patient’s health status; it can be used by healthcare researchers in assessing clinical treatment, procedures, and effectiveness of medications; and it can be used by administrative personnel in cost accounting and by managers for planning. The challenge for a traditional HIT is how to make data useful for clinicians and empower them with the tools to make informed decisions and deliver more responsive patient services.
A healthcare database is a collection of related patient health data organized to facilitate its efficient storage, querying, and modification to meet the healthcare professional’s needs.3 Nowadays, many healthcare environments have applied database technologies to improve work efficiency and reduce healthcare costs. The following are some important database application areas in healthcare:3, 4
• Solo practice General practitioners (GPs) find that most of their needs for HIT are focused on patient data management, schedule keeping, and billing. The data management functions of modern databases allow GPs to easily maintain and retrieve patient health information and reduce paperwork as well as documentation errors.
• Group practice The operation of a group practice where several healthcare professionals cooperate in providing care creates many problems regarding access to medical records. Data for the record are generated at multiple sites, but the entire record should be complete and legible whenever and wherever it is retrieved. Databases that store large volumes of data over long periods of time from patients (and from other clinical sources) provide support to healthcare teams for accessing and analyzing patient data during the process of providing patient care.
• Clinical research Databases are usually involved in the study of medications, devices, diagnostic products, or treatment regimens (including information about the safety and effectiveness of drugs intended for human use). The data in these databases may be used to inform decision making for the prevention, treatment, and diagnosis of disease. When studies become moderate to large in terms of their populations and observation period, a database approach becomes essential.
• Service reimbursement Perhaps the largest databases in use that are related to healthcare are those associated with reimbursement for health services. Requirements for inquiry and audit are generating the need for more complete medical encounter information. This leads the healthcare providers who handle reimbursement accounting to consider database technologies.
• Health surveillance This refers to the collection and analysis of health data about clinical syndromes that have a significant impact on public health. Data from databases can be used to detect or anticipate disease outbreaks. Then, governments can drive decisions about health policy and health education. Surveillance databases serve an important role as collections of disease reports as well as patient behavior.
• Healthcare education Databases are also used for healthcare education. Such databases contain medical student and laboratory data so that students can receive appropriate assignments, be matched to the patient population, and have their progress tracked.
• Electronic health records (EHRs) Databases are at the core of EHRs, which are designed to allow users (e.g., physicians, nurses, and other health professionals) to store and retrieve patient data electronically. Data available to users in the EHR are stored in and retrieved from databases.
Database Basics
Before database systems were developed, data were stored in traditional electronic files. Traditional file-processing systems have several drawbacks such as program-data dependency, duplication of data, limited data sharing, lengthy development times, and excessive program maintenance.1 Database technologies have evolved since the 1960s to ease increasing difficulties in maintaining complex traditional information systems with a large amount of diverse data and with many concurrent end users. Over the past few decades, there has been an increase in the number of database applications in business, industry, healthcare, education, government, and the military.
A database model (database schema) is the structure or format of a database, described in a formal language supported by the database management system (DBMS). Within the database model, the data dictionary provides a description of all data elements stored in a database, including the names of data, data types, display format, internal storage format, and validation rules. The data dictionary itself can therefore be considered “data about data” or metadata. Several different database models have been used in DBMSs: the hierarchical model, the network model, the relational model, and the object-oriented model have been proposed since the concept of a DBMS was first created.1 Among them, the relational database model is the most commonly adopted model today and is widely used in the healthcare industry. Thus the remainder of this chapter will focus on the relational database model.
The relational database model is a collection of relations that refer to the various tables in the database. The table is the basic data structure of the relational model. A table includes three components:
• Name Used to uniquely identify a table
• Column (also called attribute/field) A set of data values with particular data types (e.g., CHAR, NUMBER, DATE, etc.)
• Row (also called instance/tuple/record) A set of related data, in which every row has the same structure
In a table, the primary key (PK) is a column (or combination of columns) that is used to uniquely identify a record in a table (e.g., an employee number in an employee database). The foreign key (FK) identifies a column in one table that refers to a column (usually a PK) in another table. For example, in Figure 7-1, the table’s name is EMPLOYEES and it has many columns and rows (this is a database table for a hospital employee database). The first three columns record, respectively, the employee’s ID (EMPLOYEE_ID), first name (FIRST_NAME), and last name (LAST_NAME), and the subsequent columns record other important details about the employee. For example, in Figure 7-1, reading across the rows from the top down, you can see that the first employee has the EMPLOYEE_ID of 100, has the FIRST_NAME Steven, and has the LAST_NAME King. The second row describes the information for EMPLOYEE_ID 101. The columns represent the fields (or attributes) of each employee record. A healthcare database consists of data stored in many such tables (that are linked together through foreign keys).
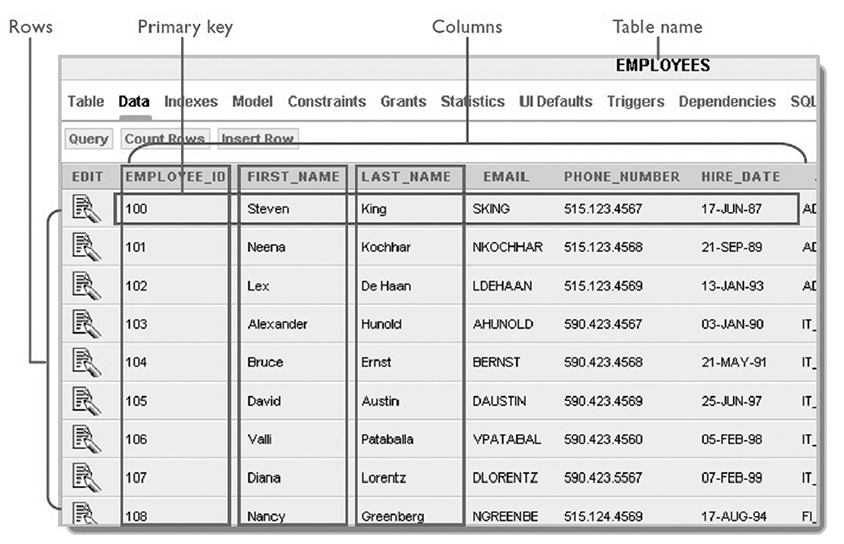
Figure 7-1 A relational database table structure
A relational database management system (RDBMS) is a set of software programs that control the organization, storage, management, and retrieval of data in a database. Structured Query Language (SQL) is a nonprocedural programming language that enables a user to manage a (relational) database. Using SQL statements, the user can query tables to display data, create objects, modify objects, and perform administrative tasks. SQL statements are divided into three categories:
• Data Definition Language (DDL) statements These statements create, alter, and drop database objects.
• Data Manipulation Language (DML) statements These statements query, insert, update, and delete data in tables.
• Data Control Language (DCL) statements These statements commit or roll back the processing of transactions.
For example, the following DML statement retrieves all employee_id, first_name, last_name, job_id, and salary data from the EMPLOYEES table in Figure 7-1:
SELECT employee_id, first_name, last_name, job_id, salary FROM Employees;
Database Application Development Process
A healthcare database application design process usually includes four stages (Figure 7-2):

Figure 7-2 A generic database application design process
• Stage 1 Analyze the business scenario and extract business rules.
• Stage 2 Design an entity relationship diagram (ERD) based on the business rules extracted from stage 1.
• Stage 3 Select a database model (e.g., Oracle DB) and create a physical database (tables, views, functions, etc).
• Stage 4 Choose a development tool (e.g., Oracle APEX) to implement the application.
Analyzing the Business Scenario and Extracting Business Rules
Business rules describe the operations, definitions, and constraints that are intended to embody the business structure or to control or influence the behavior of an organization. Many database system developers believe that clear business rules are very important in database modeling because they govern how data are stored and processed. To model a database, the system analyst needs to do the following:1
• Identify and understand those rules that govern patient’s health data.
• Represent those rules so that they can be unambiguously understood by system developers.
• Ensure the rules are consistent (a rule must not contradict other rules).
For example, the Island Medical Program at the University of Victoria (UVic) is planning to design a database (DB) system to store each medical student’s course registration information. The following are some business rules for the database:
• Each medical student is identified by a unique ID. The student can register for many courses in a term.
• A course has a unique ID and course name.
• An instructor has a unique ID and is assigned an office. They can teach many courses in a term.
Modeling Database: Entity Relationship Diagram Design and Normalization
The next step is to model the database. Data modeling is the process of creating a data model by applying formal data model descriptions using data modeling techniques. Several techniques have been developed in the past decades for the design of data models, such as the entity relationship model (ERM), IDEF-1X, object-relational mapping, object role model, and relational model. For database model design, the ERM is the most commonly used tool for communications between database system analysts, programmers, and end users during the analysis phase.
The ERM produces a type of conceptual schema or semantic data model that is used to organize a relational database and its requirements in a top-down fashion (for an example, see Figure 7-3). It contains three major elements:

Figure 7-3 The ERD for UVic course registration system
• Entities A person, place, or object about which the data are collected (the boxes in Figure 7-3 labeled STUDENT, INSTRUCTOR, etc.).
• Attributes Type of information that is captured related to the entity (the fields inside each box in Figure 7-3).
• Relationships The associations and connections between the entities. Depending on the cardinality and modality, a number of relationship symbols are introduced (the lines connecting the boxes in Figure 7-3).
When people design an ERM, they usually use an ERD to serve as a blueprint for database programmers to follow the business rules to build a physical database. This is very similar in building construction. An architect designs a building blueprint, and workers follow the information contained in it to erect the structure. For example, based on the business rules extracted in the previous section, I used Microsoft Office Visio 2007 to construct the ERD shown in Figure 7-3.
Creating a Physical Database Using Structured Query Language
After creating the ERD, programmers are able to create a physical database based on the blueprint. Physical database design requires several decisions that will affect the integrity and performance of the database system. The information needed for this process includes the following:
• Table/column name Usually uses a singular noun or noun phrase, and the name should be specific to the organization (e.g., a university DB uses STUDENT for the table name and uses student_id for the column name in the table to store the student’s ID number)
• Data format Defines the data type (e.g., NUMBER, CHAR, DATE, etc.) for each column to minimize storage space and maximize data integrity
• Constraints Specify the number of instances (e.g., an instructor can teach a maximum of five courses) or value range (e.g., a course score is between 0 and 100) for one column
• Default value Is the value a column will assume (e.g., default value for score is 0) if a user does not provide data
Then, database programmers use SQL to create a physical database with several tables. For example, the four CREATE TABLE statements shown in Figure 7-4 create four tables according to the ERD in Figure 7-3.

Figure 7-4 Four CREATE TABLE statements
Implementing a Healthcare Database Application
The last stage for the database application development is to choose a tool to implement the application. For example, in developing a web-based healthcare database application, there are several available tools for this purpose, such as PHP: Hypertext Preprocessor (PHP), Active Server Pages (ASP)/ASP.NET, Process and Experiment Automation Realtime Language (PEARL), Oracle Application Express (APEX), Java, and C++. Among them, Oracle Application Express is a free, rapid web application development tool for an Oracle database (Oracle is one of the most widely used DBMSs in healthcare today). Using only a web browser and limited programming experience, a database application designer can develop and deploy professional applications that are both fast and secure. For example, using APEX, a page is the basic building block of an application. When you build an application in Application Builder, the APEX interface, you create pages that contain user interface elements, such as tabs, lists, buttons, items, and regions. Then, you add controls to a page on the page definition. For example, based on the tables created in stage 3, I developed a simple web-based database application for health informatics course registration using APEX, as shown in Figure 7-5. In this application, readers can use any Internet browser (e.g., Internet Explorer, Firefox, Chrome) to log into the application (http://db2.his.uvic.ca:8080/apex/f?p=132 ; use username=guest and password=guest). The home page will show all the students’ registration information. The user also can click the tabs at the top of the page to view or edit student profiles, instructor information, and course descriptions.
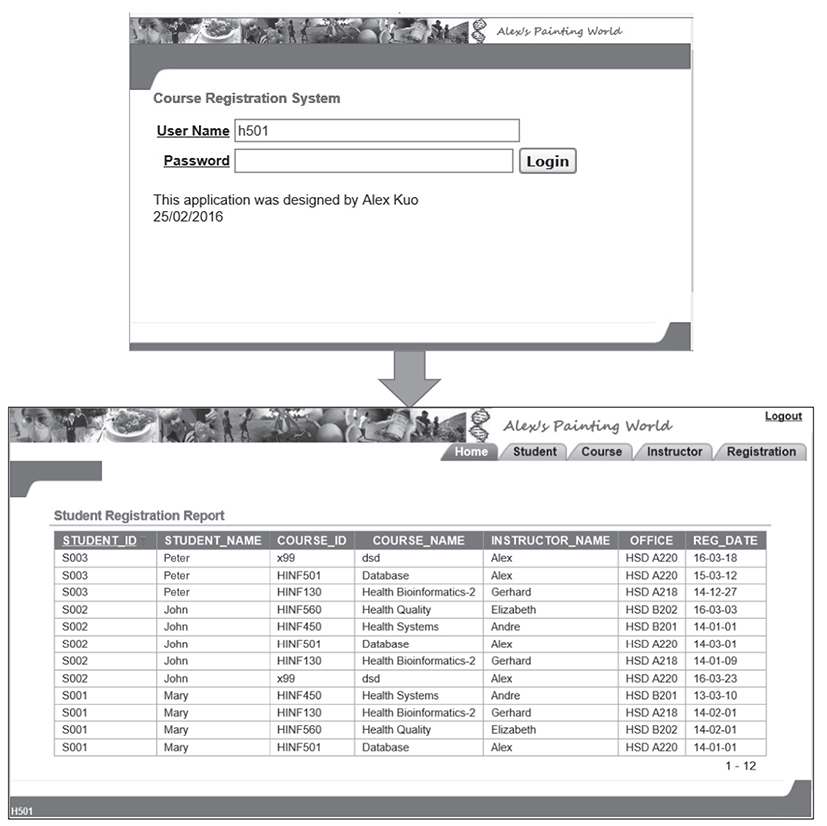
Figure 7-5 A simple APEX application for online course registration
Use Case 7-1: A Web-Based Healthcare Database Application
Background
Take the Pressure Down (TPD) is a joint initiative of the Heart and Stroke Foundation (HSF) and Beacon Community Services in BC, Canada. The program consists of free community clinics providing blood pressure monitoring, risk assessments, and education about hypertension. Readings from TPD sessions can help doctors and clinicians to monitor a patient’s blood pressure when they are not visiting the doctor’s office or clinic. Previously, TPD volunteers used a paper-based form to record patient’s blood pressure, demographic, lifestyle, and health history data. There were three main drawbacks to using this method: paper-based forms required large physical storage; collected data were not available for further review and analysis; and patients/researchers could not access the data at anytime and from anywhere. For these reasons, the TPD research team decided to develop a web-based database system to manage the data, while allowing both patients and physicians to review and monitor blood pressure readings online. The new system requirements include
• First-line nurses/volunteers are able to enter data online, and researchers can access data and perform online analysis anytime, anywhere, and via any device.
• Patients and physicians can review blood pressure history through the Internet, including via a mobile app.
• The system is scalable to contain 34 million records to accommodate the development of a (Canada) national database.
• The system is able to export data into an XML/Excel format for further data interoperability with other systems.
System Implementation and Functions
The system uses Oracle Database 11g Express Edition (XE) as the backend database and the APEX 4.2 Application Builder user interface development tool. Take Blood Pressure Down (TBPD) is the application program/system that was built to enable TPD to be accessed and interacted with by community members.
There are four types of users in the system: administrator users can access all system resources, including user accounts and stored data; nurse/volunteer users can input patient data and view/modify the data if the person has the patient’s permission; physician/researcher users can view all patient data; and patient users can only review his/her own blood pressure history.
The system functions can be represented by the following four usage scenarios:5
• Scenario 1 Dave Fisher is an HSF volunteer to take blood pressure readings and provide recommendations for people. Dave uses the system online registration function to create a volunteer account:
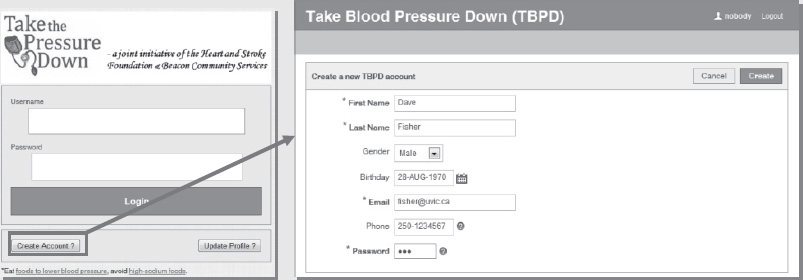
• Scenario 2 Abdul Rauf is a sedentary, middle-aged (DOB 1970) father of two, who often eats fast food as a result of his employer’s frequent last-minute requests that he work overtime. As a consequence of his fast-paced and demanding work environment, he has little time for exercise. Having recently learned that heart disease and stroke are strongly related to high blood pressure, Abdul has decided that he should get his blood pressure assessed when he has time. After completing his weekly shopping, Abdul notices the HSF mobile kiosk at Bay Centre advertising a free service to help with blood pressure reduction through self-monitoring. He speaks to Dave Fisher, who is volunteering at the kiosk, and decides to get a blood pressure assessment. Dave registers Abdul to the system as a new patient and then records Abdul’s blood pressure and related health information including demographic, lifestyle, and health condition data. Dave also helps him download the mobile TPD app:
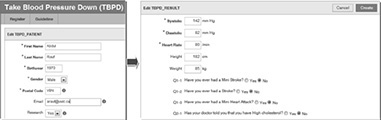
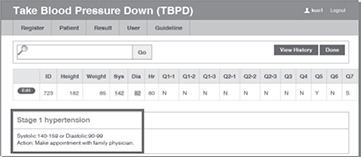
Since the systolic reading (142) falls in Stage 1 hypertension range, the system prompts alert information to recommend that Abdul see his family doctor:
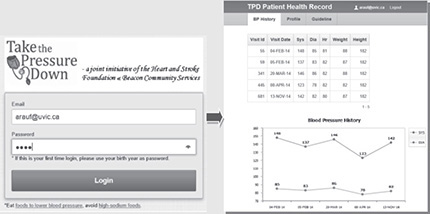
• Scenario 3 Abdul visits his family doctor, who makes several recommendations to help lower his blood pressure and advises him to continue participating in the TPD program, which he does for the next nine months. Abdul uses his iPhone to review his blood pressure history:
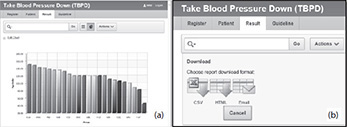
• Scenario 4 Dr. Jeff Li, the manager of HSF BC, provides regular reports that will be used both to assess the success of engagement with the public and to provide blood pressure status for the local population. Dr. Li starts and interacts with the TPD application by selecting appropriate parameters to generate statistical charts that would assist in identifying trends that would enable him to gauge the success of the intervention/project; for example, the average patient’s systolic pressure by area, as shown in the following image (a). The data can be exported into an Excel format for advanced data analysis, as shown in image (b).
The reader can log in to the system at http://db3.his.uvic.ca:8080/apex/f?p=500 as a volunteer (Email: [email protected], Password: 123) to enter patient data; as a doctor (Email: [email protected], Password: 123) to view patient records; or as a researcher (Email: [email protected], Password: 123) to analyze patient data. Also, the reader can log in to the TPD Personal Health Record system at http://db3.his.uvic.ca:8080/apex/f?p=501 (Email: [email protected], Password: 123) to review the blood pressure history as well as exam/test reports for another patient (Christina Lee).
Database Administration and Security
When developing databases, database administration is an important topic that needs to be taken into account in order to ensure that critical health data are managed efficiently and effectively. Another key concept when developing databases for storing and using sensitive health data is security.
Database Administration
Database administration refers to a set of functions for logical and physical database design and for dealing with management issues, such as ensuring database performance, data security and privacy, data backup and recovery, and database availability.1 A database administrator (DBA) must have a sound understanding of current hardware and software (e.g., operating systems [OSs] and networking) architectures, security/privacy policies, and data processing procedures to ensure enough disk space is always available, backups are performed regularly, indexes are maintained and optimized, and database statistics are up to date.
The main database administration tasks are as follows:4
• Managing database memory One of the most important aspects of managing a database is to make sure that there is always enough disk space. As the data size grows, the DBA needs to evaluate whether to allocate more memory to the database.
• Managing users The task includes creating/dropping user accounts, locking and unlocking user accounts, resetting account passwords, granting administrative privileges, and assigning quotas.
• Monitoring the database for performance issues When problems occur within a system, it is important to perform an accurate and timely diagnosis before making any changes to the system. If there is a problem, the DBA may look at the symptoms, analyze statistics, and immediately start changing the system to fix those symptoms.
• Backing up databases As with any database, backups need to be scheduled, executed, and monitored. Details of the process will be discussed in the next section.
• Executing data security/privacy policies Security policies define the rules that will be followed to maintain security in a database system. A security plan details how those rules will be implemented. A security policy is generally included within a security plan. To maintain database security, a DBA follows the organization security plan to grant privileges to enable the user to connect to the database, to run queries and make updates, and to create schema objects.
Database Security
Database security refers to protecting the data against accidental or intentional loss, destruction, misuse, or disclosure to unwanted parties. Some common data security issues include the following:
• Theft and fraud This occurs when any person uses another person’s means of access to view, alter, or destroy data. In some cases, the thief can access a computer room to steal database hardware.
• Data breaches A data breach is the intentional or unintentional release of confidential data (e.g., patient’s health records) to unauthorized third parties.
• Loss of data integrity Data integrity is imposed within a database at its design stage through the use of standard rules and procedures and is maintained through the use of error checking and validation routines. When data integrity is compromised, data will be invalid or corrupted.
• Loss of availability Loss of availability means that data, applications, or networks are unavailable to users and may lead to severe operational difficulties of an organization.
To protect data, database security management must establish administrative policies and procedures, create physical protection plans, institute backup and recovery strategies, and apply hardware or software technologies. Security countermeasures can be categorized into technical and nontechnical methods,1, 6 as described in the following sections. Database backup and recovery is another fundamental best practice in database security management and will also be described below.
Technical Data Security Methods
Technical data security methods include the following:
• Integrity controls Data are kept consistent and correct by means of controls that a database administrator puts on the database. This may involve limiting values a column may hold, constraining the actions that can be performed on the data, or triggering the execution of certain procedures to track access to data (e.g., recording which user has done what and has accessed which data). The tracking or auditing of who accesses patient data (and for what purposes) is especially important given the sensitivity of personal health data.
• Authentication This refers to a way of identifying a user (a person or a software program) by having the user provide a valid ID and password before the access is granted. The process of authentication is based on each user having a unique set of criteria for gaining access.
• Authorization This refers to verifying that the user has authority to access a database object (e.g., table, procedure, or function) before allowing the user to access it. In other words, this determines which actions an authenticated principal is authorized to perform on the database. The tasks required to control authorization are also referred to as access management. As an example of how authentication and authorization work together to provide database security, a user called Alex wants to log in to the www.CyberHealth.com server to use the EHR system that can be accessed from that site. In this example, authentication is the mechanism whereby the system running at www.CyberHealth.com should securely identify the user Alex. The authentication must provide answers to the following questions:
• Who is the user Alex?
• Is the user Alex really who he represents himself to be?
To answer these questions, the server depends on some unique bits of information known only to Alex. It may be as simple as a password or public key authentication or as complicated as a Kerberos-based system. If the authenticating system can verify that the shared secret was presented correctly, then the user Alex is considered authenticated. What’s next? The server running at www.CyberHealth.com must determine what level of access Alex should have. For example, is Alex authorized to view a specific patient’s data? Is Alex authorized to modify the patient’s data? Is Alex authorized to delete the patient’s data? In this example, the server uses a combination of authentication and authorization to secure the system. The system ensures that the user claiming to be Alex is really Alex and thus prevents unauthorized users from gaining access to secured resources running on the EHR system at the www.CyberHealth.com server.
• User-defined procedures User-defined procedures or interfaces allow system designers to define their own security procedures in addition to the authorization rules.
• Data encryption This refers to mathematical calculations and algorithmic schemes that transform plain text into cybertext; in other words, text is converted into a form that is not readable to unauthorized parties. Using encryption, a key specifies the particular transformation of plain text into cybertext, or vice versa, during decryption. The following are two common encryption methods for data protection:
• Secret-key encryption (aka symmetric-key cryptography) This refers to a class of algorithms for cryptography that use trivially related, often identical, cryptographic keys for both decryption and encryption. Examples of popular and well-respected symmetric algorithms include AES, Blowfish, CAST5, RC4, TDES, and IDEA.
• Public-key encryption (aka asymmetric-key cryptography) In public-key cryptography, a user has a pair of cryptographic keys: a public key and a private key. The private key is kept secret, while the public key may be widely distributed. Incoming messages would have been encrypted with the recipient’s public key and can be decrypted only with the recipient’s corresponding private key. Examples of popular and well-respected public-key algorithms include RSA, ElGamal, Knapsack, ECC, and Diffie-Hellman.
• Firewall This refers to an integrated collection of security measures designed to prevent unauthorized electronic access to a networked computer system. It is also a device or set of devices configured to permit, deny, encrypt, decrypt, or proxy all computer traffic between different security domains based upon a set of rules and other criteria.
• Intrusion detection system (IDS) This refers to software and/or hardware designed to detect unwanted attempts at accessing, manipulating, and/or disabling of computer systems, mainly through a network, such as the Internet.
• Data masking This refers to the process of obscuring (masking) specific data within a database table or column to ensure that data security is maintained and sensitive customer information is not leaked outside of the authorized environment. Common methods of data masking include encryption, masking (e.g., numbers for letters), substitution (e.g., all male names = Alex), nulling (e.g., ####), or shuffling (e.g., zipcode12345 = 51432).
Nontechnical Data Security Methods
Nontechnical data security methods include the following:
• Personnel controls This refers to exerting control over who can interact with a resource. The resource can be database data, an application, or hardware. Activities such as monitoring to ensure that personnel are following established security practices can be carried out. Standard job controls, such as separating duties so no one employee has responsibility for an entire system or keeping system developers from having access to production systems, should also be enforced (particularly in healthcare, where the data stored can be considered to be sensitive).
• Physical access controls These limit access to particular computer rooms in buildings and are usually part of controlling physical access. Sensitive equipment (hardware and peripherals) must be placed in secure areas (e.g., locked to a desk or cabinet). Also, an alarm system can deter a brute-force break-in.
• Maintenance controls The healthcare organization should review external maintenance agreements for all hardware (e.g., server, networks) and software (e.g., source codes) that the database system is using to ensure system performance and data quality.
• Data privacy controls Breaches of confidential data (e.g., patient health data) could result in loss of user trust in the organization and could lead to legal action being taken against the healthcare organization. Information privacy legislation plays a critical role in protecting user data privacy. For example, the U.S. Health Insurance Portability and Accountability Act (HIPAA) is a federal law enacted to ensure that the freedom of patients to choose healthcare insurers and providers will not come at the expense of the privacy of their medical records.7
Database Backup and Recovery
Database backup and recovery are mechanisms for restoring databases quickly and accurately after loss or damage. A DBMS should provide four basic facilities for the backup and recovery of a database:1
• Backup facilities that provide periodic backup copies of the database (backup data should be kept offsite at safe locations)
• Journalizing facilities that maintain an audit trail of transactions and database changes
• A checkpoint facility by which the DBMS periodically suspends all processing and synchronizes its files and journals to establish a recovery point
• A recovery manager that allows the DBMS to restore its original condition if needed
Much more about security can be found in Part VI of this book.
Data Warehouses for Healthcare
The need to analyze large amounts of health data is becoming increasingly important to managers, healthcare organizations, and healthcare researchers. In response to this, new ways of organizing health data have been developed to help health professionals and managers query health data. As a consequence, in recent years the concept of a data warehouse has emerged in healthcare.
What Is a Data Warehouse?
Healthcare is information dependent and cannot be provided efficiently without data regarding the patient’s past and current conditions. Patient health records provide the who, what, when, where, and how of patient care, and they are the resources needed for further decision support and knowledge discovery. Unfortunately, in the real world, clinical data come from many different sources, such as patient visits, test results, laboratory reports, diagnoses, therapy, medication, and procedures. These data are usually stored in distributed and heterogeneous databases. For example, a patient’s registration data may be stored in a Microsoft Access database, a laboratory report may be stored in a Sybase database, diagnosis information in an IBM Informix database, and medication information in an Oracle database. Healthcare professionals need to integrate the data from several transaction information systems (databases) to provide quality treatment and patient care. However, heterogeneous data and distributed data repositories make clinical decisions difficult (Figure 7-6). A data warehouse (DW) integrates (extracts, transforms, and loads [ETL]) data from several transaction information systems into a staging area. It is believed that a DW can provide healthcare professionals with clinical intelligence that enables them to better understand problems, discover opportunities, and measure performance.8
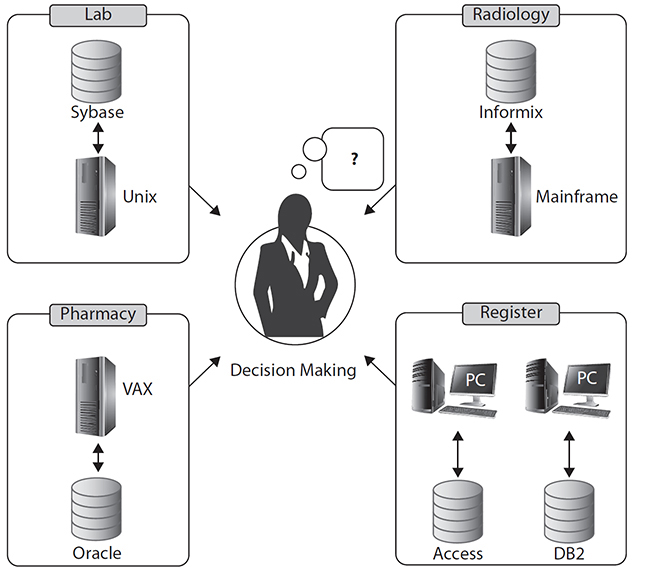
Figure 7-6 Heterogeneous data and distributed data repositories make clinical decision making difficult.
Bill Inmon defined the data warehouse as “a subject-oriented, integrated, non-volatile and time-variant collection of data in support of management’s decisions.”9 In other words, a data warehouse is a repository of an organization’s electronically stored data designed to facilitate reporting and analysis. This classic definition of a data warehouse focuses on data storage. However, the means to retrieve and analyze data; to extract, transform, and load data; and to manage the dictionary data are also considered essential components of a data warehousing system.
The Differences Between a DW and OLTP
Online transaction processing (OLTP) refers to a set of programs that help users manage transaction-oriented applications in industries, such as banking, airlines, supermarkets, and manufacturing. These transaction-oriented applications include data entry and retrieval transactions. Data warehouses are different from OLTP based on the following five aspects.
Design Objectives
• OLTP is a software system that facilitates and manages transaction-oriented applications, typically for data entry and retrieval transaction processing.
• A DW is a decision-making-oriented repository. It is mainly used for decision analysis, with strong interoperability between different computer systems.
Data Types
• OLTP contains department detail, short-period data, snapshot, and/or ongoing status of business.
• A DW consists of an enterprise-level, integrated, time-variant, and nonvolatile collection of data. Data often originates from a variety of sources. It may include five types of data (Figure 7-7): current operational data, legacy data, lightly digested data, heavily digested data, and metadata.
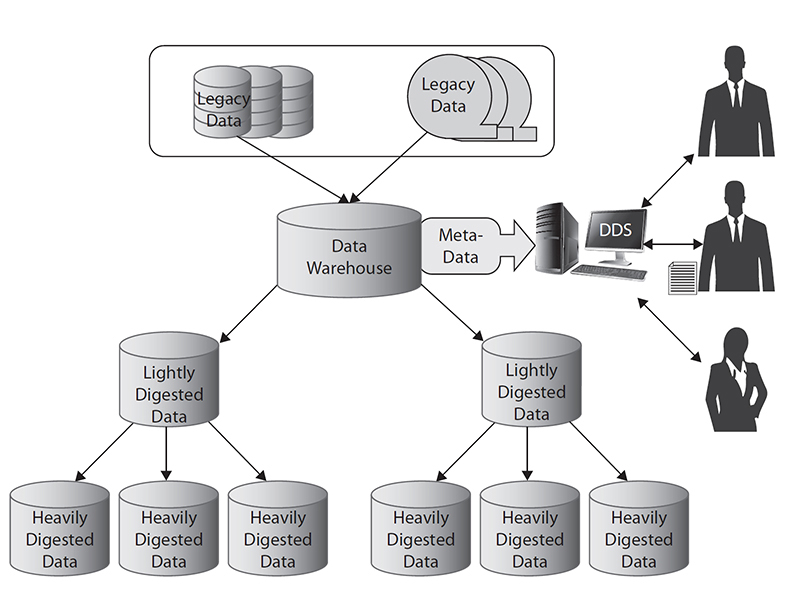
Figure 7-7 Five data types in a data warehouse
Functionalities
• OLTP provides online query, modify, insert, and delete functions. Efficiency and steadiness are major goals for OLTP.
• DW is subject-oriented and supports a variety of decision analysis functions as well as strategic operational functions.
Data Structures
• OLTP usually contains many relational tables and is highly normalized.
• A DW uses a star schema to store data. The star schema consists of a few “fact tables” (possibly only one, justifying the name) referencing any number of “dimension tables.” The fact table holds the main data while the smaller dimension tables describe each value of a dimension and can be joined to fact tables as needed (Figure 7-8).
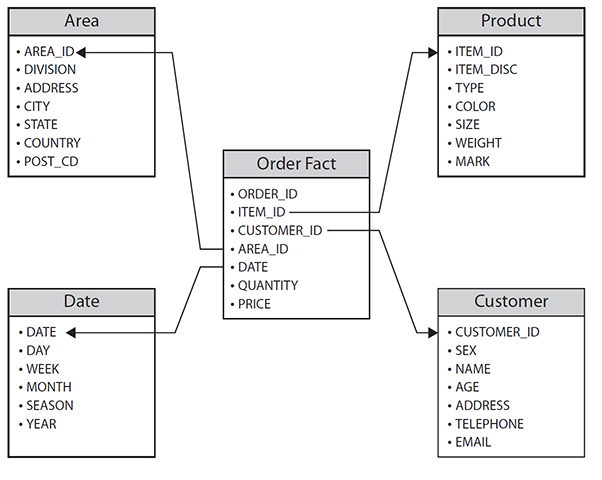
Figure 7-8 A star schema data structure
Analytical Capabilities
• OLTP helps users control and run fundamental business tasks. It possesses limited analytical capabilities.
• A DW enables users to analyze different dimensions of multidimensional data. For example, it provides time series and trend analysis views.
Data Warehouse Models
Data warehousing supports a variety of decision analysis functions as well as strategic operational functions. Data often originate from a variety of sources (different types of databases), formats, and types, and are generally consolidated, transformed, and loaded into one or more instances of a DBMS to facilitate a broad range of analytical applications. A data warehouse may consist of a single large enterprise-wide database to which users and administrators connect directly, or it may incorporate several smaller systems, called data marts, each of which addresses a specific subject area within the overall warehouse. Online analytical processing (OLAP) is the core component of data warehousing and analytics. It gives users the ability to interrogate data by intuitively navigating from summary data to detail data.
In real applications, you can use four aspects—functionalities, storage location, topology, and data status—to categorize a data warehouse model, as described in the following sections.
Categorized by Functionalities (Enterprise DW vs. Department DW)
• An enterprise DW (also called EDW, Figure 7-9) supports a variety of decision-analysis functions as well as strategic operational functions.
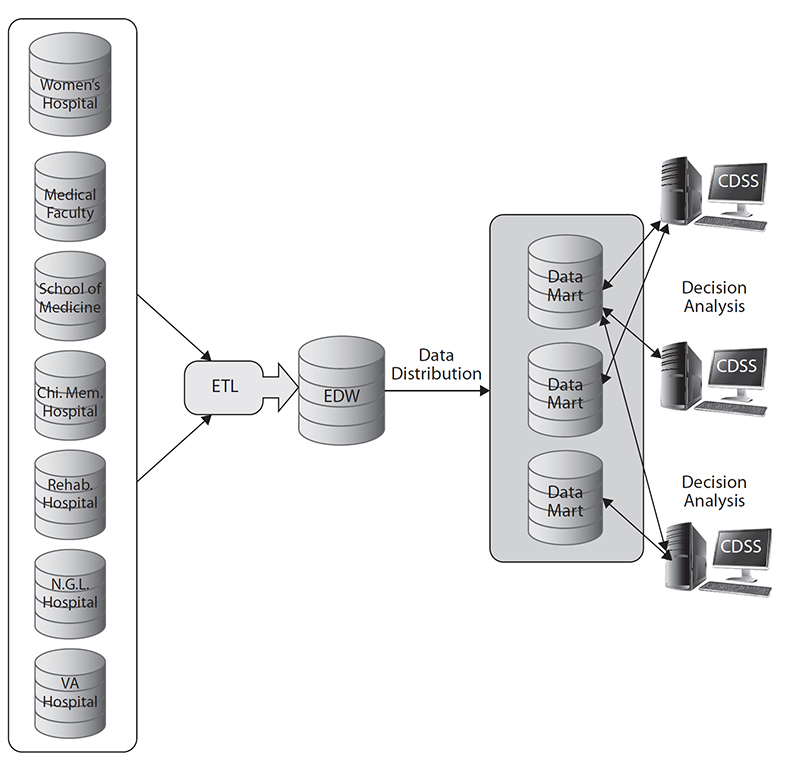
Figure 7-9 Enterprise DW vs. department DW (data mart) model. (CDSS refers to clinical decision support system)
• A department DW (also called a data mart, a subset of EDW) is usually oriented to a specific purpose or major data subject that may be distributed to support businesses and contains analytical data designed to focus on specific business functions for a specific community within an organization.
Categorized by Storage Location (Centralized DW vs. Distributed DW)
• A centralized DW consists of a single large enterprise-wide database. Data often originate from a variety of sources and are loaded into one or more instances of a DBMS to facilitate a broad range of analytical applications. The main benefit of this model is that data are more consistent and easy to maintain. However, the major concern of this model is that it has high development and maintenance costs (based on the data level and security level).
• A distributed DW (Figure 7-10) usually consists of several department DWs (data marts). This model is suitable for companies doing distributed business operations.
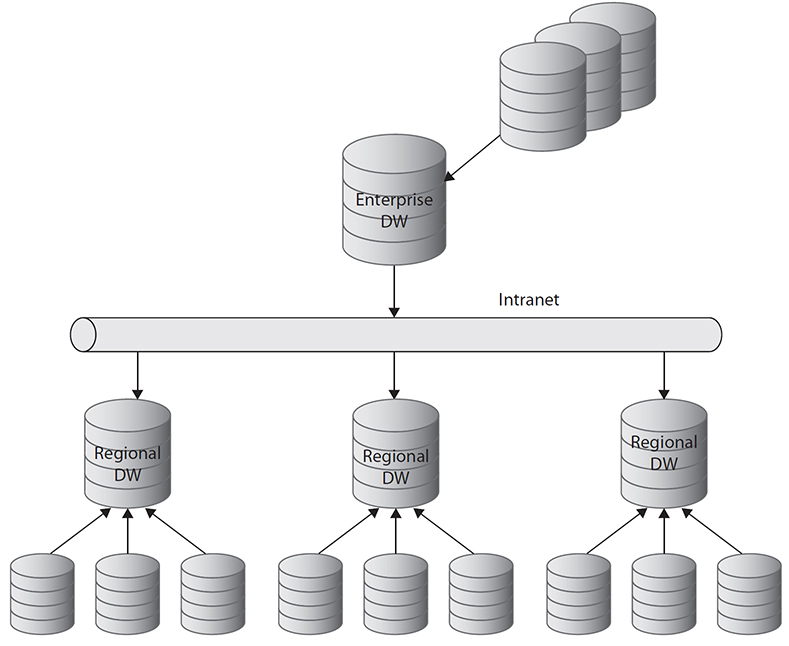
Figure 7-10 A distributed DW model
Categorized by Topology (Physical DW vs. Virtual DW)
• A physical DW stores all aggregate data in a physical storage location. The DW consists of five types of data: current operational data, legacy data, lightly digested data, heavily digested data, and metadata.
• A virtual DW does not store data in a physical storage location. This model is a virtual (conceptual) DW that uses an intranet/Internet to connect all distributed databases (Figure 7-11).
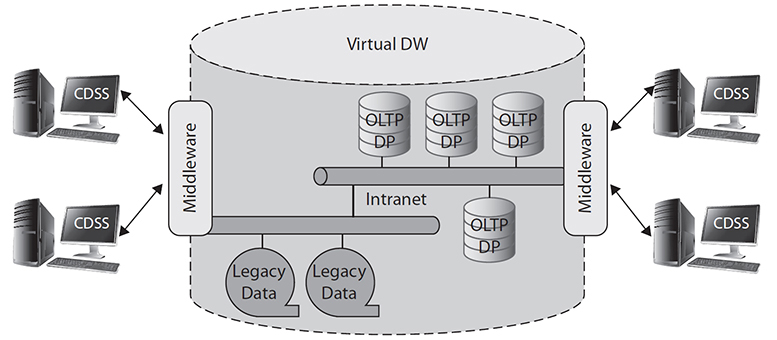
Figure 7-11 A virtual DW model
Categorized by Data Status (Dynamic DW vs. Static DW)
• A dynamic DW consists of a snapshot DW and a longitudinal DW (Figure 7-12). It can be applied to an organization that needs both short-term tactical analysis and long-term strategic analysis. This model requires high development and maintenance costs. Therefore, it is seldom used in real applications.
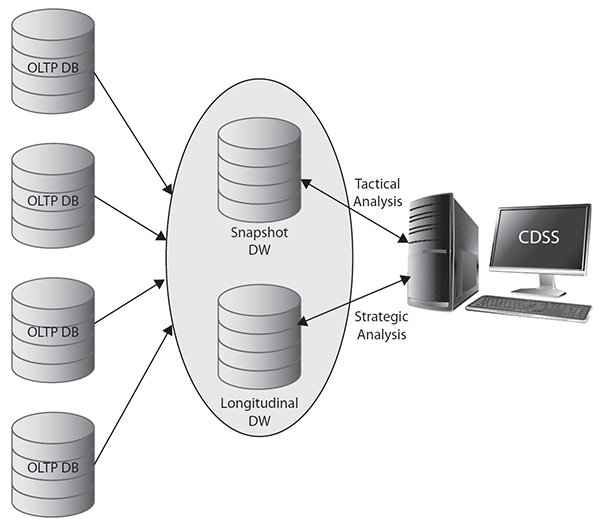
Figure 7-12 A dynamic DW model
• A static DW is an EDW or a data mart that consists of a nonvolatile (static) collection of data.
A Healthcare Data Warehouse Life Cycle
The classical system development life cycle (SDLC) is not suitable for data warehouse development.9 The data warehousing industry is in agreement that the data warehouse life-cycle model should consist of the following five major phases.10, 11, 12
Phase 1: Requirement Analysis
All IT systems of any kind need to be built to suit user needs. A system must be usable. If the system is not used, there is no point in building it. To become a real organizational asset leveraged throughout healthcare systems, user requirements must be carefully analyzed and defined before implementing a data warehouse. The system analyst talks to the user to understand the details of the processes, the business, the data, and the issues; arrange site visits to get firsthand experience; discuss the meaning of the data, the user interface, and so on; and document them. The system analyst also lists the nonfunctional requirements such as performance and security.
Phase 2: System Design
Key activities in this phase are to determine the data warehouse model; design the extraction, transformation, and loading system; and draw the front-end applications. Tasks typically include cataloging the source system, defining key performance indicators (KPIs) and other critical business metrics, mapping decision-making processes underlying information needs, and designing the logical and physical schema.
Phase 3: Prototype Development
This phase builds the three parts that are designed in the previous phase: the data stores, the ETL system (including data quality system and metadata), and the front-end applications. With some caution and consideration, these three parts can be built in parallel. The most important consideration when building in parallel is to define accurate interfaces between the parts. The primary objective of prototype development is to constrain, and in some cases reframe, end-user requirements by showing opinion leaders and heavyweight analysts in the end-user communities precisely what they had asked for in the requirement analysis phase or in the previous prototyping iteration.
Phase 4: System Deployment
Deployment typically involves two separate deployments: the deployment of a prototype into a production-test environment and the deployment of a stress-tested, performance-tested production configuration into an actual production environment. Once a user-approved DW is ready, the development team puts all the components in the production boxes (the ETL system, the data stores, and the front-end applications) and deploys the system for actual production use.
Phase 5: System Operation
This phase involves the day-to-day maintenance of the data warehouse. The operations team continues to administer the data warehouse and to support the users. There are basically three types of support: helping new and existing users using the system, administering new users and their access rights, and solving errors or problems that happen when using the data warehouse. Users will also have enhancement requests: to add more data to the data warehouse (or change existing data), to add a feature to the front-end applications, or to create new reports or new data structures. In such cases, the development team may include these requests in the next release.
Data Mining in Healthcare
As the amount of stored health data increases exponentially, it’s increasingly recognized that such data can be analyzed or “mined” to uncover new and important patterns. This section explores the role of data mining in identifying and revealing important patterns or trends in health data.
What Is Data Mining?
Data mining (DM) is different from OLAP that focuses on the interactive analysis of data and typically provides extensive capabilities for visualizing the data and generating summary statistics.13 Data mining is “an integral part of knowledge discovery in database (KDD), which is the overall process of converting raw data into useful information.”14 In other words, it is the process of automatically discovering useful information in large data repositories (e.g., data warehouses). The data mining process consists of four major transformation phases,15 as shown in Figure 7-13.
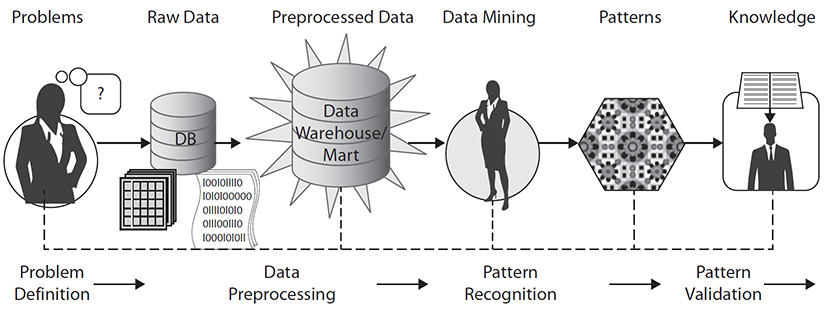
Figure 7-13 A generic process of data mining
1. Problem definition phase A healthcare data mining project starts with an understanding of the healthcare problems. Data mining experts, business experts (healthcare setting managers), and domain experts (healthcare professionals) work closely together to define the project objectives and the requirements from a healthcare quality improvement perspective. The project objective is then translated into a data mining problem definition. In the problem definition phase, data mining data and tools are not yet required.
2. Data preprocessing phase The original or “raw” data provided for data mining often need certain levels of preprocessing before the data can be input to a data mining algorithm. The purpose of preprocessing is to transform the raw data into an appropriate format for subsequent analysis. The tasks involved in data preprocessing include fusing data from multiple sources (files, spreadsheets, or database tables), cleaning data, integrating data, and transforming data.
Real-world data tend to be incomplete (lacking attribute values or certain attributes of interest or containing only aggregate data), noisy (containing errors or outlier values that deviate from the expected), and inconsistent (e.g., containing discrepancies in the department codes used to categorize items). Data cleaning routines attempt to fill in missing values (e.g., fill in the most probable values), smooth out noise (e.g., apply binning, regression, and clustering algorithms to remove noisy data), and correct inconsistencies in the data (e.g., correct a patient’s age that might be listed as –25 or 154).
Data integration involves merging data from multiple sources inside/outside heterogeneous databases, data cubes, or flat files into a coherent data store (e.g., data warehouse) for further data mining processing. This task usually encounters many interoperability issues. Kuo et al.16 described several interoperability issues and approaches to deal with the issues.
For example, data from multiple data resources may need to be transformed into forms appropriate for mining, such as transforming patient gender from male/female data to M/F or 1/0, normalizing data values from –100~100 to 1.0~1.0, or categorizing age ranges from 0~130 to youth/middle-age/senior.
3. Pattern recognition phase This phase involves choosing the proper data mining algorithm to discover the patterns. Basically, these algorithms can be divided into four types:
• Clustering This refers to the task of discovering groups and structures in the data that are in some way or another similar, without using known structures in the data.
• Classification This refers to the task of generalizing a known structure to apply to new data. In other words, it predicts one or more discrete variables, based on the other attributes in the data set.
• Regression This refers to predicting one or more continuous variables, such as profit or loss, based on other attributes in the data set. It attempts to find a function that models the data with the least error.
• Association This refers to finding correlations between different attributes in a data set. The most common application of this kind of algorithm is for creating association rules, which can be used in a market basket analysis. For example, the Apriori association algorithm can produce association rules that indicate what combinations of medications and patient characteristics lead to adverse drug reactions (ADRs).17
Choosing the best algorithm to use for a specific analytical task can be a challenge. While you can use different algorithms to perform the same business task, another algorithm may produce a different result, and some algorithms can give more than one type of result.
4. Pattern validation phase Pattern (rule) validation is the process of assessing how well the mining models perform against real data. It is important that the mining team validates the discovered patterns before deploying them into a production environment. There are several approaches for validating the patterns.18 The following are some examples:
• Using statistical validity to determine whether there are problems in the data or in the model A number of statistical methods can be used to evaluate the data mining model quality or pattern accuracy, such as cross-validation and receiver operating characteristic (ROC) curves.
• Separating the data into training and testing sets to test the accuracy of patterns It is common for the data mining algorithms to find patterns in the training set that are not present in the general data set. To deal with the so-called over-fitting issue, the validation uses a test data set that the data mining algorithm was not trained on. The learned patterns are applied to the data set, and the resulting output is compared to the desired output.
• Asking domain experts to review the results of the data mining to determine whether the discovered patterns have meaning in the targeted business scenario In a health data mining project, physicians and healthcare domain experts will be involved in the validation process to interpret the accuracy of the patterns.
Applications of Data Mining in Healthcare
In recent years, data mining has received considerable attention as a tool that can be applied to healthcare research and management. To perform descriptive and predictive analysis, data mining employs various analysis methods, which include clustering, classification, regression, and association analysis (as discussed in the previous section), to discover interesting patterns in the given data set that serve as the basis for estimating future trends. For example, Kuo et al. proposed an association analysis algorithm for the detection of adverse drug reactions in healthcare data.17 The Apriori algorithm was used to perform association analysis on the characteristics of patients, the drugs they were taking, their primary diagnosis, co-morbid conditions, and the ADRs or adverse events (AEs) they experienced. This analysis produced association rules that indicate what combinations of medications and patient characteristics lead to ADRs. Cheng et al. proposed the use of classification algorithms to help in the early detection of heart disease, a major public health concern all over the world.19 Balasubramanian and Umarani identified the risk factors associated with high levels of fluoride content in water, using data mining algorithms to find meaningful hidden patterns to support meaningful decision making about this real-world health hazard.20 The Concaro et al. study21 focused on the care delivery flow of diabetes mellitus and applied a data mining algorithm for the extraction of temporal association rules on sequences of events. The method exploited the integration of different healthcare information sources and was used to evaluate the pertinence of care delivery flow for specific pathologies in order to refine inappropriate practices that lead to unsatisfactory outcomes.
In research of data mining applied to cancer detection and treatment, Luk et al.22 used Artificial Neural Network (ANN) and Classification And Regression Tree (CART) algorithms to distinguish tumor from non-tumor liver tissues. Eventually, they revealed that these classification algorithms were suitable for applying the building of a tissue classification model based on the hidden pattern in the proteomic data set. In addition, ANN and CART algorithms generated good predictive abilities for differentiating between tumor and non-tumor tissues for liver cancer. Cao et al. proposed the use of data mining as a tool to aid in monitoring trends in clinical trials of cancer vaccines. By using data mining and visualization, medical experts could find patterns and anomalies better than just looking at a set of tabulated data.23 Many other real data mining applications in healthcare have been described.24 Kalish has also described many real-world examples of how data mining has helped to reduce healthcare cost.25
Despite the benefits of applying data mining to healthcare quality improvement, Shillabeer and Roddick26 have indicated several inherent conflicts between traditional applications of data mining and applications in medicine. Perhaps the most challenging issues for the application of this technology to healthcare are data security and privacy. Therefore, an organization must formulate clear policies regarding the privacy and security of patient health records before embarking on data mining, and it must enforce those policies with its partner-stakeholders and agencies.
Cloud Computing in Healthcare
Cloud computing is becoming a major trend in business and computing and is becoming an important topic in healthcare IT. Cloud computing can be defined as a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources that can be rapidly accessed with minimal management effort or service-provider interaction.5 Cloud computing differs from traditional approaches in a number of ways. Cloud computing can provide a wide range of computing resources on demand anywhere and anytime. The approach eliminates up-front costs and infrastructure development by cloud users (as services and infrastructure can be hosted over the Internet) and it allows users to pay for use of only those computing resources they need and on a short-term basis as needed.27 As the reader may be able to tell by this overview paragraph about cloud computing, cloud computing is much more than data storage. However, cloud computing does have major data storage capability and is used more and more by database administrators as important scalable data storage and ready access components of an overall DBMS. Hence the introduction and discussion to cloud computing’s inclusion in this chapter, in addition to several other chapters in this book where this major phenomenon could reside as well.
Cloud Computing Models
Cloud computing includes three major models:
• Software as a Service (SaaS) Healthcare applications (e.g., EHRs) can be hosted by a cloud service provider and made available to customers (e.g., physicians) over a network (typically the Internet). The EHR application can be provided to the user through a thin client interface (e.g., a browser). In healthcare, several vendors are offering applications using the SaaS model. Examples of SaaS in other areas include Google Apps, Oracle On Demand, Salesforce.com, and Microsoft Azure SQL Database.
• Platform as a Service (PaaS) Development tools such as operating systems and development frameworks can also be hosted in the cloud and accessed remotely through a browser. Using this approach, developers can build applications without installing software tools on their computer, making the process of development easier.
• Infrastructure as a Service (IaaS) IaaS provides hardware assets that can be accessed remotely. For example, the cloud can provide storage, hardware, servers, and networking components. The cloud service provider has the responsibility for housing, running, and maintaining the services and the client typically pays on a per-use basis.
Cloud Computing Deployment Models
There are three main models for deploying cloud computing:
• Private cloud A proprietary network or data center supplies hosted services to specific users. Here the infrastructure on the cloud is operated and controlled exclusively for a specific organization and is not made public.
• Public cloud The cloud services (applications and storage) are made available for public use and the cloud is owned by an organization that sells cloud services.
• Hybrid cloud This kind of cloud combines multiple clouds that can be private or public. For example, an organization may provide and manage some resources within its own data center but rely on other services provided externally.
Examples of Cloud Computing in Healthcare
Medical record services are now beginning to be offered “in the cloud,” such as through Microsoft HealthVault and Amazon Web Services (AWS). AWS hosts a collection of healthcare IT offerings, including healthcare data storage applications and web-based health records services; for example, AWS can be used to build personal health record (PHR) offerings. In the pharmaceutical industry, companies are beginning to streamline business operations using cloud-based software. In the government sector, the U.S. Department of Health and Human Services (HHS) Office of the National Coordinator for Health IT (ONC) has selected a cloud computing and project management system to manage the selection and implementation of EHR systems. In Europe, consortia have used cloud computing services for supporting remote monitoring, diagnosing, and assisting of patients outside of a hospital setting.28
Pros and Cons of Cloud Computing in Healthcare
Although cloud computing promises to provide more flexibility, less expense, and more security to end users, its application in healthcare has both strengths and weaknesses.
A significant strength to cloud computing is its scalability for data storage. Data storage for even a medium-sized database application in healthcare can be tricky to plan for given the changing and sometimes unpredictable nature of clinical practice. For example, if a HIT application adds patient genotype functionality to its existing patient phenotype capability, its data storage needs may rise significantly. A cloud computing highly scalable data storage solution to challenges like these is very attractive to DBAs. Another strength includes the fact that hardware and server issues (in terms of cost and complexity of maintaining technology) that exist for locally installed legacy systems are largely eliminated with cloud computing. Smaller hospital and medical practices that typically don’t have internal IT staff to maintain and service in-house infrastructure may find this alternative attractive. Furthermore, the pay as you go model can be attractive to physicians and many healthcare organizations.
Several limitations and considerations need to be taken into account before deciding on a cloud-based solution in healthcare. First, there may be lack of familiarity and experience with cloud computing, requiring, among other things, substantial training for HIT staff. Second, insufficient evidence currently exists to show the cloud approach is suitable for more than only a few healthcare applications. Although the approach has been successfully applied in other domains, differences particular to healthcare may make it too difficult to implement more widely at the current time, including the need to ensure the security and privacy of health data stored or accessed using a cloud-based approach. State/province, federal/national, or even international legal data jurisdiction concerns are being raised. Questions about potential performance unpredictability, including data transfer bottlenecks and unknown impacts on the increasing importance of data interoperability in healthcare, are also being raised.
Cloud computing and its use in healthcare is evolving rapidly. Given the many advantages of cloud computing, the current disadvantages or areas of concern are likely to be resolved, mitigated, or substantially eliminated.
Chapter Review
Healthcare is the most data-intensive industry in the world today. Health information systems can be used by healthcare professionals to improve healthcare services and reduce costs. The challenge for HIT is how to make data useful for clinicians and empower them with the tools to make informed decisions and deliver more responsive patient services.
In this chapter, the requirements for databases in healthcare and the basics of relational databases, database models, database administration, and security were discussed. The steps involved in developing healthcare databases were described and illustrated, including a use case of a web-based healthcare database application. Two important and emerging database applications, health data warehousing and data mining, were also described and discussed.
A data warehouse (DW) integrates data from several transaction information systems (databases) into a staging area. DWs can provide healthcare professionals with clinical intelligence that will enable them to better understand clinical problems, discover opportunities, and measure the performance of healthcare systems.
Data mining (DM) is the process of automatically discovering useful information from large data repositories (e.g., data warehouses). In recent years, data mining has received considerable attention as a tool that can be applied in healthcare research and management.
Cloud computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources that can be accessed with minimal management effort or service-provider interaction. One of the configurable and scalable resources of cloud computing is its large and relatively affordable data storage capability. Given HIT’s increasing need for data storage, this is an attractive attribute for HIT managers.
A case study was also used to help you learn about the concepts of databases, data warehouses, and data mining in healthcare.
Questions
To test your comprehension of the chapter, answer the following questions and then check your answers against the list of correct answers at the end of the chapter.
1. What is a database model?
A. A file processing system
B. The structure of a database
C. A set of mathematic algorithms
D. A database management system (DBMS)
2. In the relational database model, _________________.
A. a table name is used to uniquely identify a column
B. the primary key is used to identify a column in one table that refers to a column in another table
C. tables are the basic unit of data storage
D. Data Control Language (DCL) statements can commit or roll back the processing of transactions
3. What is a database management system (DBMS)?
A. A set of software programs to control the organization, storage, management, and retrieval of data in a database
B. A nonprocedural programming language
C. A data security mechanism
D. A set of Data Definition Language (DDL) statements
4. What is the most commonly used tool for modeling a database?
A. Entity relationship diagram
B. IDEF-1X
C. Object role model
D. Spiral developing model
5. Which of the following statements is correct?
A. Authorization is a way of identifying a user before access is granted.
B. A database administrator puts integrity controls on the database to ensure that data are kept consistent and correct.
C. Data breaches mean that data, applications, or networks are unavailable to database users.
D. Data security is not important in the database system design.
6. A distributed data warehouse _________________.
A. stores all aggregated data in a single physical storage location
B. is also called online analytical processing (OLAP)
C. usually consists of several department data marts
D. consists of snapshot and longitudinal databases
7. What is not the reason for creating a data mart?
A. Lowering cost
B. Providing more business functions
C. Improving end-user response time
D. Creating a collective view for a group of users
8. Which of the following is considered a potential negative issue with cloud computing in healthcare?
A. The high cost of setting up cloud computing
B. Lack of easy accessibility to data resources
C. Privacy and confidentiality of health data stored on a cloud
D. Need for advanced technical knowledge
Answers
1. B. A database model is the structure of a database.
2. C. In the relational database model, tables are the basic unit of data storage.
3. A. A database management system (DBMS) is a set of software programs to control the organization, storage, management, and retrieval of data in a database.
4. A. The most commonly used tool for data modeling database is an entity relationship model (ERM).
5. B. Integrity controls keep the data consistent and correct by means of controls that a database administrator puts on the database.
6. C. A distributed data warehouse usually consists of several department data marts.
7. B. Creating a data mart is not for providing more business functions.
8. C. The confidentiality and privacy of data must be considered when using a cloud-based solution for healthcare applications involving the storage of health data.
References
1. Hoffer, J. A., Prescott, M. B., & McFadden, F. R. (2005). Modern database management, seventh edition. Pearson.
2. Hey, T., & Tansley, S. (Eds.). (2010). The fourth paradigm: Data-intensive scientific discovery. Microsoft Research.
3. Collen, M. F. (2011). Computer medical databases: The first six decades (1950–2010). Springer-Verlag London.
4. Murray, C., et al. (2014). Oracle Database Express Edition 2 day DBA, 11g Release 2 (11.2). Oracle. Accessed on July 15, 2016, from http://docs.oracle.com/cd/E17781_01/server.112/e18804/toc.htm.
5. Kuo, M. H. (2015). Implementation of a cloud-based blood pressure data management system. Studies in Health Technology and Informatics, 210, 882–886.
6. Wiederhold, G. (1981). Database technology in healthcare. Journal of Medical Systems, 5, 175–196.
7. Health Insurance Portability and Accountability Act (HIPAA). (1996). Privacy and security rules. Accessed from https://www.hhs.gov/hipaa/index.html,
8. Akhtar, M. U., Dunn, K., & Smith, J. W. (2005). Commercial clinical data warehouses: From wave of the past to the state of the art. Journal of Healthcare Information Management, 12, 20–26.
9. Inmon, W. H. (2005). Building the data warehouse, fourth edition. John Wiley & Sons.
10. WhereScape Software. (2003). Understanding the data warehouse lifecycle model, revision 2. Accessed on July 12, 2016, from www.bossconsulting.com/oracle_dba/white_papers/DW%20in%20oracle/DW_model_lifecycle.pdf.
11. Kimball, R., Ross, M., Thornthwaite, W., Mundy, J., & Becker, B. (2008). The data warehouse lifecycle toolkit, second edition. John Wiley & Sons.
12. Rainardi, V. (2011). Building a data warehouse with examples in SQL Server. Apress.
13. BARC. (2010). What is OLAP? An analysis of what the often misused OLAP term is supposed to mean. Accessed on January 28, 2017, from http://barc-research.com/research/business-intelligence/.
14. Tan, P. N., Steinbach, M., & Kumar, V. (2005). Introduction to data mining. Addison-Wesley.
15. Fayyad, U., Piatetsky-Shapiro, G., & Smyth, R. (1996). The KDD process for extracting useful knowledge from volumes of data. Communications of the ACM, 39, 27–34.
16. Kuo, M. H., Kushniruk, A. W., & Borycki, E. M. (2011). A comparison of national health data interoperability approaches in Taiwan, Denmark and Canada. Electronic Healthcare, 10, 14–25.
17. Kuo, M. H., Kushniruk, A. W., Borycki, E. M., & Greig, D. (2009). Application of the Apriori algorithm for adverse drug reaction detection. Studies in Health Technology and Informatics, 148, 95–101.
18. Richesson, R. L. (2012). Clinical research informatics. Springer.
19. Cheng, T. H., Wei, C. P., & Tseng, V. S. (2006). Feature selection for medical data mining: Comparisons of expert judgment and automatic approaches. Proceedings of the 19th IEEE Symposium on Computer-Based Medical Systems, IEEE Computer Society, Washington, DC, June 22–23 (pp. 165–170).
20. Balasubramanian, T., & Umarani, R. (2012). Clustering as a data mining technique in health hazards of high levels of fluoride in potable water. International Journal of Advanced Computer Sciences and Applications, 392, 166–171.
21. Concaro, S., Sacchi, L., Cerra, C., & Bellazzi, R. (2009). Mining administrative and clinical diabetes data with temporal association rules. Studies in Health Technology and Informatics, 150, 574–578.
22. Luk, J. M., Lam, B. Y., Lee, N. P., Ho, D. W., Sham, P. C., Chen, L. … Fan, S. T. (2007). Artificial neural networks and decision tree model analysis of liver cancer proteomes. Biochemical and Biophysical Research Communications, 361, 68–73.
23. Cao, X., Maloney, K. B., & Brusic, V. (2008). Data mining of cancer vaccine trials: A bird’s-eye view. Immunome Research, 4, 7.
24. Canlas Jr., R. D. (2009). Data mining in healthcare: Current applications and issues. Carnegie Mellon University.
25. Kalish, B. M. (2012). Digging for dollars: Data mining is an evolving tactic that can help reduce health care costs. Employee Benefit Adviser, 10, 36.
26. Shillabeer, A., & Roddick, J. (2007). Establishing a lineage for medical knowledge discovery. ACM International Conference Proceeding Series, 70, 29–37.
27. Mell, P., & Grance, T. (2010). The NIST definition of cloud computing. Communications of the ACM, 53(6), 50.
28. IBM. (2010). European Union consortium launches advanced cloud computing project with hospital and smart power grid provider. Accessed on July 29, 2016, from www-03.ibm.com/press/us/en/pressrelease/33067.wss.